文章目录
一、MySQL复制
1.1 MySQL几个同步模式概念:
1、 异步复制(Asynchronous replication)
MySQL默认的复制即是异步的,主库在执行完客户端提交的事务后会立即将结果返给给客户端,不关心从库是否已经接收并处理,这样就会有一个问题,主如果crash掉了,此时主库上已经提交的事务可能并没有传到从库上,如果此时,强行将从库提升为主库,可能导致新主库上的数据不完整。
2、全同步复制(Fully synchronous replication)
指当主库执行完一个事务,所有的从库都执行了该事务才返回给客户端。因为需要等待所有从库执行完该事务才能返回,所以全同步复制的性能必然会收到严重的影响。
3、半同步复制(Semisynchronous replication)
一主多从模式下,有一个从节点返回成功,即成功,不必等待多个节点全部返回。介于异步复制和全同步复制之间,主库在执行完客户端提交的事务后不是立刻返回给客户端,而是等待至少一个从库接收到并写到relay log中才返回给客户端。相对于异步复制,半同步复制提高了数据的安全性,同时它也造成了一定程度的延迟,这个延迟最少是一个TCP/IP往返的时间。所以,半同步复制最好在低延时的网络中使用。
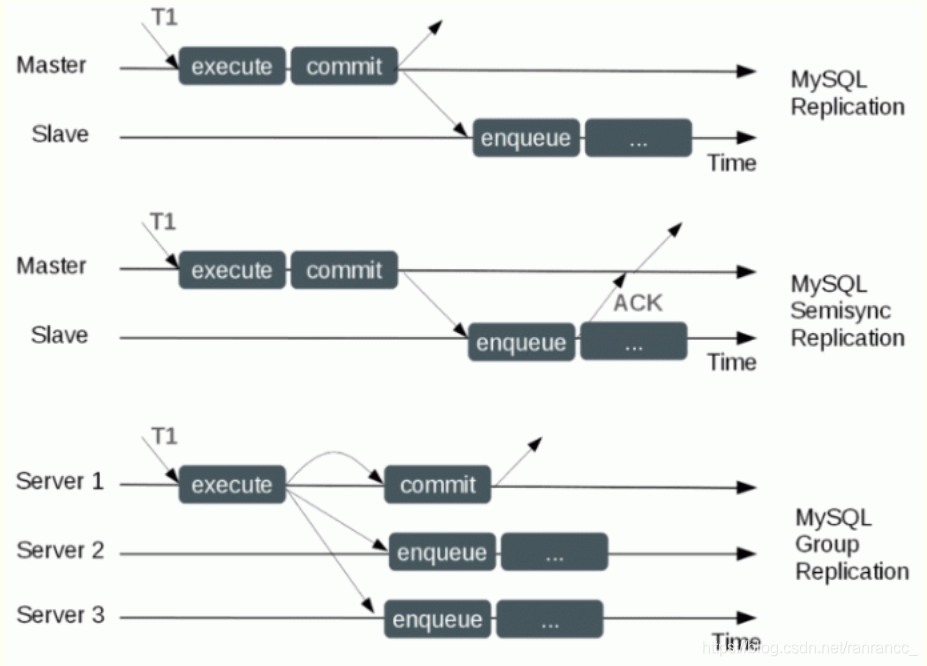
1.2 MySQL半同步复制技术
一般而言,普通的replication,即MySQL的异步复制,依靠MySQL二进制日志也即binary log进行数据复制。 比如两台机器,一台主机(master),另外一台是从机(slave)。
-
正常的复制为: 事务一(t1)写入binlog buffer;dumper线程通知slave有新的事务t1;binlog buffer进行checkpoint;slave的io线程接收到t1并写入到自己的的relay log;slave的sql线程写入到本地数据库。这时,master和slave都能看到这条新的事务,即使master挂了,slave可以提升为新的master。
扫描二维码关注公众号,回复: 8740608 查看本文章
-
异常的复制为: 事务一(t1)写入binlog buffer;dumper线程通知slave有新的事务t1;binlog
buffer进行checkpoint;slave因为网络不稳定,一直没有收到t1;master挂掉,slave提升为新的master,t1丢失。 -
很大的问题是: 主机和从机事务更新的不同步,就算是没有网络或者其他系统的异常,当业务并发上来时,slave因为要顺序执行master批量事务,导致很大的延迟。
为了弥补以上几种场景的不足,MySQL从5.5开始推出了半同步复制。相比异步复制,半同步复制提高了数据完整性,因为很明确知道,在一个事务提交成功之后,这个事务就至少会存在于两个地方。即在master的dumper线程通知slave后,增加了一个ack(消息确认),即是否成功收到t1的标志码,也就是dumper线程除了发送t1到slave,还承担了接收slave的ack工作。 如果出现异常,没有收到ack,那么将自动降级为普通的复制,直到异常修复后又会自动变为半同步复制。即表示MASTER 只需要接收到其中一台SLAVE的返回信息,就会commit;否则需等待直至达到超时时间然后切换成异步再提交。
1.3 半同步复制具体特性
主库产生binlog到主库的binlog file,传到从库中继日志,然后从库应用;也就是说传输是异步的,应用也是异步的。半同步复制指的是传输同步,应用还是异步的!
