##什么是级联 什么是级联? 简单的说,没有配置级联的时候,删除分类,其对应的产品不会被删除。 但是如果配置了恰当的级联,那么删除分类的时候,其对应的产品都会被删除掉。
包括上一步说的删除用得级联,级联有4种类型: all:所有操作都执行级联操作; none:所有操作都不执行级联操作; delete:删除时执行级联操作; save-update:保存和更新时执行级联操作; 级联通常用在one-many和many-to-many上,几乎不用在many-one上。
##一级缓存 hibernate默认是开启一级缓存的,一级缓存存放在session上 就是 第一次通过id=1获取对象的时候,session中是没有对应缓存对象的,第二次通过id=1获取对象时,session中有对应的缓存对象
##二级缓存 Hibernate的一级缓存是在Session上,二级缓存是在SessionFactory上 正常来说 不同Session的话,是没有缓存相关的
在hibernate.cfg.xml中开启二级缓存的配置 hibernate本身不提供二级缓存,都是使用第三方的二级缓存插件 这里使用的是 EhCache提供的二级缓存
在src目录下,创建一个ehcache.xml用于EHCache的缓存配置
设置HBM 对于要进行二级缓存的实体类,进行配置,增加
###测试效果 使用不同的session,都去获取id=1的category,只会访问一次数据库。因为第二次获取虽然没有从第二个session中拿到缓存,但是从sessionfactory中拿到了Category缓存对象
##分页 Hibernate使用Criteria 来进行分页查询
Criteria c = s.createCriteria(Product.class);
c.add(Restrictions.like("name", "%"+name+"%"));
c.setFirstResult(0); // (表示从第2条数据开始)第2条之后 ,注意是基于0开始的
c.setMaxResults(5); //表示一共查询5条数据
###对于id不存在的对象的处理
get(立刻加载)是立刻会使用查询语句去数据库里查找 而load(延迟加载) 要等你用到它对象里面的属性 他才会使用查询语句去数据库里查找
- get方式会返回null
- load方式会抛出异常
###Hibernate有两种方式获得session,分别是: openSession和getCurrentSession

他们的区别在于
- 获取的是否是同一个session对象 openSession每次都会得到一个新的Session对象 getCurrentSession在同一个线程中,每次都是获取相同的Session对象,但是在不同的线程中获取的是不同的Session对象
- 事务提交的必要性 openSession只有在增加,删除,修改的时候需要事务,查询时不需要的 getCurrentSession是所有操作都必须放在事务中进行,并且提交事务后,session就自动关闭,不能够再进行关闭
###openSession查询时候不需要事务 如果是做增加,修改,删除是必须放在事务里进行的。 但是如果是查询或者get,那么对于openSession而言就不需要放在事务中进行
###getCurrentSession ,它提交完事务后,session会自动关闭,而openSession 还要自己手动关 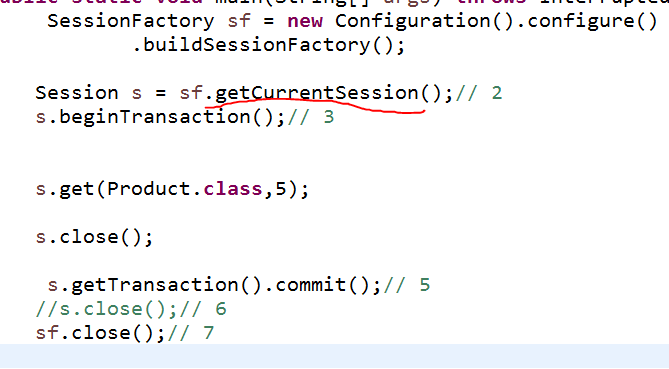
###未解之谜 openSession,的查询和get都是不需要放在事务中进行的,而为什么getCurrentSession的查询和get也要放在事务中呢?这么设计的初衷是什么 ?
##N+1 Hibernate有缓存机制,可以通过用id作为key把product对象保存在缓存中
同时hibernate也提供Query的查询方式。假设数据库中有100条记录,其中有30条记录在缓存中,但是使用Query的list方法,就会所有的100条数据都从数据库中查询,而无视这30条缓存中的记录
Hibernate使用Iterator实现N 1 N+1是什么意思呢,首先执行一条sql语句,去查询这100条记录,但是,只返回这100条记录的ID 然后再根据id,进行进一步查询。 N+1中的1,就是指只返回id的SQL语句,N指的是如果在缓存中找不到对应的数据,就到数据库中去查
另外的理解:** query 的list()和iterator()区别**
区别:
1.返回的类型不一样,list返回List,iterate返回iterator.
