验证码(公共全自动程序)
验证码(CAPTCHA)是“Completely Automated Public Turing test to tell Computers and Humans Apart”(全自动区分计算机和人类的图灵测试)的缩写,是一种区分用户是计算机还是人的公共全自动程序。可以防止:恶意破解密码、刷票、论坛灌水,有效防止某个黑客对某一个特定注册用户用特定程序暴力破解方式进行不断的登陆尝试,实际上用验证码是现在很多网站通行的方式,我们利用比较简易的方式实现了这个功能。这个问题可以由计算机生成并评判,但是必须只有人类才能解答。由于计算机无法解答CAPTCHA的问题,所以回答出问题的用户就可以被认为是人类。
验证码的来由:
最先想要解决这一问题的是雅虎——作为互联网时代早期最重要的免费邮件提供商,他们一方面要解决用户们每天遇到的数以百计的垃圾邮件轰炸,另一方面,他们自己的免费邮箱,恰恰又是垃圾邮件的最爱——耗费无数资源所阻止的垃圾邮件,都来自于自己的服务器。这让雅虎开始认真考虑如何解决人机辨识问题。
他们找到一位当时刚刚21岁的天才——Luis von Ahn。 而Luis Von Ahn给出的方案,就是这个让人民群众微微皱眉,但是让计算机耸肩挠头的验证码 Capcha。计算机辨识技术还很落后,对于经过扭曲、污染的文字,无法辨识。而人类却可以轻松认出这些文字。这是一个简单而巧妙的设计,计算机先是产生一个随机的字符串,然后用程序把这个字符串的图像进行随机的污染,扭曲,再显示给显示器前的人或者机器。凡是能够辨识这些字符的,即为人类。
作用
防止恶意破解密码、刷票、论坛灌水、刷页。有效防止某个黑客对某一个特定注册用户用特定程序暴力破解方式进行不断的登陆尝试,实际上是用验证码是现在很多网站通行的方式(比如招商银行的网上个人银行,腾讯的QQ社区),我们利用比较简易的方式实现了这个功能。虽然登陆麻烦一点,但是对网友的密码安全还来说这个功能还是很有必要,也很重要。验证码主要是运用于登录,注册,评论发帖等网站模块。
(1)登录模块:防止恶意程序采用暴力破解的方式进行不断的登录尝试,来破解用户的密码。
(2)注册模块:防止恶意程序进行大量的注册,占用网站服务器资源,发布垃圾消息导致网站崩溃。
(3)评论发帖模块:防止垃圾帖,广告贴刷屏,使论坛,博客等网站没有办法运行。
(4)其他:一些投票活动,抢购商品,抢票等地方也会使用到验证码,用来阻止刷票。
下面就来介绍下验证码的发展史:
1.随机的数字或者字母图片,这是最原始也是最简单的验证码,因为字体太正,容易被破解,现在基本已经被放弃;在当时的条件下,识别扭曲的图形,对于机器来说还是一个很艰难的任务,而对于人来说,则相对可以接受。
2.GIF格式的随机数字或者字母图片,是第一种的增强版,这种验证码因为一直在动,所以相对上一个效果上有了较大的提升;
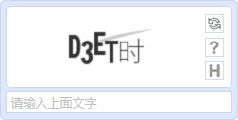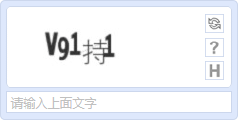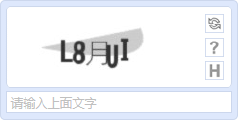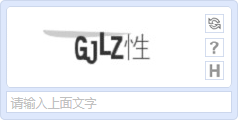
3.随机数字+随机大写英文字母+随机干扰像素+随机位置BMP格式图片,因为位置及干扰像素的影响,在初期对判断还是有些难度的,后来因为像素读取等技术,现如今的效果就不行了;
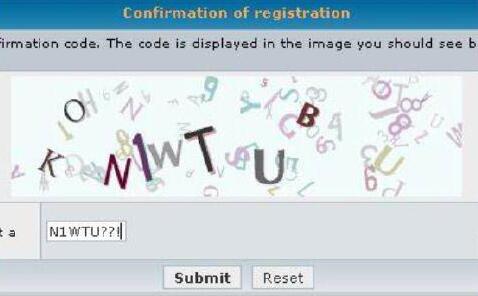
4.随机英文字母+随机颜色+随机位置+随机长度的JPG格式图片,对字母进行大小写,位置,颜色,长度等进行随机显示,但在像素读取技术下也甘拜下风;

