文章目录
1 关联查询
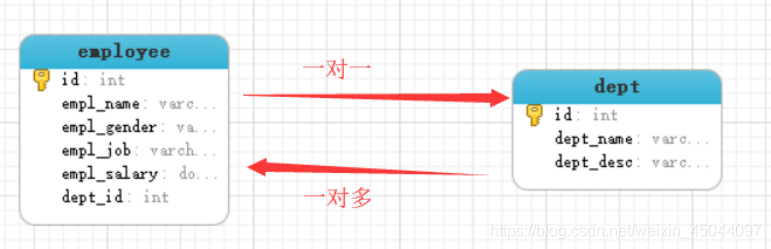
1 一对一查询
数据结构:
1.1 使用 resultType
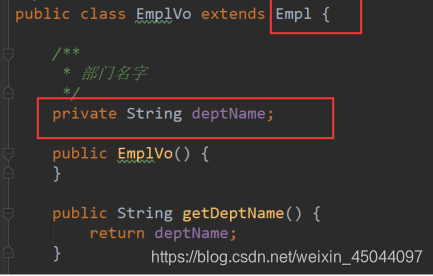
使用 resultType, 创建 Empl 的包装类,此包装类(Vo)中包括了员工信息和部门信息,这样返回对象的时候, mybatis 自动把用户信息也注入进来了。
创建员工包装类继承员工类:
修改 mapper 接口:
public interface EmplMapper {
// 查询所有员工
List<EmplVo> findAll();
}
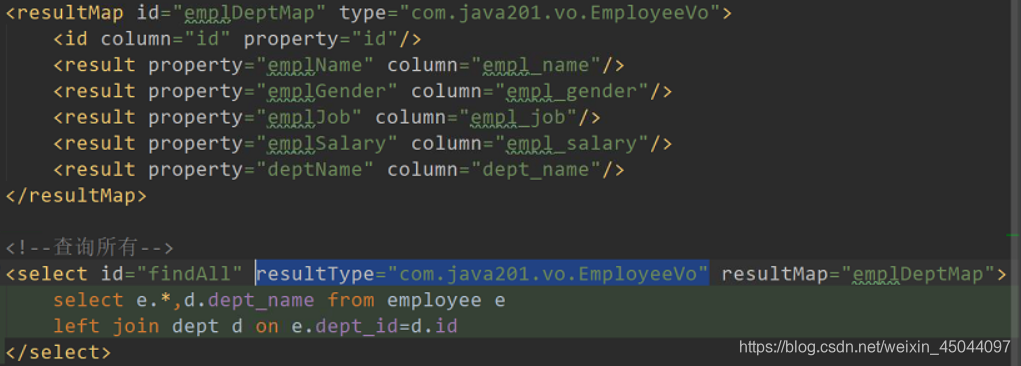
注意:resultMap 的 id 和 select后面的resultMap对应。注意type和resultType中的内容。
1.2 使用 resultMap
使用 resultMap,定义专门的 resultMap 用于映射一对一查询结果。
修改 pojo,加入对应的关联 pojo 的属性:在 Employee 中添加:

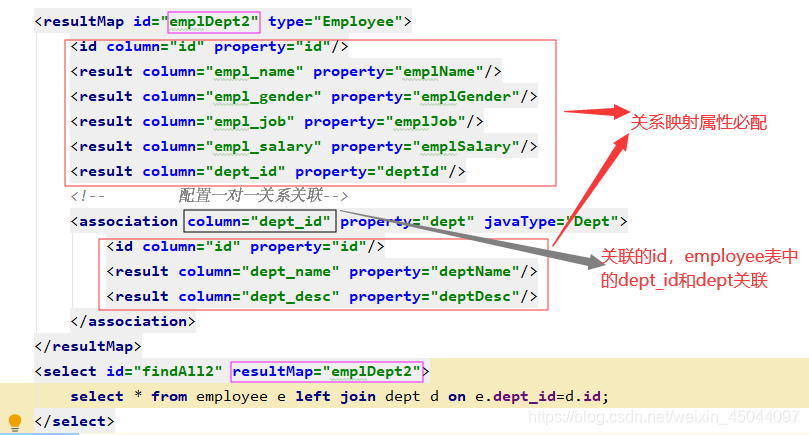
配置说明:
association:配置一对一关系映射
| – property;Empl 实体类中的Dept 的属性名
| – javaType:属性的类型
| – column:关联的数据库字段名
id:关联查询的标识
| – column:主表(dept)的主键
| – property:主表主键列所对应的 pojo 的属性名
result:其他字段属性映射
| – column:表字段列名
| – property:表中所对应 pojo 的属性名
注意:在使用association 进行关联映射后,无论字段列名与 pojo 类属性名是否一致,都需要使用 id 或者 result 进行配置,否则无法映射成功,属性为null。
1.3 使用 resultMap,配置不同mapper
效率最高,利用mybatis一级缓存特性。
1.实体Employee添加 private Dept dept;getter/setter方法
2.接口中有方法findAll(); 配置EmplMapper.xml
<mapper namespace="com.java201.dao.EmployeeMapper">
<resultMap id="emplDept" type="Employee">
<id column="id" property="id"/>
<result column="empl_name" property="emplName"/>
<result column="empl_gender" property="emplGender"/>
<result column="empl_job" property="emplJob"/>
<result column="empl_salary" property="emplSalary"/>
<result column="dept_id" property="deptId"/>
<!-- 配置一对一关系关联-->
<association column="dept_id" property="dept" javaType="dept" select="com.java201.dao.DeptMapper.findById">
<!--利用mybatis一级缓存特性,效率高-->
</association>
</resultMap>
<select id="findAll" resultMap="emplDept">
select * from employee;
</select>
</mapper>
3.接口DeptMapper添加方法findById

public interface DeptMapper {
List<Dept> findAll();
Dept findById(Integer id);
}
4.配置DeptMapper.xml
<mapper namespace="com.java201.dao.DeptMapper">
<select id="findAll" resultType="com.java201.pojo.Dept">
select * from dept
</select>
<resultMap id="deptMap" type="Dept">
<id column="id" property="id"/>
<result property="deptName" column="dept_name"/>
<result column="dept_desc" property="deptDesc"/>
</resultMap>
// 这里要配置resultType="deptMap",不然就会数据库下划线转驼峰,取不出来值
<select id="findById" resultType="deptMap" parameterType="integer">
select * from dept where id=#{id}
</select>
</mapper>
当 数据库中dept_id都为1时,测试的时候,只会查询一次dept表(id=1),这样就体现出了一级缓存的优势,提高查询效率。



1.2 一对多查询
查询一个部门下的所有员工 —— 一对多
- 修改pojo
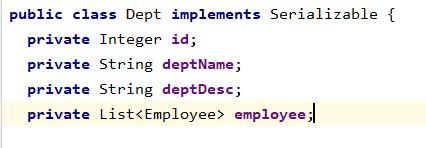
- 配置mapper
DeptMapper.xml(重点在collection)
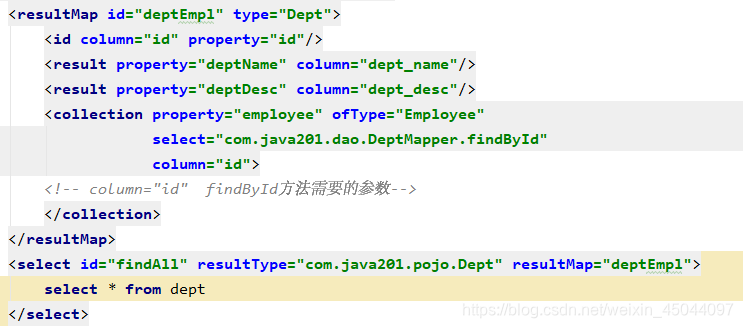
EmployeeMapper.xml
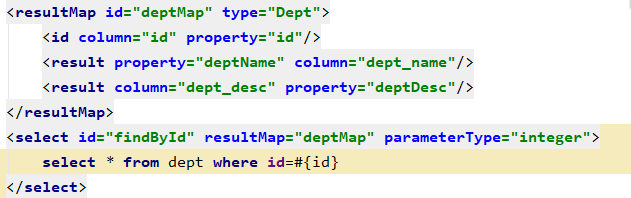
- 测试

