VMware+centos7进行hadoop伪分布式搭建,手把手教导,完全零基础!!!
百度链接:centos7+jdk+hadoop+Xshell文件点击这里
本文将手把教导大家搭建hadoop伪分布式,有图有真相
使用到:一台电脑+vmware+Xshell[选用]+jdk.gz+hadoop.gz
注:
本文还涉及到一些linux操作命令,由于我对linux操作本身也不太熟【写博客就是为了督促自己学习】,所以我会事无巨细的写出用途,所以请放心食用
【关于Xshell的作用,本质来说就是在用自己的电脑连自己【我打我自己】,但是我还是要介绍下【傲娇的挺了挺,灵魂画手上线】】
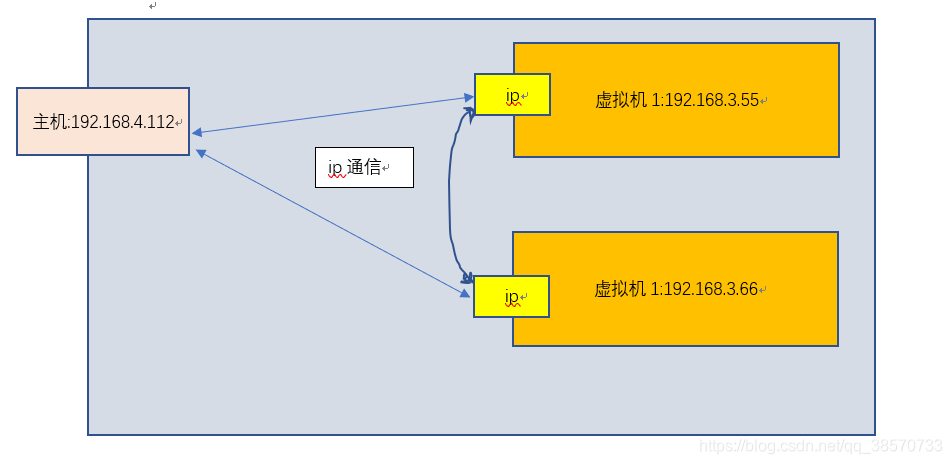
所以别看,都在我电脑上,但是我在主系统上使用Xshell,来连接我在vmware启动的虚拟机,那感觉,跟我用xshell使用我的云系统是一样的,所以如果还不会的同学,请跟着我使用吧【不用其实没啥关系的,直接操作虚拟机就行】
开始的准备工作
1.关于使用的jdk文件为啥是7,8版本,这个问题我了解的就是跟hadoop底层用到的就是7,8开发有关;由于9+版有巨大的变革,为了减少不必要的麻烦,建议不太懂得人就用我分享的,当然自己去官网下载也是可以的,但是本质上还是建议用8版本。