5.广告验证码,输入广告中的高亮部分的内容即可,这个还是比较有创意的,随机的图片,随机的广告,随机的文字,对于品牌是个挺好的宣传手段,这种验证码形式基本抛弃了验证码本身的功能,因为其一些特性而变得极容易被“机器人”破解。根本不能保证网站的安全,唯一做的就是卡住用户,强迫其看一下广告;
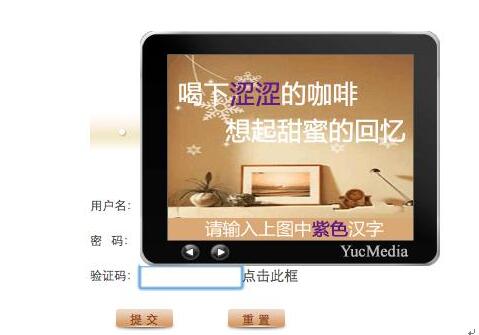
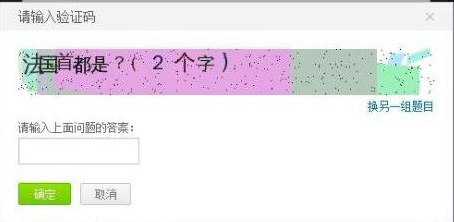
6.问题验证码,主要是以问答式的形式来进行填写,这是对之前单纯显示文字,字母,数字的难度提升,将原有的固定形式改为这种略带互动的形式,地理问题(如图),数学问题,常识问题等;
7.物品图片验证码,这个不多说,最出名的就是现在12306采用的防刷票措施了,据说今年的点击成功率只有8%,又有多少人因为验证码错误抢到没买到票啊~~;

8.手机短信验证码,通过发送验证码到手机,这也是针对真实用户做的调整,保证用户操作的真实性,缺点就是有信息泄漏的可能;
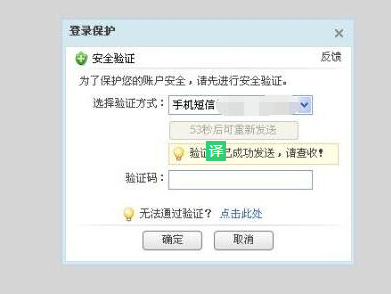
9.手机语音验证码验证码,这个就比较高级了,点击“获取语音验证码”,通过语音电话直接呼到用户手机,实现电话语音播报的方式,防止网站用户或会员用户经常因各种问题不能接收到网站发出的短信验证码,为网站带来用户,给网站管理者带来更轻松更高效的运营,也为用户带来更好的使用体验;
10.视频验证码,视频验证码中随机数字、字母和中文组合而成的验证码动态嵌入到MP4,flv等格式的视频中,增大了破解难度。简单来说,视频验证码就是以视频的形式显示验证码。将视频背景换做广告视频。以视频的形式完成验证码的功能,并且达到广告的效果。这样做远比在普通验证码上加广告好得多。首先视频本来就是视频验证码的必需品,而且验证码是动态的不会影响视频效果,而且不会降低视频验证码的安全性和其他特性。不会因为追求广告效果而丢掉了抗破解性。但由于需要较高的技术支持,此种验证码并未普及开。不过相信随着技术水平的提高,视频验证码会得到普及,网站的安全性会得到有效的提高。
11.新验证码时代
Google的nocaptcha vs 极验、阿里滑动验证码
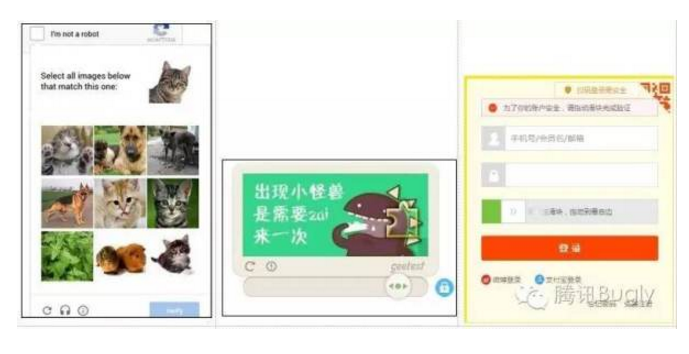
鹅厂从2013年开始尝试新型验证码,2013年的识图验证码。和12306验证码很像,当时的图片是设计师画的,最终因为图片资源难以满足自动机对抗要求的海量数量需求而暂时没推广。还有2014年第一版拼图验证码尝试。
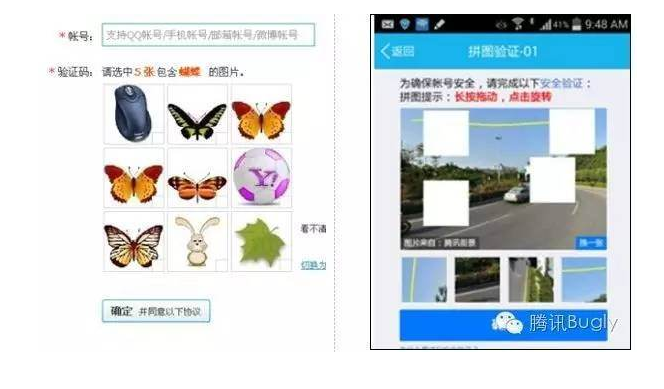
新时代验证码需要更大的舞台和更快的反应:摒弃了过去多年对字符的依赖,它可以快速支持和推广新型交互验证码。另外,用户在完成操作同时,前端会收集用户行为数据,通过机器学习,为线上策略输出更准确有效的策略。