- 从库会在连接到主库时告诉主库,它是否配置了半同步。
- 如果半同步复制在主库端是开启了的,并且至少有一个半同步复制的从库节点,那么此时主库的事务线程在提交时会被阻塞并等待,结果有两种可能,要么至少一个从库节点通知它已经收到了所有这个事务的Binlog事件,要么一直等待直到超过配置的某一个时间点为止,而此时,半同步复制将自动关闭,转换为异步复制。
- 从库节点只有在接收到某一个事务的所有Binlog,将其写入并Flush到Relay Log文件之后,才会通知对应主库上面的等待线程。
- 如果在等待过程中,等待时间已经超过了配置的超时时间,没有任何一个从节点通知当前事务,那么此时主库会自动转换为异步复制,当至少一个半同步从节点赶上来时,主库便会自动转换为半同步方式的复制。
- 半同步复制必须是在主库和从库两端都开启时才行,否则主库默认使用异步方式复制。
二、半同步复制的配置
将插件安装在数据库中是临时的,退出重新登陆会失效,永久的可以将配置写在配置文件中
实验环境:基于异步复制的基础上
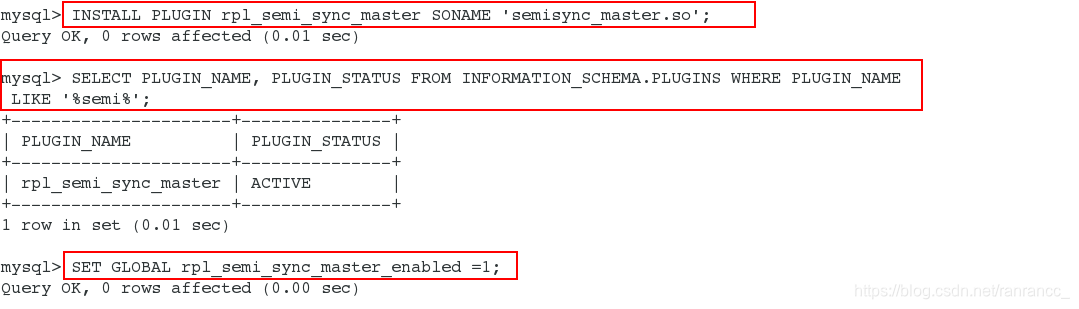
1、 在server1(master节点)上
1 | INSTALL PLUGIN rpl_semi_sync_master SONAME 'semisync_master.so'; 安装半同步模块
2 | SELECT PLUGIN_NAME, PLUGIN_STATUS
FROM INFORMATION_SCHEMA.PLUGINS
WHERE PLUGIN_NAME LIKE '%semi%'; 查看插件
3 | SET GLOBAL rpl_semi_sync_master_enabled = 1; 开启半同步,也就是激活插件
2、在server2(slave节点)上
1 | INSTALL PLUGIN rpl_semi_sync_slave SONAME 'semisync_slave.so'; 安装半同步插件
2 | SET GLOBAL rpl_semi_sync_slave_enabled =1; 激活插件