2.准备在VMware安装centos7,当然去centos官网下载也是没得问题的,由于centos7,8都成功安装,所以本方法也适合在官网下载的的centos8版本。
在VMware进行安装centos7,安装计算节点:调试工具,性能工具,开发工具,就够了。
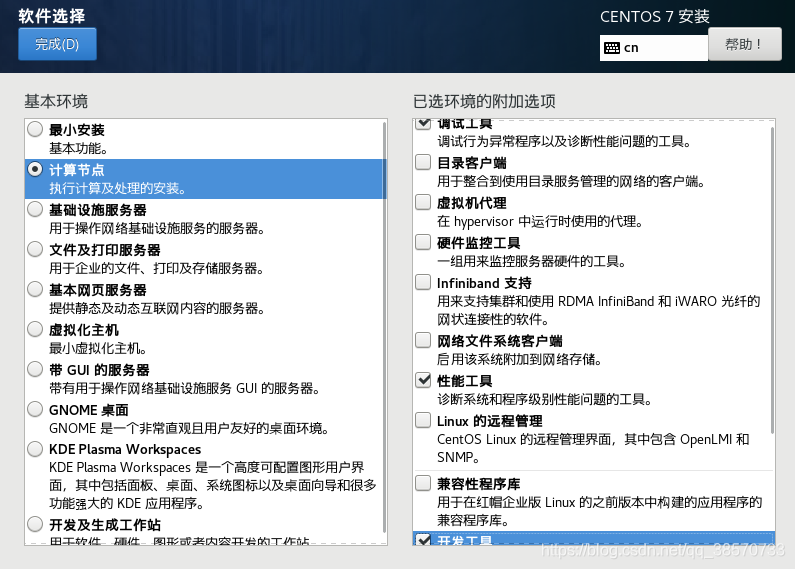
当然用GUI桌面也可以呀,增加别的功能也是可以的呀,这里用计算节点且只点三个功能万全是为了减少虚拟系统带来的负荷。
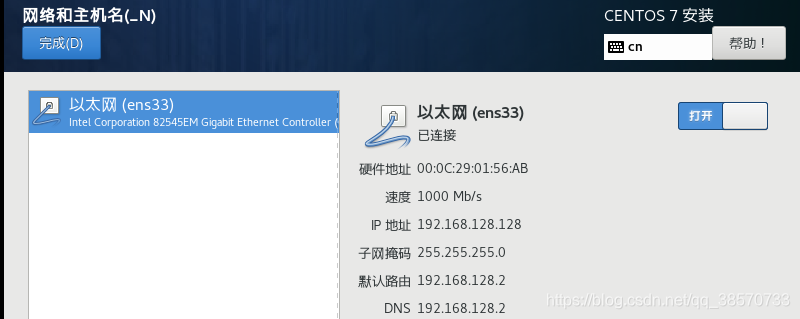
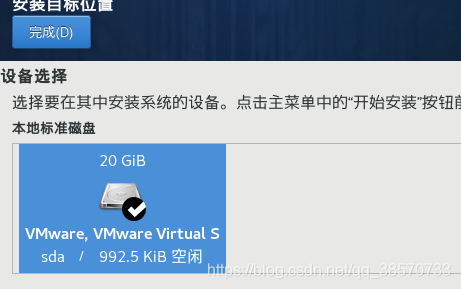
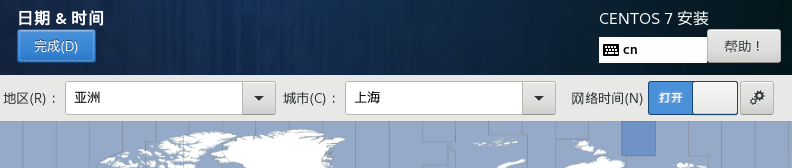
这里做了:关闭安全策略跟kdump,打开网络(这里可以通过自己手动改,且VMware也是有多种模式配合设置,不过不会的话默认就可以了),修改地区,安装位置。
至此,安装工作基本好了,后面就是设置root密码就行了,不用设置用户