基于当前登录帐号的历史数据提问
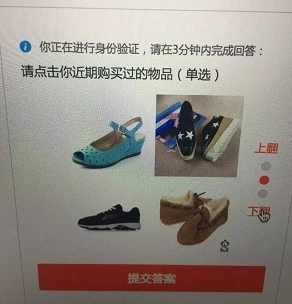
破解:
最常见的验证码主要有以下几种:
- 四位数字,随机的一数字字符串,最原始的验证码,验证作用几乎为零。
- 随机数字图片验证码。图片上的字符比较中规中矩,有的可能加入一些随机干扰素,还有一些是随机字符颜色,验证作用比上一个好。没有基本图形图像学知识的人,不可破!
- 各种图片格式的随机数字+随机大写英文字母+随机干扰像素+随机位置。
- 汉字是注册目前最新的验证码,随机生成,打起来更难了,影响用户体验,所以,一般应用的比较少。
为简单起见,破解说明主要针对是第2种类型的,先来看看网上常见的这种验证码的图片:

- 第一种,最容易,图片背景和数字都使用相同的颜色,字符规整,字符位置统一。
- 第二种,看似不容易,其实仔细研究会发现其规则,背景色和干扰素无论怎么变化,验证字符字符规整,颜色相同,所以排除干扰素非常容易,只要是非字符色素全部排除即可。
- 第三种,看似更复杂,处理上面提到背景色和干扰素一直变化外,验证字符的颜色也在变化,并且各个字符的颜色也各不相同。
- 第四种,除了第三个图片上提到的特征外,又在文字上加了两条直线干扰率,看似困难其实,很容易去掉。
验证码识别一般分为以下几个步骤:
- 取出字模 识别验证码,毕竟不是专业的OCR识别,并且,由于各个网站的验证码各不相同,所以,最常见的方法就是就是建立这个验证码的特征码库。去字模时,我们需要多下载几张图片,使这些图片中,包括所有的字符,我们这里的字母只有图片,所以,只要收集到包括0-9的图片即可。
- 二值化 二值化就是把图片上的验证数字上每个象素用一种数字表示1,其他部分用0表示。这样就可以计算出每个数字字模,记录下这些字模来,当作key即可。
- 计算特征 把要识别的图片,进行二值化,得到图片特征。
- 对照样本 把步骤3种的图片特征码和验证码的字模进行对比,得到验证图片上的数字。
使用目前这种方法,对验证码的识别基本上可以做到100%。
通过以上步骤,您可能说了,并没有发现如何取出干扰素啊!其实取出干扰素的方法很简单,干扰素的一个重要特征是,不能影响验证码的显示效果,所以制作干扰素时它的RGB可能低于或者高于某个特定值,比如我给的例子中的图片,干扰素的RGB各项值是不会超过125的,所以,这样我们就很容易去掉干扰素了。
简单的验证码只有数字和字母组成,格式统一,每次出现位置固定。下面继续深入研究识别验证码,这次需要识别的目标是:验证码有字符和数字组成,验证码存在旋转(可能左右都旋转),位置不固定,存在字符与字符之间的粘连,且验证码有更强的干扰素。
我们以下图为例进行讲解。

第一步:二值化。把验证码的部分用 1 表示,背景部分用 0 表示出来,识别方法很简单,我们打印出验证码整张图片的 RGB ,然后分析其规律即可,通过 RGB 码,我们很容易分辨出上面这张图片的 R 值大于 120 , G 和 B 的值小于 80 ,所以依据这个规则我们很容易把上面的图片二值化。
再来看看上面的第三种验证码图片