3 | STOP SLAVE IO_THREAD; 重启IO线程使半同步生效
4 | START SLAVE IO_THREAD;
- 从库重启io进程,激活插件之后必须要重启io进程,否则不会生效,如果重启不了的话就说明两端的数据不同步

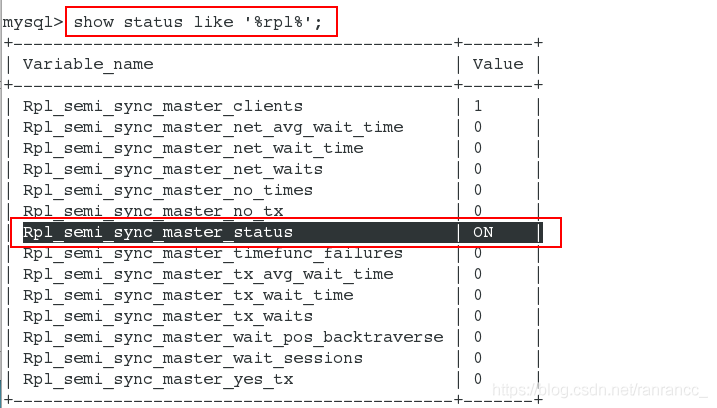
3、在server1(master节点)上,查看变量的状态和值:
mysql> show status like '%rpl%'; 查看变量的状态
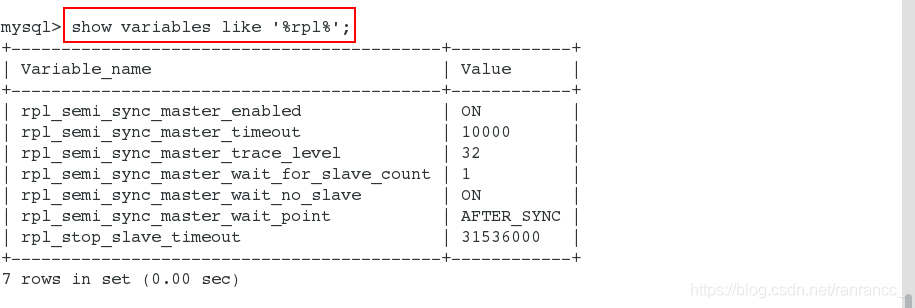
mysql> show variables like '%rpl%'; 查看变量的值
+-------------------------------------------+------------+
| Variable_name | Value |
+-------------------------------------------+------------+
| rpl_semi_sync_master_enabled | ON |
### 是否开启半同步
| rpl_semi_sync_master_timeout | 10000 |
###切换复制的timeout
| rpl_semi_sync_master_trace_level | 32 |
###用于开启半同步复制模式时的调试级别,默认是32
| rpl_semi_sync_master_wait_for_slave_count | 1 |
###至少有N个slave接收到日志
| rpl_semi_sync_master_wait_no_slave | ON |
###是否允许master 每个事物提交后都要等待slave的receipt信号。默认为on
| rpl_semi_sync_master_wait_point | AFTER_SYNC |
###等待的point
| rpl_stop_slave_timeout | 31536000 |