2.查询策略不同。(获取数据的方式不一样,list会直接查询数据库,iterate会先到数据库中获取id,然后真正遍历某个对象引用的时候,先到缓存中找,如果找不到,以id为条件再发一条sql到数据库,这样如果缓存中没有数据,则查询数据库的次数为n+1).
3.list中返回的list中每个对象都是其本身的对象,iterate中返回的对象是代理对象.
4.list只能put不能获取,iterate可以进行获取.
================================================

看代码的描述, 意思是这句圈红的代码其实包含了选择: ①如果这个对象在缓存中,就直接从缓存中取了 ②否则就从数据库中获取 虽然这个选择没有在代码层面上体现出来, 但是我们用Iterator而不是list的时候就已经在底层会自动实现了是吗= =我感觉是这样的
##查询总数 根据SQL语句创建一个Query对象,调用Query对象的uniqueResult()方法,返回一个long型的数据,即查询总数。

##乐观锁 Hibernate使用乐观锁来处理脏数据问题(就是同步问题)
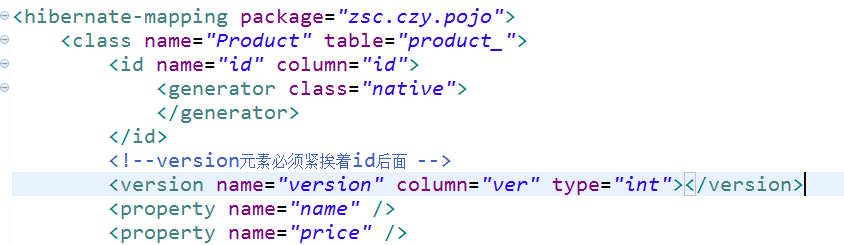
乐观锁步骤 1:修改配置文件 Product.hbm.xml 增加一个version字段,用于版本信息控制。这就是乐观锁的核心机制。
比如session1获取product1的时候,version=1。 那么session1更新product1的时候,就需要确保version还是1才可以进行更新,并且更新结束后,把version改为2。 个人理解:这个version是确保别的session是否对数据修改了,因为一旦修改后,他version就会变成2 注意: version元素必须紧跟着id后面,否则会出错。
2:修改 Product.java 增加version成员属性
3:重新运行刚刚一样的代码 做同样的业务就会抛出异常,提示该行已经被其他事务删除或者修改过了,本次修改无法生效。 这样就保证了数据的一致性。