刚看上去,感觉很复杂。验证码的图片每次背景色都不相同,且不是单色,各个验证码数字的颜色每次也各不相同。貌似很难二值化,其实我们打印出其 RGB 值很容易就发现。无论验证数字颜色如何变化,该数字的 RGB 值总有一个值小于 125 ,所以通过如下判断 $rgbarray['red'] < 125 || $rgbarray['green']<125|| $rgbarray['blue'] < 125 我们就很容易分辨出哪里是数字,哪里是背景。
我们能够找到这些规律的原因是,在制作验证码的干扰素时,为了使干扰素不影响数字的显示效果,必须使用干扰素的 RGB 和数字 RGB 相互独立,互不干扰。只要懂得这个规律,我们就很容易实现二值化。
我们找到的 120 , 80 , 125 等阈值,可能和实际的 RGB 有出入,所以,有时二值化后,会有部分地方出现 1 ,对于验证码上固定位置显示数字,这种干扰没有太大意义。但是对于验证码位置不确定的图片来说,在我们切割字符时,很可能造成干扰。所以,在二值化后要进行去噪处理。
第二部:去噪处理。去噪的原理很简单,就是把孤立的有效的值去掉,如果噪点比较高,要求的效率也比较高的话,这里面也有很多工作要做。幸好这里我们不要求这么高深,我们使用最简单的方法就可以,如果一个点为 1 则判断这个点的上下左右上左上右下左下右 8 个方位上数字是否为 1 ,如果不为 1 ,就认为是一个燥点,直接设置为 1 即可。

如上图所示,我们使用此方法很容易发现红色方框部分的 1 为燥点,直接设置为 1 即可。在判断时我们使用了一个技巧,有时候的噪点可能是两个连续的 1 ,所以我们计算这个点的 8 个方向上的值之和,最后我们判断他们的和是否小于特定的阈值。
第三部:切割字符。切割字符的方法有很多种,这里采用最简单的一种,先垂直方向切割成为字符,然后在水平方向去掉多于的 0000 ,如下图

第一步切割红线部分,第二步切割蓝线部分,这样就可以得到独立的字符了。但是像下面这种情况

按上面的方法会把 dw 字符切割成一个字符,这是错误的切割,所以这里我们涉及到粘连字符的切割。
第四步:粘连字符切割。制作验证码时,规则字符的粘连很容易分割开,如果字符本身有缩放,变形就很难处理,经过分析,我们可以发现,上面的字符粘连属于很简单的方式,只是规则字符的粘连,所以处理这种情况,我们也使用很简单的处理方式。当完成分割操作后,我们不能马上确定分割的部分就为一个字符,要进行验证,验证的关键因素就是,切割下来的字符的宽是否大于阈值,这个阈值的取舍标准是,一个字符无论怎么旋转变形都不会大于这个阈值,所以,如果我们切割的块大于这个阈值,就可以认为这是一个粘连字符;如果大于两个阈值之和,就认为是三个字符粘连,以此类推。知道这个规则后,切割粘连字符也就很简单了。如果我们发现是粘连字符块,直接平分这个块为两个或者多个新的块就可以。当然为了更好的还原字符,我一般都采用平分 +1 , -1 对字符块的部分进行适当的补充。
第五步:匹配字符。对于旋转字符的特征码建立,有很多种方法,这里就不做深入研究了。我这里使用的最简单的方式,为所有字符的所有情况建立匹配库,所以在我提供的代码种增加了 study 操作,其目的就是,先有人手工识别图片的验证码,然后通过 study 方法,写入特征码库。这样写入的图片数据越多,验证识别的准确行也就越高。
经过以上步骤,我们基本上可以识别现在互联网上大部分的验证码,这里我们都是使用的最简单的方法,没有使用任何 OCR 知识。
另外制作验证码的一些建议:
对于识别验证码的程序来说,最难得部分是验证字符的切割和特征码的建立,而国内很多程序员只做验证码时,总是喜欢在验证码加很多干扰素,干扰线,影响效果不说,还达不到很好的效果;所以,要想使自己验证码难于本识别,只做下面两点就够了
- 字符粘连,最好所有的字符都有粘连的部分;
- 不要使用规格字符,验证码的各个部分使用不同比例的缩放或者旋转。
只要做到这两点,或者这两点的变形,识别程序就很难识别。
最后我找了几个验证码识别网站,都提供接口
1.https://www.juhe.cn/聚合数据
2.http://www.sxdama.com/石像网
3.http://www.dama2.com/打码兔
4.http://www.ruokuai.com/若快
5.http://www.zhima365.com/index1.php知码网