+-------------------------------------------+------------+
###控制stop slave 的执行时间,在重放一个大的事务的时候,突然执行stop slave,命令
###stop slave会执行很久,这个时候可能产生死锁或阻塞,严重影响性能
4、在slave节点上,
mysql> show variables like '%rpl%'; 查看变量的值

5、测试:
1)server2关闭io进程:STOP SLAVE IO_THREAD;
2)在server1上,
use ranran;
insert into usertb values ('user00','123');
主库等待10s,当10s后没有接收到slave的ack请求,主库就自动转换为异步复制。

查看半同步状态也是off,待同步的事务也是1
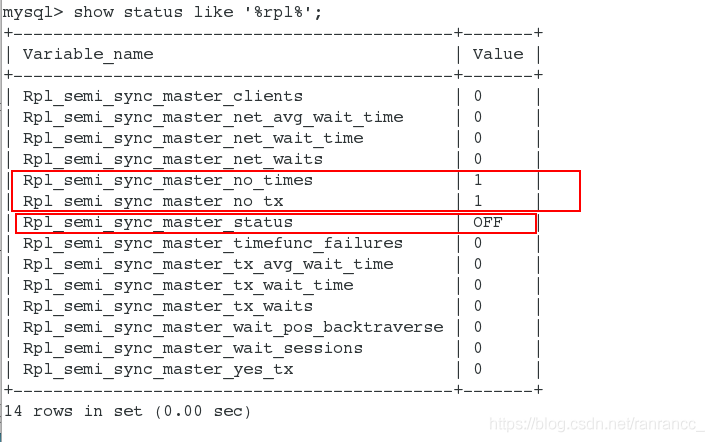
有10秒的延迟,这是因为从库的io进程关闭了,不能及时的写入数据;主库等待10秒之后从库还没有起来,主库不再等待直接写入
3)再次插入数据,发现特别快,此时已经变成异步了,主库切换为异步后就不再关心从库了。

4)server2开启io进程:START SLAVE IO_THREAD;
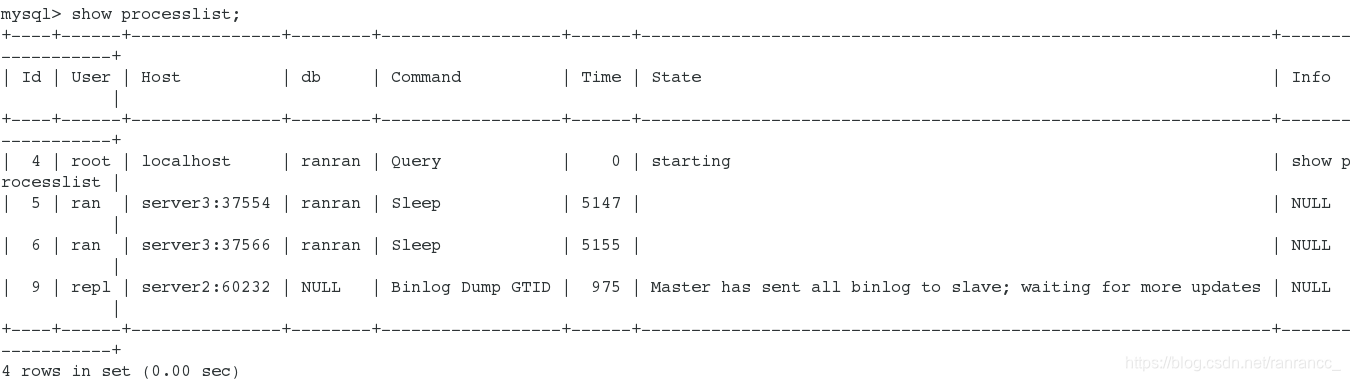
5)输出结果显示了有哪些线程在运行:show processlist;
id列:一个标识
user列: 显示当前用户,如果不是root,这个命令就只显示你权限范围内的sql语句
host列:显示这个语句是从哪个ip 的哪个端口上发出的。可用来追踪出问题语句的用户
db列:显示这个进程目前连接的是哪个数据库
command列:显示当前连接的执行的命令,一般就是休眠(sleep),查询(query),连接(connect)
time列:此这个状态持续的时间,单位是秒
state列:显示使用当前连接的sql语句的状态