StaleObjectStateException: Row was updated or deleted by another transaction (or unsaved-value mapping was incorrect): [zsc.czy.pojo.Product#3]
###原理
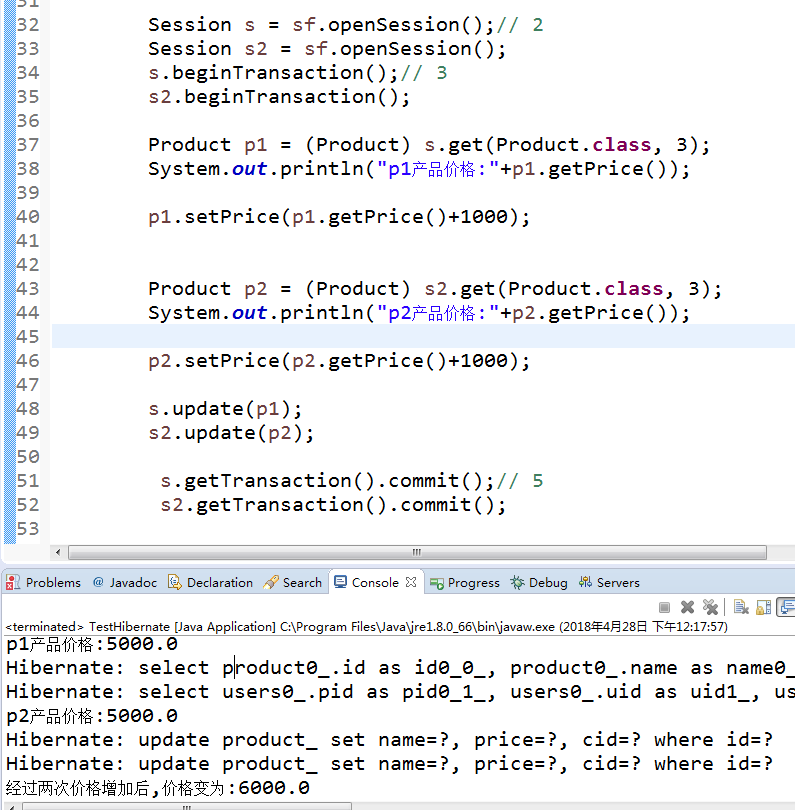
- 假设数据库中产品的价格是10000,version是10
- session1,session2分别获取了该对象
- 都修改了对象的价格
- session1试图保存到数据库,检测version依旧=10,成功保存,并把version修改为11
- session2试图保存到数据库,检测version=11,说明该数据已经被其他人动过了。 保存失败,抛出异常
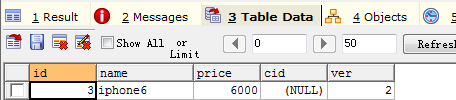 发现mysql 表里多了个version 的字段,而且你每update一次,它的version都会增加一, 所以上面只有前一个session能成功更新 增加1000元,而后面那个session增加1000失败,所以最终由原价5000变成6000
发现mysql 表里多了个version 的字段,而且你每update一次,它的version都会增加一, 所以上面只有前一个session能成功更新 增加1000元,而后面那个session增加1000失败,所以最终由原价5000变成6000

个人理解:一开始session从数据库取查数据对象时会检测一次当前version是多少, session最后试图保存进数据库时,会再次自动检测当前的version是多少 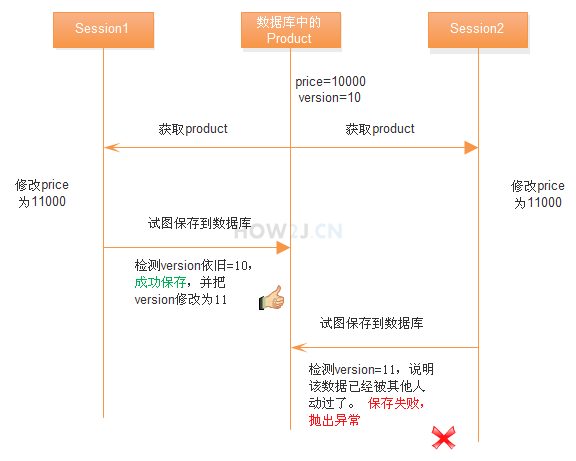
##C3P0连接池 建立数据库连接时比较消耗时间的,所以通常都会采用数据库连接池的技术来建立多条数据库连接,并且在将来持续使用,从而节约掉建立数据库连接的时间 hibernate本身是提供了数据库连接池的,但是hibernate官网也不推荐使用他自带的数据库连接池。 一般都会使用第三方的数据库连接池 C3P0是免费的第三方的数据库连接池,并且有不错的表现