以上的信息就是我选择root账户,然后进入现在的系统。证明系统运行是可以的,也打开了运行,接下来就是Xshell连接现在的虚拟系统。
1、用ifconfig命令:查看虚拟机的ipv4的地址:

2.用Xshell连接
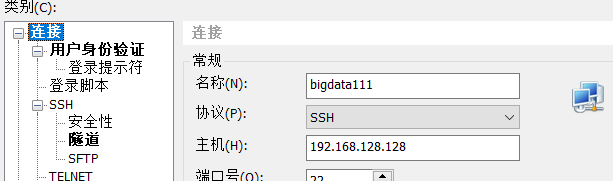

以上表示已经连接上了.现在是连接上了。
至此准备工作完成。
如果对这样连接有啥疑惑,那我在用Xshell连接我的云端服务器:
CONTENT内容块
hadoop的三种模式:
单机模式,跟伪分布模式,全分布模式
一、单机模式
单机模式的介绍:
当首次解压Hadoop的源代码时,hadoop是无法了解系统上的硬件环境的,所以默认的模式就是单机模式。在这个模式下,3个xml配置文件均为空,这时,hadoop会完全运行在本地。再单机模式下,我们不使用HDFS,也不加载任何Hadoop的守护进程,主要用于开发调试MapReduce程序的应用逻辑。
1.首先在linux中安装lrzsz:用于上传下载
安装的命令:yum -y install lrzsz
rz:从本地上传文件至服务器
sz filename:从服务器下载文件至本地
【
yum是Shell前端软件包管理,yum提供了查找、安装、删除某一个、一组甚至全部软件包的命令,而且命令简洁而又好记。
yum提供了查找、安装、删除某一个、一组甚至全部软件包的命令,而且命令简洁而又好记。
】


2.上传Hadoop跟jdk8



完成上传后,通过ls:来查看本地的文件跟目录:

通过pwd:来查看所在路径:

3.开始解压jdk8:
命令:tar -zxvf jdk-8u144-linux-x64.tar.gz -C /usr/local/:
tar 是解压命令
z:代表的是压缩
c:代表的是打包
x:代表的是解压
v:代表的是过程
f:代表的是指定文件名
tar -cvf etcbak.tar 打包一个tar
tar -xvf etcbak.tar 解开一个tar
tar -cvzf etcbak.tar.gz 打包压缩一个 tar
tar -zxvf etcbak.tar.gz 解压一个tar
-C 选项的作用是:指定需要解压到的目录。

代表已经解压到了/usr/local/路径。
4.配置jdk8的环境变量

通过按下i键,进行再文件最下面插入配置:

然后:esc+:wq用于保存退出.
. /etc/profile使得配置立刻生效;source /etc/profile 是相同的效果

分别用java、javac、java -version试试安装情况

至此jdk是终于完成了。
5.建立hadoop的使用用户
命令1:sudo useradd -m bigdata -s /bin/bash
创建名为:bigdata 的用户

1.sudo 是是linux系统管理指令,能让非root的用户使用超级命令的命令,存放的位置默认是在/etc/sudoers。简单的理解是,在sudoers文件内添加了用户名的用户,可通过sudo这个命令来行使一些高级权限。作为最高级的root:肯定是可以用这个命令的啦【但是有啥用,root本来就是最高级的控制者,根本不用sudo来赋予使用权】【对呀,我就是喜欢用,哈哈哈】
2.useradd 用来添加用户的命令,权限是超级用户
3.格式:useradd [-d home] [-s shell] [-c comment] [-m [-k template]] [-f inactive] [-e expire ] [-p passwd] [-r] name
4.主要参数
-c:加上备注文字,备注文字保存在passwd的备注栏中。
-d:指定用户登入时的启始目录。
-D:变更预设值。
-e:指定账号的有效期限,缺省表示永久有效。
-f:指定在密码过期后多少天即关闭该账号。
-g:指定用户所属的群组。
-G:指定用户所属的附加群组。
-m:自动建立用户的登入目录。
-M:不要自动建立用户的登入目录。
-n:取消建立以用户名称为名的群组。
-r:建立系统账号。
-s:指定用户登入后所使用的shell。
-u:指定用户ID号。
5.bigdata 是我准备赋予的名字
6.-s /bin/bash 使用命令:/bin/bash执行过程中,若命令执行失败,仍然会继续执行。即我创建用户的命令失败了还是会继续执行
命令2:sudo passwd bigdata
为bigdata赋予密码

至此hadoop使用用户创建完成。
登录[root@hadoop1 ~]# ssh bigdata@bigdata111
输入密码登陆成功【当然也有可能被拒绝访问,原因在下面】
6.创建秘钥,用于设置免密登入
[bigdata@bigdata111 ~]$ ssh-keygen -t rsa
三次回车,作用:用于生成秘钥
[bigdata@bigdata111 ~]$ ssh-copy-id bigdata@bigdata111
输入密码,作用:复制SSH密钥到目标主机,开启无密码SSH登录
当然大家会发现无法访问,知道为啥吗?
因为@bigdata111并没有跟你的地址,如我的是192.168.128.128映射呀,所以发现无法使用时候,用命令:
[bigdata@bigdata111 ~]$ssh-copy-id [email protected]