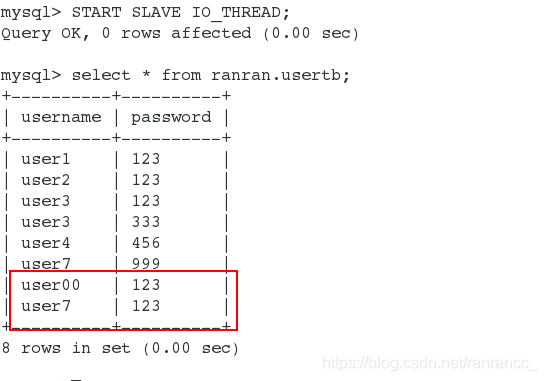
6)查看表信息,已经复制过来,只要从库的io进程恢复工作就会立即同步没有同步的数据
三、全同步复制(组复制)
1、全同步复制(组复制)的基本概念
- 组复制模型:
它支持单主模型和多主模型两种工作方式(默认是单主模型)
单主模型: 从复制组中众多个MySQL节点中自动选举一个master节点,只有master节点可以写,其他节点自动设置为read only。当master节点故障时,会自动选举一个新的master节点,选举成功后,它将设置为可写,其他slave将指向这个新的master。
多主模型: 复制组中的任何一个节点都可以写,因此没有master和slave的概念,只要突然故障的节点数量不太多,这个多主模型就能继续可用 - 组复制原理:
组复制由多个 server成员构成,并且组中的每个 server 成员可以独立地执行事务,但所有读写(RW)事务只有在冲突检测成功后才会提交。只读(RO)事务不需要在冲突检测,可以立即提交。
2、配置组复制
实验环境
| 主机名 | IP | 功能 |
|---|---|---|
| server1 | 172.25.7.1 | master节点 |
| server2 | 172.25.7.2 | slave节点 |
| server3 | 172.25.7.3 | slave节点 |
在server1上
1、关闭mysqld :systemctl stop mysqld
2、查看UUID:cat /var/lib/mysql/auto.cnf
3、删除mysql数据:rm -fr /var/lib/mysql/*
- 注意:删除数据之前先复制uuid,三个节点的uuid使用同一个值,而且不能与三个节点自身的uuid相同

4、修改配置文件 vim /etc/my.cnf
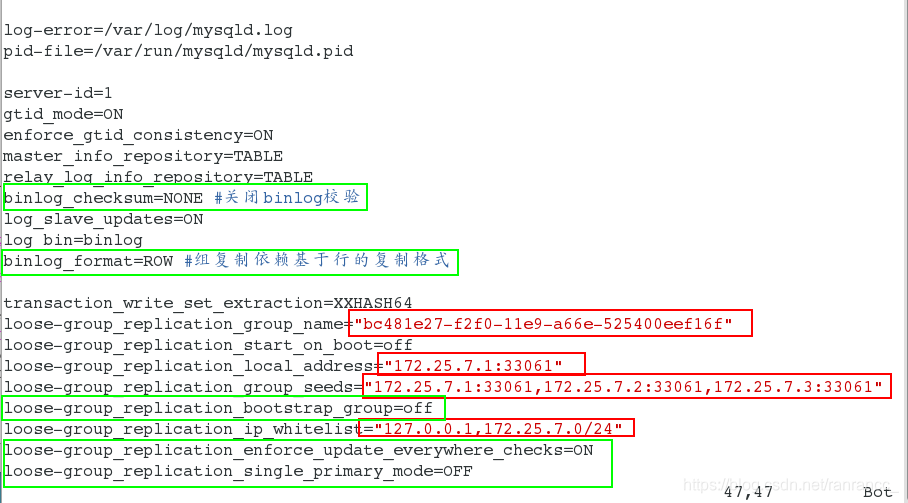
- binlog_checksum=NONE :关闭binlog校验
- binlog_format=ROW :组复制依赖基于行的复制格式