1:导入专用的jar包 2:进行c3p0连接池的配置 ---hibernate.cfg.xml
<property name="hibernate.connection.provider_class">
org.hibernate.connection.C3P0ConnectionProvider
</property>
<property name="hibernate.c3p0.max_size">20</property>
<property name="hibernate.c3p0.min_size">5</property>
<property name="hibernate.c3p0.timeout">50000</property>
<property name="hibernate.c3p0.max_statements">100</property>
<property name="hibernate.c3p0.idle_test_period">3000</property>
<!-- 当连接池耗尽并接到获得连接的请求,则新增加连接的数量 -->
<property name="hibernate.c3p0.acquire_increment">2</property>
<!-- 是否验证,检查连接 -->
<property name="hibernate.c3p0.validate">false</property>
3:记得要把的二级缓存的相关配置去掉
<!-- <cache usage="read-only" />-->
测试 注:当运行次数不大的时候,从运行效果上来看,是看不出区别的。 只有在高并发量的情况下,才会体会出来。本知识主要是提供这个相关配置办法,以供以后有需要的时候,查询与修改方便。 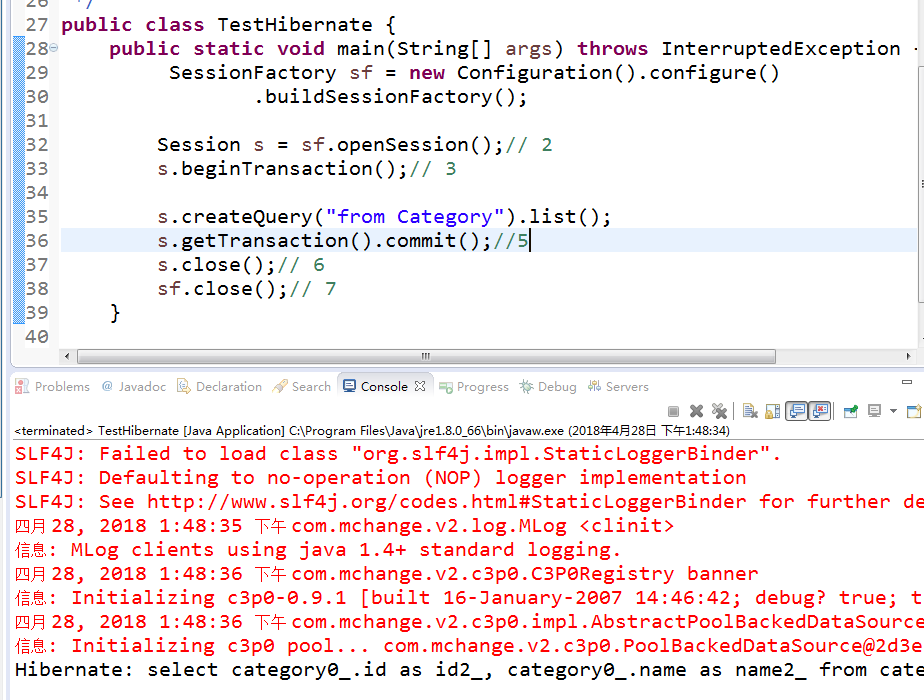
##注解 Hibernate的注解是什么? 简单的说,本来放在hbm.xml文件里的映射信息,现在不用配置文件做了,改由注解来完成
个人理解:目的是直接可以省去 写Product.hbm.xml 这一个个实体类与表 的映射。用直接在实体类里面写注解来 完成对表的映射
