本次文章主要是记录使用python中的requests库进行如何下载大文件学习记录。
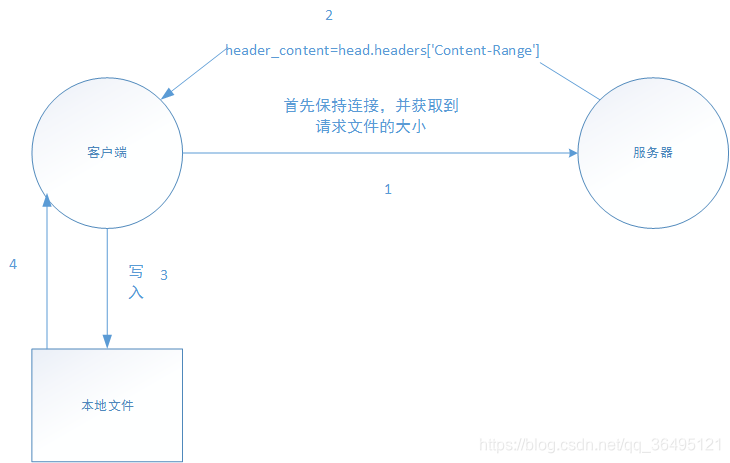
1.首先请求服务器要下载的文件为多大及服务器是否支持断点续传功能。
2.服务器返回被请求文件大小及断点续传功能支持与否的信息。
3.客户端首先将部分请求的数据写入文件中,请求头部可如下:
header={
'Range': 'bytes=0-10'#即要请求的数据位0-10范围,可以这么理解即:百分之0 到百分之10 ,每次请求多少由自己定义
}
4.客户端读取本地写入的文件大小,再次请求服务器,再追加到文件中,注意是“再请求”“二进制追加”,且连接可不断开,部分代码如下:
header={
'Range': 'bytes=x-x+10'#即要请求的数据位x-x+10范围,可以这么理解即:百分之x 到百分之x+10
}
# w:以写方式打开
# a:以追加模式打开
# r+:以读写模式打开
#
# w+:以读写模式打卡
#
# rb:以二进制读模式打开
# wb:以二进制写模式打开
#
# ab:以二进制追加模式打开
#
# rb+:以二进制读写模式打开
# wb+:以二进制读写模式打开
open对象常用的方法
read():读取字节到字符串中
readline():打开文件的一行,包括行结束符
readline():打开文件,读取所有行
write():将字符串写入文件,写入对象为字符串
writelines():将列表写入文件,对象是列表。
seek():偏移量
tell():返回当前文件指针的位置
#追加文件
with open("test.docx","wb+") as fn:
fn.write(res.content)
HTTP断点续传
实现断点续传功能,客户端要记录下载进度即下载区域,再续传就要传递下载的区域片段。
HTTP1.1协议(RFC2616)中定义了断点续传相关的HTTP头 Range和Content-Range字段

Ranges用法:
Ranges: (unit=first byte pos)-[last byte pos]
Ranges: bytes=4000- 下载从第4000字节开始到文件结束部分
Ranges: bytes=0~N 下载第0-N字节范围的内容
Ranges: bytes=M-N 下载第M-N字节范围的内容
Ranges: bytes=-N 下载最后N字节内容
requests库中的head
- 以很少网络流量获得概要信息
# -*- coding: utf-8 -*-
#本次示例为http,若要使用https则需要进行SSL部分代理处理,处理方式在其它文章中有提到
import requests
url="http://172.7.1.60"
head=requests.head(url)
print head.headers
'''
打印的信息
{'Content-Length': '481', 'Keep-Alive': 'timeout=10, max=99', 'Server': 'webserver', 'Last-Modified': 'Thu, 01 Mar 2018 06:11:39 GMT', 'Connection': 'keep-alive', 'ETag': '"acc-1e1-5a97999b"', 'Date': 'Fri, 17 Jan 2020 10:59:55 GMT', 'Content-Type': 'text/html'}
'''
# -*- coding: utf-8 -*-
#此脚本只是代码思路,还有很多要优化的地方
#本次示例为http,若要使用https则需要进行SSL部分代理处理,处理方式在其它文章中有提到
import requests, sys, os, re, time
import os
url="http://172.7.1.61:80/test/xxx.docx"
url_="http://172.7.1.61:80"
headers={
'Range': 'bytes=0-10'
}
head=requests.head(url,headers=headers)
#查看是否支持 断点续传
header_accept=head.headers['Accept-Ranges']
if header_accept=="bytes":
#支持断点续传
try:
#功能实现:每10个bytes请求 ,请求
headers={
'Range': 'bytes=0-10'
}
#获取文件的bytes大小
header_content=head.headers['Content-Range']
print header_content
#提取请求中的文件大小
sd=header_content.split("/")
content=sd[1]
print content
#第一次获取到10bytes
res=requests.get(url, stream = True, verify = False, headers = headers)
i=10
with open("test.docx","wb+") as fn:
fn.write(res.content)
while i<=int(content):
#每次请求部分资源 以二进制的形式写入文件中
i=i+10
headers={
'Range': 'bytes='+str(i-10)+"-"+str(i)
}
res=requests.get(url, verify = False, headers = headers)
with open("test.docx","wb+") as fn:
fn.write(res.content)
# pass
except Exception as e:
print e.message
else:
pass
finally:
pass
else:
print ""
# #不支持断点续传
# #-------------
# #查看资源的大小及 请求的大小在资源内的范围
# header_content=head.headers['Content-Range']
# #查看文件更新的变化,可以用来判断文件是否更新
# header_ETag=head.headers['ETag']
# #HTTP连接,查看HTTP连接状态
# header_Connection=head.headers['Connection']
# print header_accept,header_content,header_ETag,header_Connection
Requests库下载大文件脚本
•当流下载时,用Response.iter_content或许更方便些。requests.get(url)默认是下载在内存中的,下载完成才存到硬盘上,可以用Response.iter_content 来边下载边存硬盘
#! -*-coding:UTF-8-*-
import os
import requests
#使用requests库 屏蔽HTTPS错误
from requests.packages import urllib3
urllib3.disable_warnings()
#res=requests.get("https://pro.hik-connect.com/download/RemoteWebControl.exe","verify=False",stream=True)
#f=open("asdads.exe","wb")
# name = url_video[url_video.rindex('=') + 1:]
# response = requests.get(url=url_video,headers=headers)
import subprocess
r = requests.get("https://psssss/RemoteWebControl.exe","verify=False", stream=True)
f = open(r"asd.exe", "wb")
print 'xxx'
#迭代读取内容 读取的大小为512bytes
for chunk in r.iter_content(chunk_size=512):
if chunk:
f.write(chunk)
else:
break;
pro=subprocess.Popen("E:\\asd.exe", shell=True)
print pro