- loose-group_replication_bootstrap_group=off :插件是否自动引导,这个选项一般都要off掉,只需要由发起组复制的节点开启,并只启动一次,如果是on,下次再启动时,会生成一个同名的组,可能会发生脑裂
- 开启多主模式的参数
loose-group_replication_enforce_update_everywhere_checks=ON
loose-group_replication_single_primary_mode=OFF
5、 开启数据库 systemctl start mysqld ,再次安全初始化:mysql_secure_installation。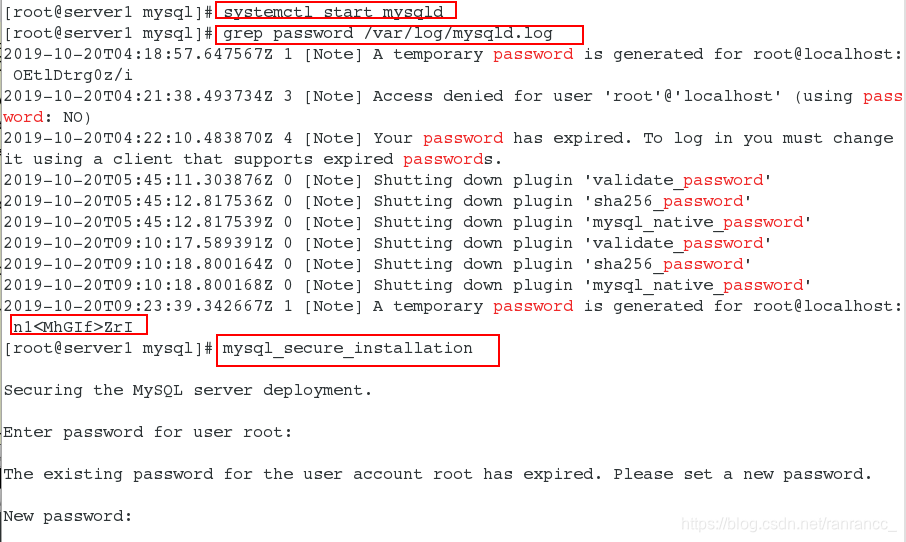
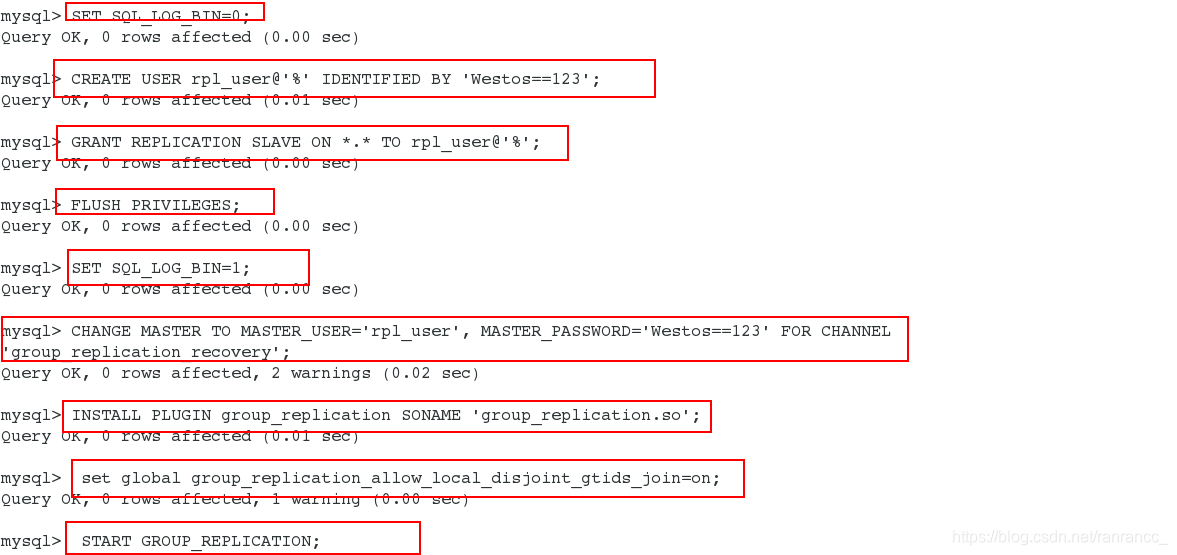
6、登录数据库并配置组复制
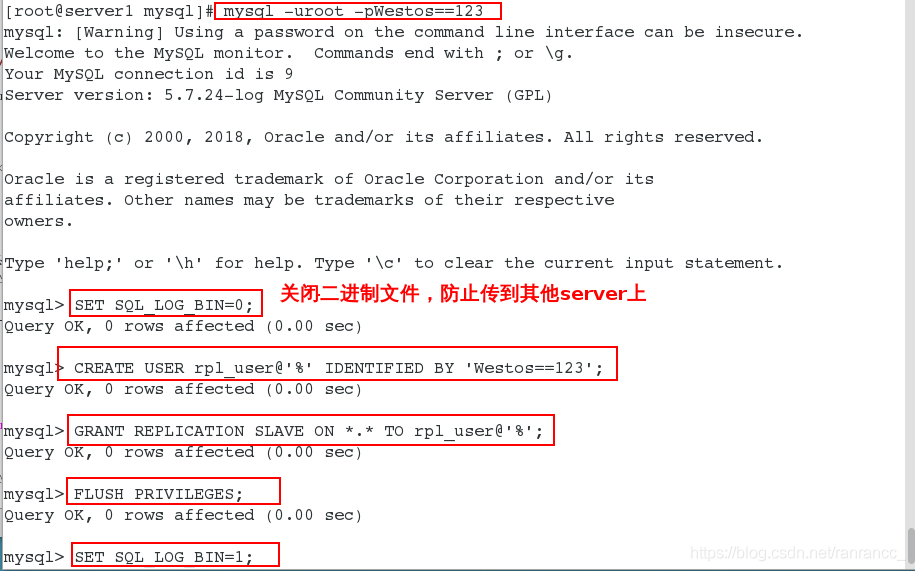
mysql> SET SQL_LOG_BIN=0;
##关闭二进制日志
mysql> CREATE USER rpl_user@'%' IDENTIFIED BY 'Westos==123';
##创建用户
mysql> GRANT REPLICATION SLAVE ON *.* TO rpl_user@'%';
##用户授权
mysql> FLUSH PRIVILEGES;
##刷新用户授权表
mysql> SET SQL_LOG_BIN=1;
##开启二进制日志
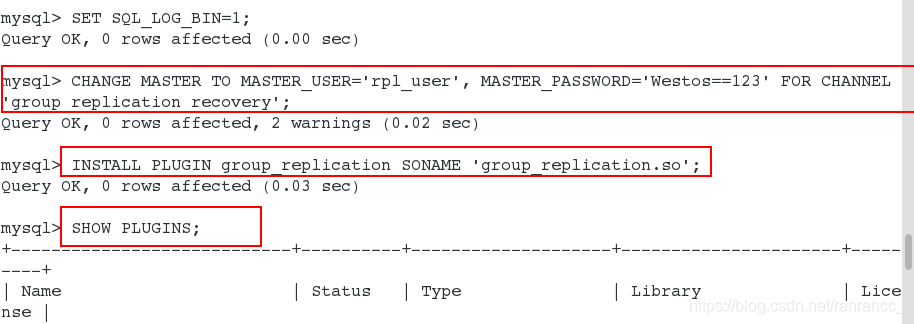
mysql> CHANGE MASTER TO MASTER_USER='rpl_user',
MASTER_PASSWORD='Westos==123',
FOR CHANNEL 'group_replication_recovery';
##配置用户
mysql> INSTALL PLUGIN group_replication SONAME 'group_replication.so';