##hibernate 注解分类 hibernate里常用注解包括,类注解,属性注解,关系注解,其他的注解
###类注解 
###属性注解 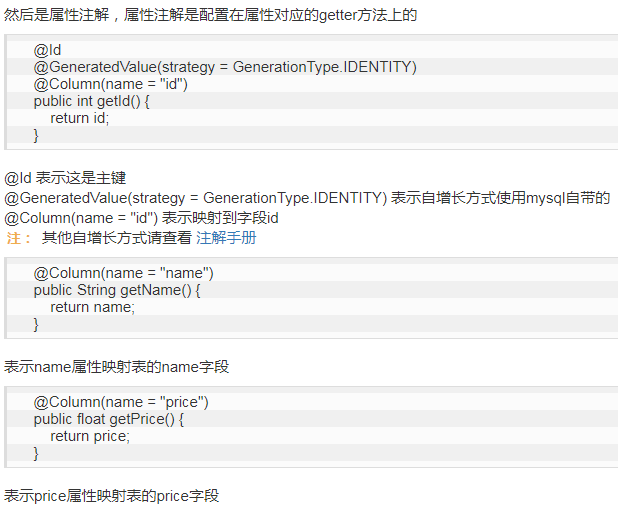
###关系 多对一注解 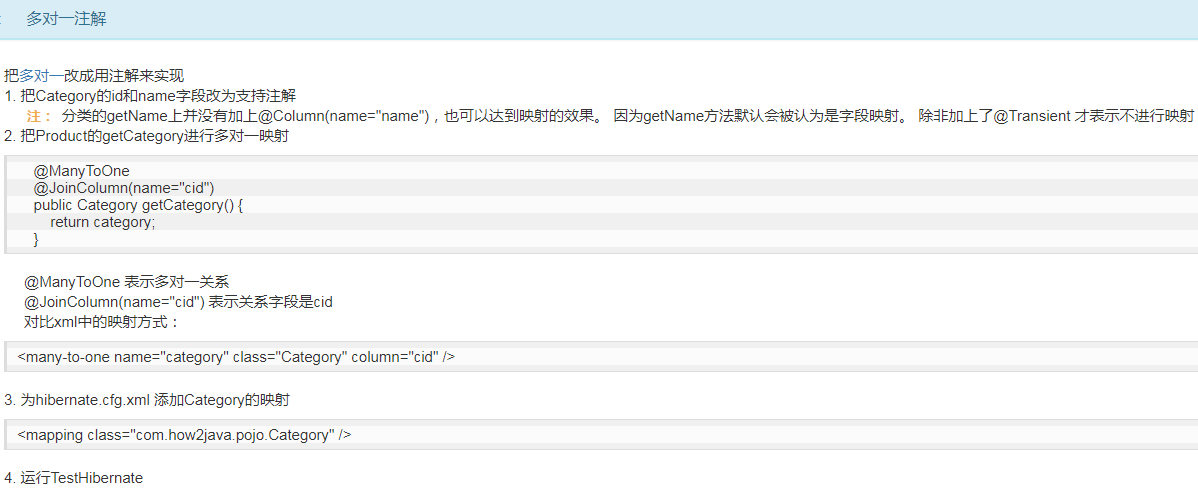
@ManyToOne
@JoinColumn(name="cid")
public Category getCategory() {
return category;
}
###个人理解: ** , Product 类是 多,而Product 里面的Category 就是一, 多对一。 Category映射着自己product_ 表里面的cid字段** 一对多 ,或多对一 ,@JoinColumn(name="cid") ,一般这个cid字段都是存在多的那一方的表里
###一对多注解 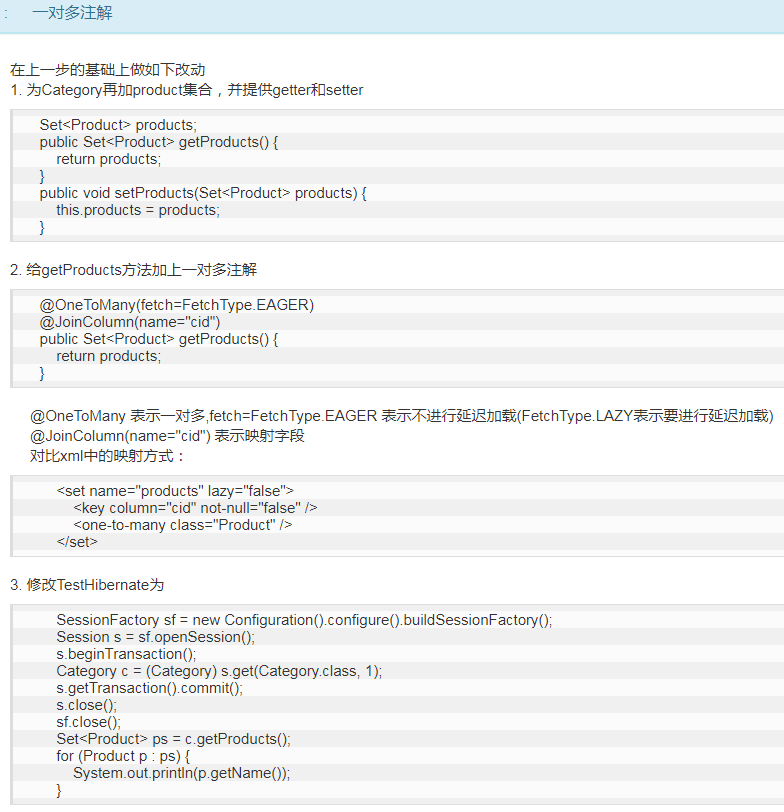
###多对多注解 

个人理解: User类里的getProducts映射的是 name="user_product",在user_produc表里的uid 对着pid Product类getUsers映射的也是user_product ,在user_produc表里pid对着uid。
##关系相关注解查询手册 
##注解VS XML配置 那么到底该用注解,还是xml文件配置方式呢? 他们各自有各自的优缺点:
XML配置方式:
优:容易编辑,配置比较集中,方便修改,在大业务量的系统里面,通过xml配置会方便后人理解整个系统的架构,修改之后直接重启应用即可
缺:比较繁琐,配置形态丑陋, 配置文件过多的时候难以管理
注解方式:
优:方便,简洁,配置信息和 Java 代码放在一起,有助于增强程序的内聚性。
缺:分散到各个class文件中,所以不宜维护, 修改之后你需要重新打包,发布,重启应用。
个人体会: 小项目,参与人数不多,不复杂的用注解,开发快速。 复杂项目,多人交互,配置量大,维护复杂度高的,用配置文件。