那么如何映射那?或者说我们只要用主机名就可以了那?毕竟谁记自己的IP地址呀
当然是:修改/etc/hosts文件啦
[root@bigdata111 ~]# vim /etc/hosts
在第一行添加: 本机IP bigdata111 的映射,如下:
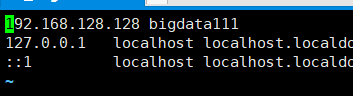

通过实验室证明可以免密登入,虽然很扯淡。毕竟那样有啥用呀
对比如下:

这里就发现,哪怕root用自己登入自己也是需要密码的。
好了不讲这些了,毕竟耽误这么久,是时候安装hadoop了。
7.吧hadoop包解压到/home/bigdata/apps
1.创建apps文件夹:$ mkdir -p /home/bigdata/apps
【参数:-p 确保目录名称存在,如果目录不存在的就新创建一个。】
2.解压:tar -zxvf hadoop-2.7.3.tar.gz -C /home/bigdata/apps
3.修改hadoop-env.sh:
$ cd /home/bigdata/apps/apps/hadoop-2.7.6/etc/hadoop
$ vim hadoop-env.sh
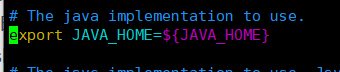
把export JAVA_HOME=${JAVA_HOME}改为:

当然这是我的jdk的存放地,填自己的jdk存放地就可以了。
来到安装的位置:

在这里输入:bin/hadoop 来检验hadoop是否可以运行。
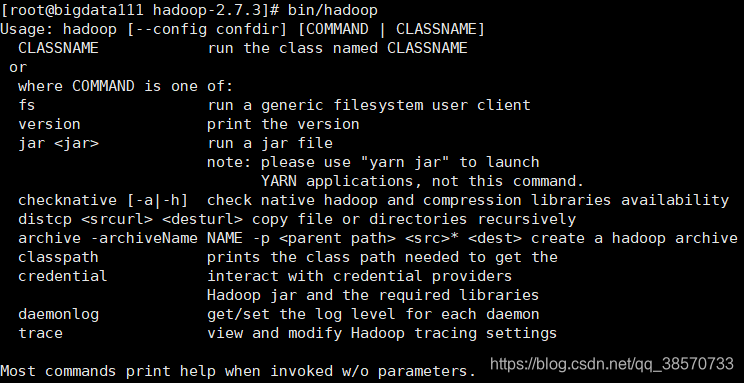
这样就是完成了单机模式啦。【撒花,撒花】

单机模式的追加信息!!!
Hadoop默认的模式就是单机模式,以单个java进程运行。现在我们可以在单机模式下执行第一个MapReduce任务:在 etc/hadoop 下的所有xml文件中,寻找匹配指定正则表达式的字段。
这是未开始的状态:

(1)创建一个存放作为输入任务的文件目录:
[root@bigdata111 hadoop-2.7.3]# mkdir input
(2)将作为输入的文件复制到下面的目录下:
[root@bigdata111 hadoop-2.7.3]# cp etc/hadoop/.xml input

(3)最后运行安装包中自带的MapReduce例子来匹配正则表达式,执行结果将输出到output:
[root@bigdata111 hadoop-2.7.3]# bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar grep input output ‘dfs[a-z.]+’

(4)查询结果:[root@bigdata111 hadoop-2.7.3]# cat output/

【正则表达式:. 匹配除换行符 \n 之外的任何单字符,+ 匹配前面的子表达式一次或多次:所以dfs[a-z.]+的意思是:先匹配到dfs然后后面匹配a-z或任何单个字符,中的任何一个,[a-z.]并且一次到多次】
至此:对单机模式其实就有一个很直观的明白。单机模式下,就是为了使用MapReduse程序的应用逻辑。
MapReduse分而治之的思想,把大的问题切割成小的问题

MapReduce的步骤:
1.Map:工作节点对本地的数据应用,map()函数
2.shuffle:根据map()的结果重新分配数组
3.reduce:所有节点同时处理所有的数据组

hadoop会把MapReduce的输出数据划分成同等长度的小数据块,称为split(输出分片)
shuffle指的是把数据从Map的输出导入到负责Reduce的程序的过程。
!!至此关于单机Hadoop的叙述到此结束,关于MapReduce的介绍也到这里!!!,接下来进行下一步,伪分布式的搭建!!