##安装组复制插件
mysql> SET GLOBAL group_replication_bootstrap_group=ON;
##在第一个节点上要先打开一次
mysql> START GROUP_REPLICATION;
##开启组复制
mysql> SET GLOBAL group_replication_bootstrap_group=OFF;
##关闭组复制激活
mysql> SELECT * FROM performance_schema.replication_group_members;
##查看当前组的状态,是否为online



在server2和server3上配置
7、关闭mysql服务: systemctl stop mysqld
8、删除数据目录的内容:rm -fr /var/lib/mysql/*
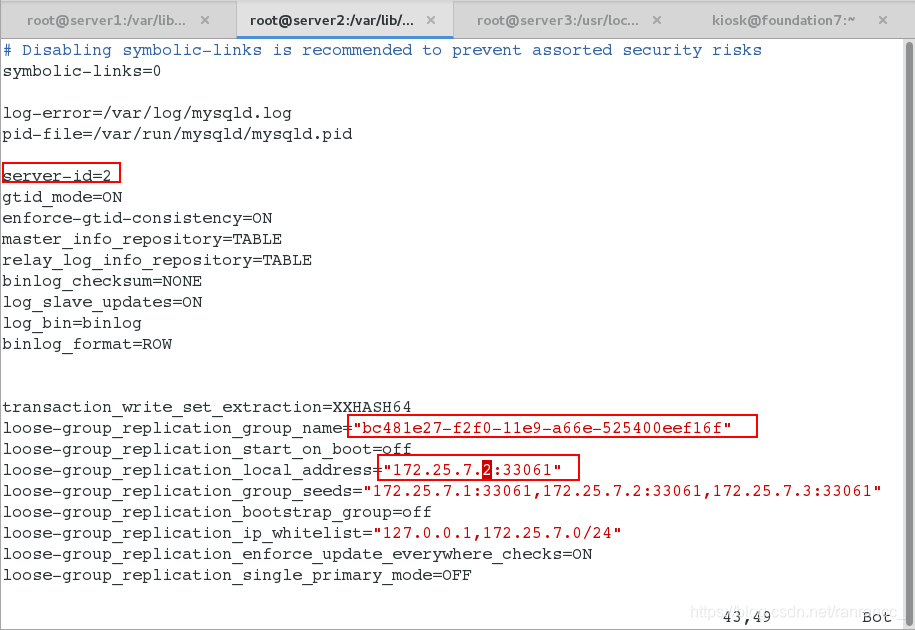
9、编辑配置文件vim /etc/my.cnf,重启服务systemctl start mysqld
- 仅更改server-id和loose-group_replication_local_address

10、查看临时密码 grep password /var/log/mysqld.log,安全初始化mysql_secure_installation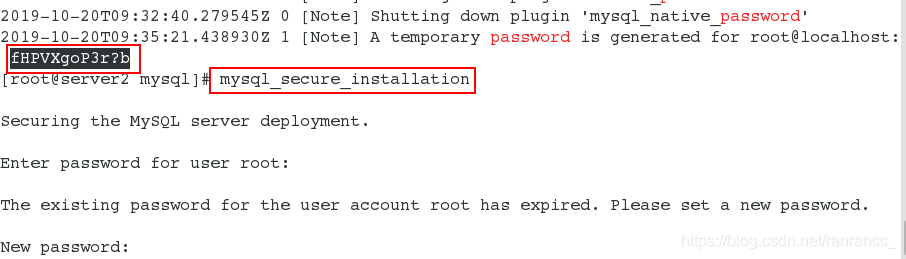
11、登录数据库:mysql -uroot -pWestos==123
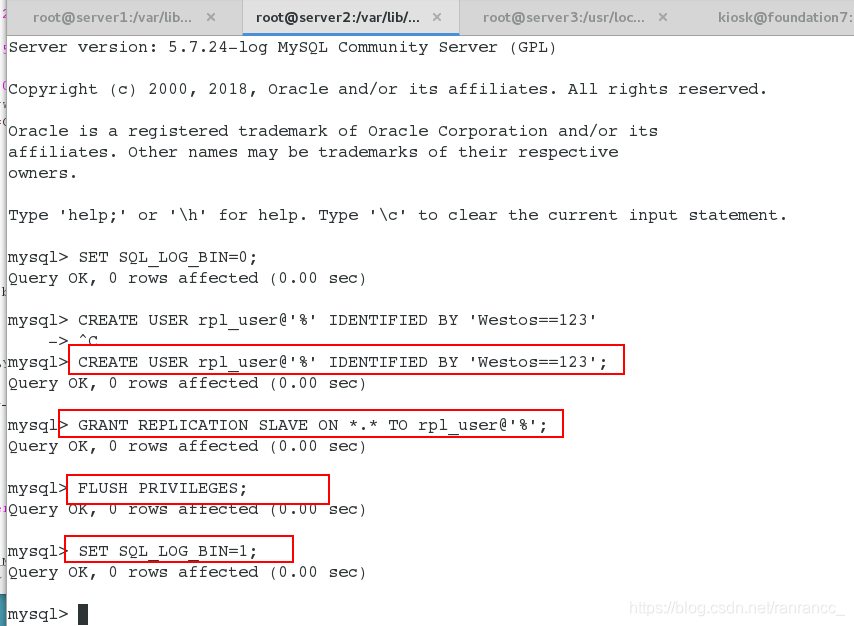
CREATE USER rpl_user@'%' IDENTIFIED BY 'Westos==123';
GRANT REPLICATION SLAVE ON *.* TO rpl_user@'%';
FLUSH PRIVILEGES;
SET SQL_LOG_BIN=1;
