Python数据类型之有序列数据类型
序列数据类型可进行for遍历的数据类型,同时,
有序序列数据类型,也就是说,该数据类型还可进行索引;切片;使用连接操作符、重复操作符以及成员操作符。
以列表和集合为例:列表作为有序数据数列如果为其追加元素,那么,追加的元素势必在列表的最右边;而集合作为无序数列,添加的元素不一定会在集合的最右边。
>>> a = [99, 12, 1,88]
>>> a.append(0)
>>> a
[99, 12, 1, 88, 0]
>>> b = {99, 12, 1, 88}
>>> b.add(0)
>>> b
{0, 1, 99, 12, 88}
1. 字符串
1. 1 字符串基本特性
- 连接操作符和重复操作符
连接操作符: 从原有字符串获得一个新的字符串,
重复操作符: 创建一个包含了原有字符串的多个拷贝的新串,示例如下:
>>> a = "Hello"
>>> b = "World"
>>> a + b # 连接操作
'HelloWorld'
>>> a * 10 #重复操作
'hellohellohellohellohellohellohellohellohellohello'
- 支持索引(s[i] )和切片(s[i: j]): 获取特定偏移的元素。索引的分类包括: 正向索引和反向索引。图解分析以及代码示例如下所示:
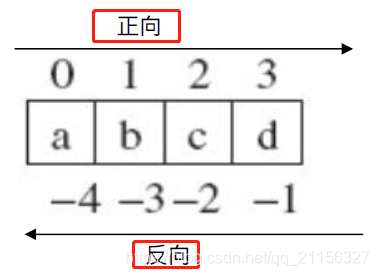
>>> s = 'abcd'
>>> s[0] # 索引操作示例
'a'
>>> s[3]
'd'
>>> s[-1]
'd'
>>> s[-4]
'a'
>>> s = 'abcdefgh' # 切片操作示例
>>> s[1:5] # 从第一个索引开始到第四个索引结束
'bcde' # 遵循“左闭右开”原则
>>> s[:5] # 如果没有给定开始的索引, 默认从头开始
'abcde' # 【理解】:拿出前n个字符/元素, s[:n]
>>> s[1:] # 从第一个索引开始到结束, 除了第一个元素之外的其他元素统统显示
'bcdefgh' # 【理解】:拿出除了前 n个字符/元素, s[n:]
>>> s[::2] # 隔一个拿一个
'aceg'
>>> s[1::2]
'bdfh'
>>> s[:]
'abcdefgh'
>>> s[::-1] # 【反转字符串】
'hgfedcba'
切片操作小结:
- 切片S[i: j]会提取对应的部分作为一个序列;
- 如果没有给出切片的边界,切片的下边界默认为0,上边界为字符串的长度;
- 扩展的切片S[i: j: k],其中i, j含义同上,k 为递增步长;
- s[:] 获取从偏移量为0到末尾之间的元素,是实现
有效拷贝的一种方法; - s[::-1]是实现
字符串反转的一种方法。
- 成员操作符(in ,not in),成员操作符用于判断一个字符或者一个子串(中的字符)是否出现在另一个字符串中,出现则返回 True,否则返回 False。示例如下:
>>> a = "abcdef"
>>> "c" in a
True
>>> "a" not in a
False
1. 2 字符串的内建方法
Python中关于字符串的内建方法分类,如下图所示:
- 内建方法之字符串的类型(组成)判断方法
- isalunm,是否是全为字母或数字的
- isalpha, 是否是全为字母
- isdigit,是否是全为数字
- islower,是否全为小写字母组成的
- isspace,是否全为空格,指广义空格。eg:\n, \t
- istitle,是否为标题格式的(每个首字母大写),eg:Hello World
- isupper,是否全为大写字母的
- isdecimal,是否为十进制字符组成的
>>> a = "abc123"
>>> a.isalnum()
True
>>> a.isalpha()
False
>>> a.isdigit()
False
>>> a.islower()
True
>>> a.isupper()
False
>>> a.isdecimal()
False
>>> b = "Abc Def"
>>> b.istitle()
True
>>> c = " \n\t"
>>> c.isspace()
True
- 内建方法之形式转换方法
- lower,转换成小写字母
- upper,转换为大写字母
- title, 转换为标题,即每个首字母大写,eg:Hello World
- swapcase,大小写反转,eg:AbcD --> aBCd
- capitalize,转换为首字母大写,其他字母小写
>>> s = "BALAbalabU"
>>> s = s.lower()
>>> s
'balabalabu'
>>> s = s.upper()
>>> s
'BALABALABU'
>>> s = s.title()
>>> s
'Balabalabu'
>>> s = s.swapcase()
>>> s
'bALABALABU'