二.伪分布式的搭建
伪分布模式是在“单节点集群”,上运行Hadoop,因为所有的守护进程都运行在同一台机器上,在该模式下,通过代码调试功能,可以检查内存使用情况,HDFS的输入输出,以及其他守护进程的的交互。
当我们刚开发了一个应用程序的时候,使用伪分布模式来做测试和验证会简单许多。
在伪分布模式下,多个Hadoop daemon在同一台机器上的不同Java进程中运行,而从上面的单机模式转换为伪分布式模式需要的操作有如下:
(1)修改配置
首先来到/home/bigdata/apps/hadoop-2.7.3/etc/hadoop

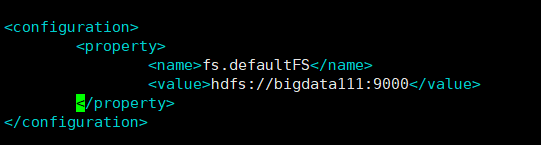
1.修改core-site.xml:[root@bigdata111 hadoop]# vim core-site.xml

<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata111:9000</value>
</property>
</configuration>
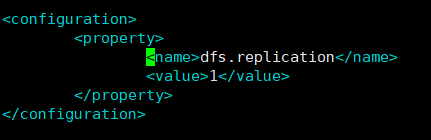
2.修改hdfs-site.xml:[root@bigdata111 hadoop]# vim hdfs-site.xml

<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
(2)再次验证下,是否可以免密登入到bigdata111

回到:/home/bigdata/apps/hadoop-2.7.3

(3)运行看看
1.格式化文件系统【即,对hadoop初始化】
bin/hdfs namenode -format
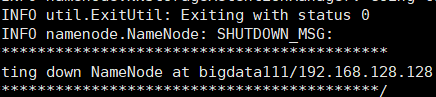
exit with suatus 0 退出状态为0,表示成功无错误。即成功
2.启动NameNode daemon 和 DataNode daemon:
[bigdata@bigdata111 hadoop-2.7.3]$ sbin/start-dfs.sh

权限不够的问题可以吧bigdata调为超级用户:
改成可修改模式:

修改的地方为:[root@bigdata111 hadoop-2.7.3]# vim /etc/sudoers

改成只阅读模式:

3.再次启动NameNode daemon 和 DataNode daemon

[bigdata@bigdata111 hadoop-2.7.3]$ sbin/start-dfs.sh
问题还是没得解决。依然是权限不足。
用root权限好了,就是要多打几次密码【因为免密是放在bigdata用户上的】
1初始化:

2.启动NameNode daemon 和 DataNode daemon
[root@bigdata111 hadoop-2.7.3]# sbin/start-dfs.sh
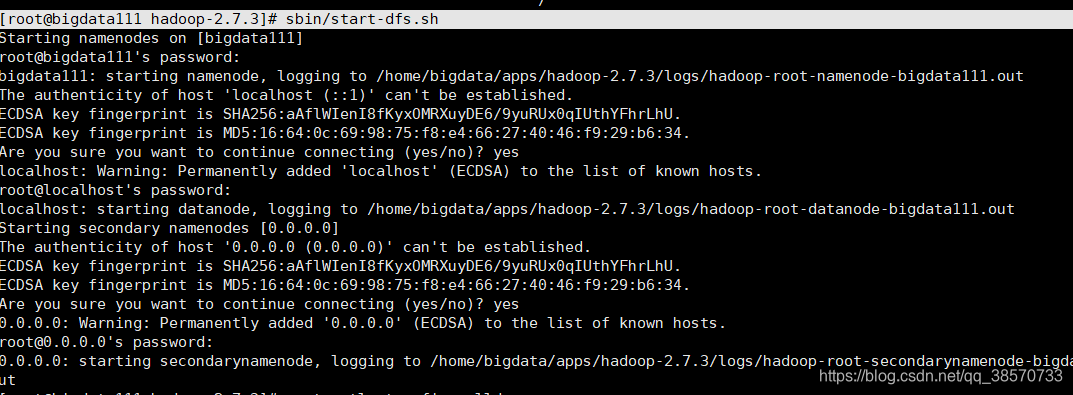
成功了。
(4)成功启动后就可以通过浏览器访问 namenode的web界面。默认地址为:
http://IP:50070
【当然如果有步骤都对打不开的,基本就是防火墙的问题:
运行命令:systemctl stop firewalld
】
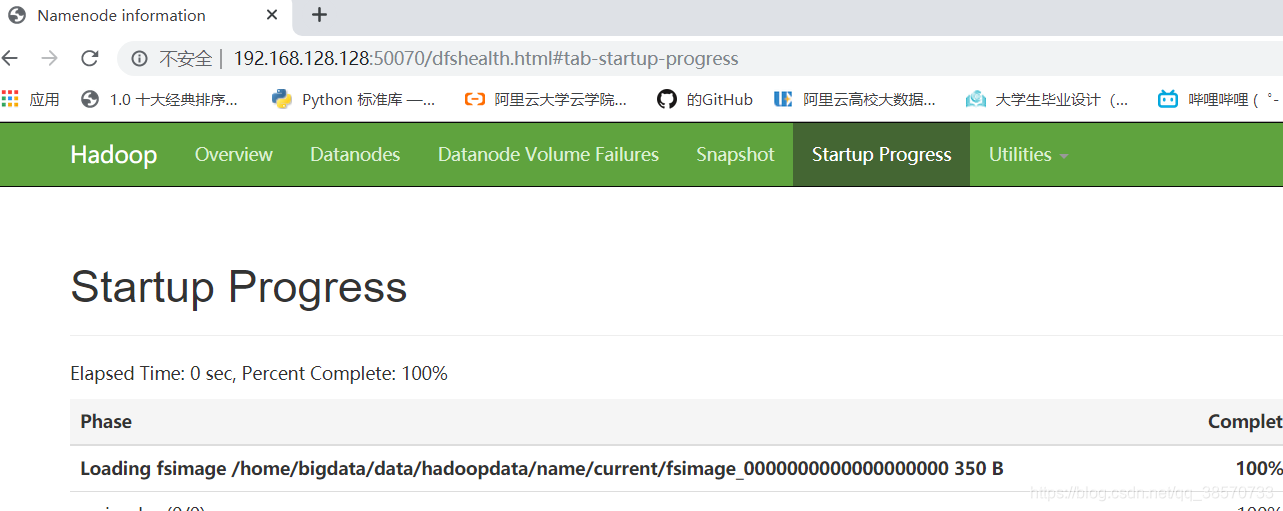
至此伪分布搭建就完成了!!!
当然,用户的权限问题还没得到解决,但是我们依然可以通过root来运行,影响不大。
运行下试试:
1.确定所在的位置:
[root@bigdata111 hadoop-2.7.3]# pwd
/home/bigdata/apps/hadoop-2.7.3
2.为下面将要运行的MapReduce任务在HDFS上新建两个目录:
[root@bigdata111 hadoop-2.7.3]# bin/hdfs dfs -mkdir /user
[root@bigdata111 hadoop-2.7.3]# bin/hdfs dfs -mkdir /user/root
这里的/user/root的root是【使用者,即我用root就是root名】