CHANGE MASTER TO MASTER_USER='rpl_user', MASTER_PASSWORD='Yan+123kou' FOR CHANNEL 'group_replication_recovery';
INSTALL PLUGIN group_replication SONAME 'group_replication.so';
START GROUP_REPLICATION;
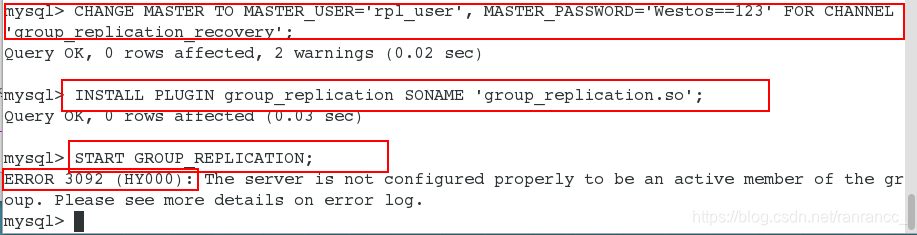
此时开启组复制,发现有报错,查看日志:cat /var/log/mysqld.log

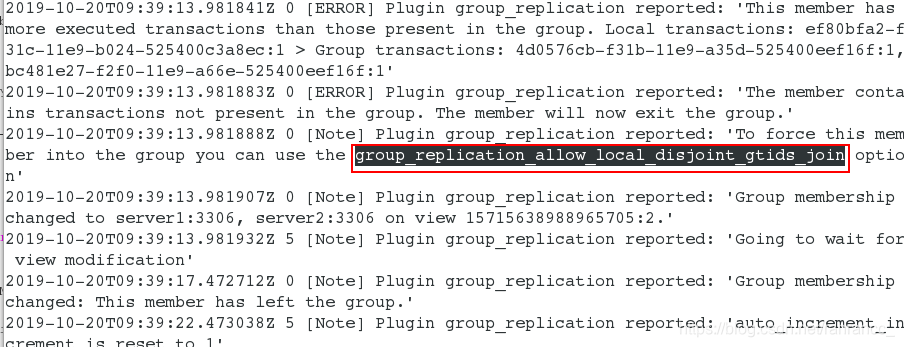
12、再次登录数据库,
STOP GROUP_REPLICATION;
set global group_replication_allow_local_disjoint_gtids_join=on;
START GROUP_REPLICATION;

13、配置好后 在server1上 查看,
SELECT * FROM performance_schema.replication_group_members;

14、同样在server3上修改配置文件


14、配置好server2和server3后 在server1上 查看,
SELECT * FROM performance_schema.replication_group_members;
看到3台都是online,表示正常,此时在任何一个节点写入数据,其他节点都可以看到。

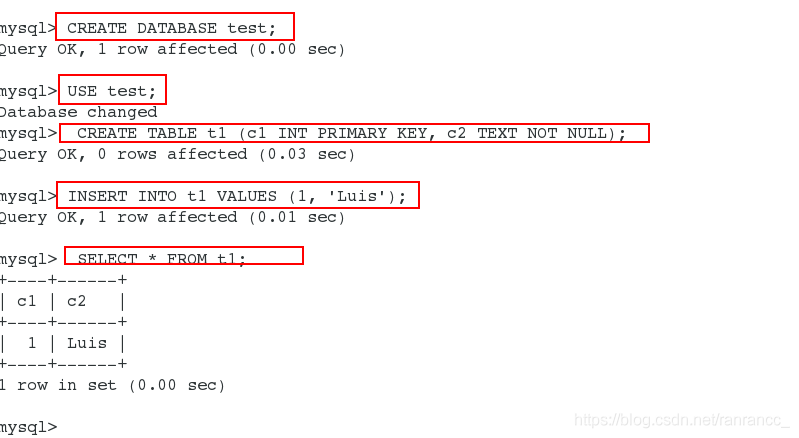
15、测试
在server1上插入数据:
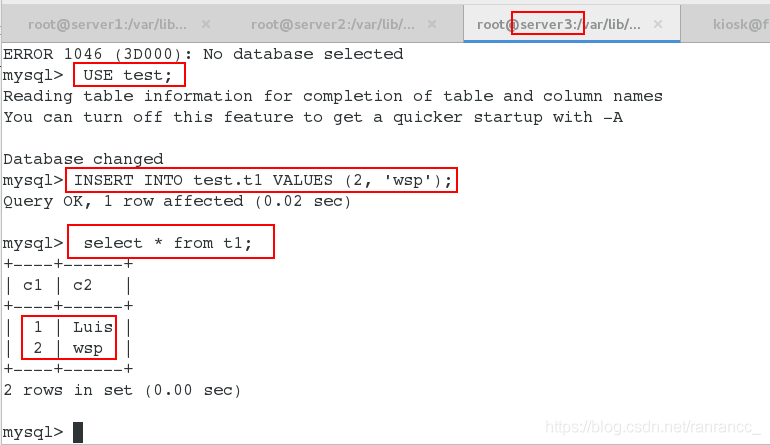
在server3可以看到server1上插入的数据,且也可以插入数据。
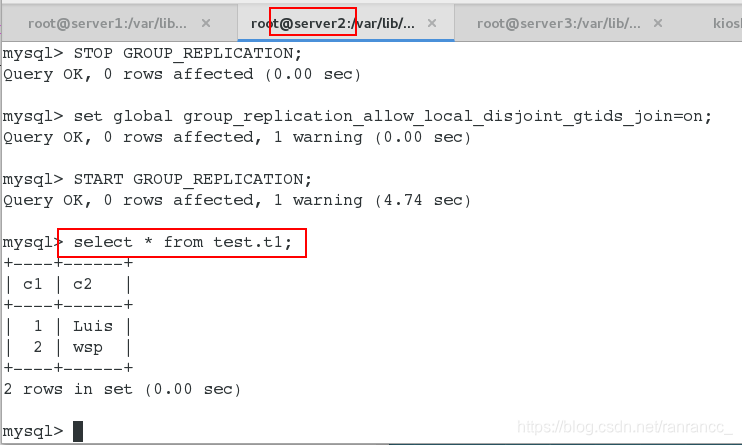
可以看到,已经实现了组复制,在任意一个节点写数据,其他两个节点会进行组复制