>>> s = s.capitalize()
>>> s
'Balabalabu'
- 内建方法之字符串开头和结尾匹配方法
- startswith,是否以指定字符串开头
- endswith,是否以指定字符串结尾
>>> name = "煮面要加牛奶"
>>> name.startswith("煮面")
True
>>> name.endswith("奶")
True
>>> name.endswith("煮面")
False
- 内建方法之字符串常用数据清洗方法
- strip,删除字符串开头和末尾的空格
- lstrip,删除字符串开头有的空格
- rstrip,删除字符串末尾的空格
- replace,字符串替换
>>> s = " \tHello world\n "
>>> s.strip()
'Hello world'
>>> s.lstrip()
'Hello world\n '
>>> s.rstrip()
' \tHello world'
>>> s.replace("Hello", "nihao")
' \tnihao world\n '
- 内建方法之字符串位置调整方法
- center(width),字符串居中且长度为指定宽度
- ljust(width),字符串左对齐且长度为指定宽度
- rjust(width),字符串右对齐且长度为指定宽度
>>> s = "hello~~"
>>> s.center(30, "*") # *代表填充字符,默认为空格
'***********hello~~************'
>>> s.ljust(30, "*")
'hello~~***********************'
>>> s.rjust(30, "*")
'***********************hello~~'
>>> s.center(30)
' hello~~ '
- 内建方法之字符串查询方法
- find(str, beg, end),检测str是否包含在string中,并返回索引,否则返回 -1
- index(str, beg, end),检测str是否包含在string中,并返回索引,否则抛出异常
- count(str, start, end),检测str在string中出现的次数
- enumerate(),枚举对象,同时列出元素及元素下标
>>> string = "balabalacdef"
>>> string.find("balaba") # 返回最开始的字符的索引,即“b”的索引-> 0
0
>>> string.find("de")
9
>>> string.index("x") # 无,抛出异常
Traceback (most recent call last):
File "<input>", line 1, in <module>
ValueError: substring not found
>>> string.find("x") # 无,返回-1
-1
>>> string.count("a")
4
>>> for i, v in enumerate("hello"):
... print(str(i)+","+v)
0,h
1,e
2,l
3,l
4,o
- 内建方法之字符串的分离与拼接方法
- split(str=""),以str为分隔符切片string,默认为空格
- splitlines(),以换行符(\n)为分隔符切片string
- “xxx”.join,以"xxx"为连接符将多个字符串拼接为一个字符串
>>> string = "hello world hello python \n hello java"
>>> string.splitlines()
['hello world hello python ', ' hello java']
>>> temp = string.split()
>>> temp
['hello', 'world', 'hello', 'python', 'hello', 'java']
>>> "-".join(temp) # 快速将列表元素拼接为字符串
'hello-world-hello-python-hello-java'
2. 列表
2. 1 列表基本特性
列表是可以存储任意数据类型的集合。因为列表同样为有序数列,所以同样满足1.1小节字符串的基本特性:索引、切片、成员操作符(in、not in)、连接操作符(+)、重复操作符(*),此处不在赘述。
1. 2 列表的内建方法(增、删、改、查、排序)
- 增
- append,在列表末尾追加元素,一次一个
- insert,在列表指定位置插入元素
- extend,一次性追加多个元素,两个列表的元素合并
>>> li = [1, 2, "haha", ["hello", 1], 100]
>>> li.append("python")
>>> li
[1, 2, 'haha', ['hello', 1], 100, 'python']