3将作为输入的文件(etc/hadoop下的文件)放到HDFS上的input目录下:
bin/hdfs dfs -put etc/hadoop input
4.运行安装包中自带的的MapReduce例子来匹配正则表达式,执行结果将输入到HDFS上的output目录下:
命令:bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar grep input output ‘dfs[a-z.]+’
5.查询HDFS上的output目录下的结果:
命令:bin/hdfs dfs -cat output/*
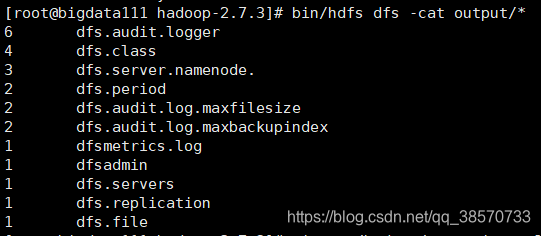
6.任务完成后,执行下面的指令停止daemon:
命令:sbin/stop-dfs.sh
至此不管是伪分布的搭建,还是实验运行,都是已经完成了!!!
三.完全分布搭建
全分布式才是Hadoop集群的真正模式。在全分布模式下的Hadoop系统,有主节点(Namenode)和从属数据节点(Datanode)
通过VMware的克隆功能做出3台克隆机,记得全是完全独立的克隆机呦。

第一步:把所有的主机改下名字,因为是克隆的,所以主机名都是一样的:
修改:hostnamectl set-hostname 修改的主机名
查看:hostnamectl
第二步:对/etc/hosts文件进行修改
vim /etc/hosts
IP 主机名
例如:在bigdata111主机上就如下图:

第三步、关闭防火墙:systemctl stop firewalld
1.生成公钥
给每台都运行的命令,为了生成公钥:
ssh-keygen -t dsa -P ‘’ -f ~/.ssh/id_dsa
2.把公钥给自己,拷贝认证给下个节点node
bigdata100运行以下命令:
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys && scp ~/.ssh/authorized_keys bigdata101:/root/.ssh/authorized_keys
bigdata101运行以下命令:
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys && scp ~/.ssh/authorized_keys bigdata110:/root/.ssh/authorized_keys
bigdata110运行以下命令:
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys && scp ~/.ssh/authorized_keys bigdata111:/root/.ssh/authorized_keys
bigdata111运行以下命令:
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
scp ~/.ssh/authorized_keys Linux001:~/.ssh/authorized_keys
scp ~/.ssh/authorized_keys Linux002:~/.ssh/authorized_keys
scp ~/.ssh/authorized_keys Linux003:~/.ssh/authorized_keys
这里就是以bigdata111作为master,100、110、101作为slave.
当然因为没有设置主机名跟地址IP映射,所以只能用地址IP,也可以在每个vim /etc/hosts
例子在bigdata100上的设置:
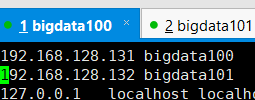
同样,想要跟给了公钥的主机,直接用主机名进行通信,就要在hosts中设置。
当然还有个问题设置静态IP,由于没设静态IP,在关机后有会随机分配IP那你可能又要调节自己的IP设置,这是相当相当的无法忍受的事情。
,当然在创建虚拟机的时候也是可以设置的,不过网络区间肯定要对应的。
第四、同步服务器时间【可选】
1、yum -y install vim ntp
2、chkconfig ntpd on && service ntpd start
3、date
第五步、就是给111、110、101、100配置jdk,给111配置hadoop,但是其实不用,111是配置了伪分布式的,110、101、100都是他的完全独立的克隆机,所以只是在给hadoop配置运行环境
命令:vi /etc/profile
export HADOOP_HOME=/opt/apps/hadoop-2.6.5
export PATH=
HADOOP_HOME/bin:$HADOOP_HOME/sbin
命令: source /etc/profile
第六步、创建数据保存目录(仅在bigdata111上)
mkdir -p /home/bigdata/apps/hadoop-2.7.3/data/namenode /home/bigdata/apps/hadoop-2.7.3/data/datanode /home/bigdata/apps/hadoop-2.7.3/data/tmp
第7步、配置配置文件(仅在bigdata111上)
1.vim /home/bigdata/apps/hadoop-2.7.3/etc/hadoop/core-site.xml
<!--指定namenode的位置-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata111:8020</value>
</property>
<!--指定指定namenode数据存放路径-->
<property>
<name>hadoop.name.dir</name>
<value>/home/bigdata/apps/hadoop-2.7.3/data/namenode</value>
</property>
<!--指定指定Hadoop数据存放路径-->
<property>
<name>hadoop.data.dir</name>
<value>/home/bigdata/apps/hadoop-2.7.3/data/datanode</value>
</property>
<!--指定指定Hadoop临时数据存放路径-->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/bigdata/apps/hadoop-2.7.3/data/tmp</value>
</property>
2.vim /home/bigdata/apps/hadoop-2.7.3/etc/hadoop/hdfs-site.xml
<!-- 指定block默认副本个数 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--指定secondarynamenode的主机和http服务的端口号-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>bigdata111:50090</value>
</property>
3.cp /home/bigdata/apps/hadoop-2.7.3/etc/hadoop/mapred-site.xml.template /home/bigdata/apps/hadoop-2.7.3/etc/hadoop/mapred-site.xml
vim /home/bigdata/apps/hadoop-2.7.3/etc/hadoop/mapred-site.xml
<!--配置mapreduce运行的平台-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
4.vi /home/bigdata/apps/hadoop-2.7.3/etc/hadoop/yarn-site.xml
<!--配置yarn的主节点-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bigata111</value>
</property>
<!--配置MapReduce处理数据的方式-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
5.vi /home/bigdata/apps/hadoop-2.7.3/etc/hadoop/slaves
配置DataNode所在节点
bigdata100
bigdata101
bigdata110
第八步、拷贝配置文件(仅在bigdata111上)
scp -r /home/bigdata/apps/hadoop-2.7.3 root@bigdata100:/home/bigdata/apps/
scp -r /home/bigdata/apps/hadoop-2.7.3 root@bigdata110:/home/bigdata/apps/
scp -r /home/bigdata/apps/hadoop-2.7.3 root@bigdata101:/home/bigdata/apps/
第九、加入hadoop环境变量(除bigdata111外的其他节点)
命令:vim /etc/profile
export HADOOP_HOME=/home/bigdata/apps/hadoop-2.7.3
export PATH=
HADOOP_HOME/bin:$HADOOP_HOME/sbin
命令:source /etc/profile
第十、格式化hdfs(仅在bigdata111上)
/home/bigdata/apps/hadoop-2.7.3/bin/hdfs namenode -format
十一、将bigdata111格式化后的数据文件到其他节点
scp -r /home/bigdata/apps/hadoop-2.7.3/ root@bigdata100:/home/bigdata/apps/hadoop-2.7.3/
scp -r /home/bigdata/apps/hadoop-2.7.3/ root@bigdata101:/home/bigdata/apps/hadoop-2.7.3/
scp -r /home/bigdata/apps/hadoop-2.7.3/ root@bigdata110:/home/bigdata/apps/hadoop-2.7.3/
十二、启动集群(任意节点执行都行)
start-all.sh
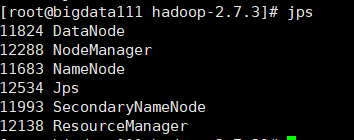

代表成功了。至此hadoop三种搭建是走了一遍。就我个人而言,中途也有一些这样那样的问题,好在都最后解决了,最大的收获。可能是对linux一度感觉很熟【错觉,接触还没一个星期那,但是反复的配变量,反复的搞着搞那真的是另我一度想过,写的真累。整篇文章写了三天,是真的心累了!!!】但是对linux的一些控制到是熟的一批了,开心!!!
好了这也就是我的一个对新东西的记录,如果对你有帮助的话,那再好不过了!