>>> li.insert(0, "hello world")
>>> li
['hello world', 1, 2, 'haha', ['hello', 1], 100, 'python']
>>> li.extend([11, 22, 33])
>>> li
['hello world', 1, 2, 'haha', ['hello', 1], 100, 'python', 11, 22, 33]
- 删
- del,根据下标进行删除
- pop,默认删除最后的元素,并获取该元素
- remove,根据元素的值进行删除
- clear,清空列表中所有元素
>>> li
['hello world', 1, 2, 'haha', ['hello', 1], 100, 'python', 11, 22, 33]
>>> del li[0]
>>> li
[1, 2, 'haha', ['hello', 1], 100, 'python', 11, 22, 33]
>>> li.remove(100)
>>> li
[1, 2, 'haha', ['hello', 1], 'python', 11, 22, 33]
>>> item = li.pop()
>>> item
33
>>> item2 = li.pop(1)
>>> item2
2
>>> li.clear()
>>> li
[]
- 改
>>> li
[1, 'haha', ['hello', 1], 'python', 11, 22]
>>> li[0] = 1000 # 根据索引进行修改
>>> li
[1000, 'haha', ['hello', 1], 'python', 11, 22]
- 查
- index,查看某个元素的索引
- count,查看某个元素出现的次数
>>> li = [100, 200, 600, "python", 100, 100]
>>> li.index(100, 1, 6) # 指定范围("左闭右开"原则,可不指定)[1,6)内第一个出现的100的索引
4
>>> li.count(100)
3
- 排序
li.sort() 列表排序方法,默认为从小到大排序,利用reverse=True可使得排序为从大到小排序
>>> li = [66, 12, 76, 2, 34, 99, 33]
>>> li.sort()
>>> li
[2, 12, 33, 34, 66, 76, 99]
>>> li.sort(reverse=True)
>>> li
[99, 76, 66, 34, 33, 12, 2]
3. 元组
【注意】元组的创建:
- 定义空元组 tuple = ()
- 定义单个值的元组 tuple = (1 ,),小逗号不要忘记,否则不是元组,而是整型数据 1
- 一般的元组 tuple = (“haha”, 8, “python”)
3. 1 元组基本特性
元组像是带了紧箍咒的列表,也就是说元组虽然与列表一样可以存储任意数据类型,但是元组是不可变数据类型,即不可进行增、删、改操作。当然,元组同样为有序数列,所以同样满足1.1小节字符串的基本特性:索引、切片、成员操作符(in、not in)、连接操作符(+)、重复操作符(*),此处不在赘述。
3. 2 元组的内建方法
- 查
- index,查看某个元素的索引
- count,查看某个元素出现的次数
>>> my_tuple = (11, 33, 100, 11)
>>> my_tuple.index(100)
2
>>> my_tuple.count(11)
2
3. 3 元组的应用
- 解包
- 多元赋值机制
- 变量交换,即Python中x,y = y,x的底层实现
>>> my_tuple
(11, 33, 100, 11)
>>> w, x, y, z = my_tuple # 解包
>>> w
11
>>> x
33
>>> y
100
>>> z
11
>>> (x, y, z) = (1, 2, 3) # 多元赋值
>>> x
1
>>> y
2
>>> z
3
3. 4 拓展——命名元组
有”名字“的元组,通过 ”名字“定位元素,提高代码可读性。类似于字典,不同之处在于命名元组仍为不可变数据类型,不建议应用在频繁增删的场景中;而字典是可变数据类型。应用示例如下所示:
>>> from collections import namedtuple
>>> user_tuple = namedtuple("user_tuple", ["name", "age", "id"])
>>> user = user_tuple("xiaohong", 18, 10001)
>>> print(user)
user_tuple(name='xiaohong', age=18, id=10001)
ps:对命名元组有兴趣的童鞋可参见小小的应用案例:https://blog.csdn.net/qq_21156327/article/details/103426446