结果:

1.3 多对多查询
主要通过角色去关联查询权限,知道某个角色,就知道他的权限数据。
标准 权限 设计表:5张表
用户表:user;
用户-角色
角色表:role
角色-权限;
权限表:access
案例:
https://blog.csdn.net/weixin_45044097/article/details/103052705
2 mybatis延迟加载
2.1 概念
举例说明什么是延迟加载:
我们想查询一个员工的信息,同时还要查询出他所在的部门,我们可以先查询出员工的信息,当需要部门信息的时候,再根据员工的和部门关联的 dept_id 去发送一次查询,获取部门信息,把对部门信息的按需查询就是延迟加载。
所以延迟加载 即先从单表查询,需要时再从关联表去关联查询,大大提高数据库性能。因为查询单表要比关联查询多张表速度要快。
2.2 association实现
association 和 collection 具备延迟加载的功能,拿 association 来说明,collection 和 association 使用的方法都是一样的。需求就是上面提到的,查询员工并且关联查询部门,查询部门使用延迟加载。由上面的分析可知,延迟加载要查询两次,第二次是按需查询,之前一对一关联查询的时候只需要查一次,把员工和部门信息都查出来了,所以只要写一个 statement 即可。 但是延迟加载查两次,所以要有两个 statement,并且这两个statement 分别在不同的映射文件中。mybatis 实现延迟加载的方式是由 cglib 生成代理对象,所以需要在 pom.xml 中引入 cglib 的依赖。
<dependency>
<groupId>cglib</groupId>
<artifactId>cglib</artifactId>
<version>2.2.2</version>
</dependency>
(动态代理,jdk代理实现接口的类)
2.3 具体实现步骤
- 下载cglib依赖
- 需要在核心配置文件sqlMapConfig.xml中的setting中手动开启延迟加载,关闭立即加载。
// 开启延迟加载
<setting name="lazyLoadingEnabled" value="true"/>
// 关闭立即加载
<setting name="aggressiveLazyLoading" value="false"/>
- mapper接口,mapper.xml配置和一对一查询效率高的方式的配置一致。
3 mybatis逆向工程
在写 mybatis 的时候有很多代码其实都差不多,比如对一个表的CURD 操作,我们重复去写这些代码没有什么意义,所以逆向工程帮我们解决这个问题(代码生成器)。
3.1 说明
官方自带逆向工程,但是并不是很方便,推荐使用插件mybatisCodeHelper;
收费!!(免费用几天)
3.2 自动生成代码
1.选择生成代码
2.配置
4 分页
4.1 分页步骤
select * from user limit 5; //限制5条
select * from user limit 0,5;//开始下标,长度Length
- 下载依赖
- 核心配置文件中 配置拦截器插件(environment后面)
<plugins>
<!-- com.github.pagehelper为PageHelper类所在包名 -->
<plugin interceptor="com.github.pagehelper.PageInterceptor">
<!-- 使用下面的方式配置参数,后面会有所有的参数介绍 -->
<property name="param1" value="value1"/>
</plugin>
</plugins>
- 代码中使用
//第二种,Mapper接口方式的调用,推荐这种使用方式。
PageHelper.startPage(1, 10);//开始的页数pageNum,页面大小pageSize(显示条数)
List<Country> list = countryMapper.findAll();
参考官方文档:
https://pagehelper.github.io/docs/howtouse/
5 通用mapper
极大的方便开发人员,可以随意按照自己需要选择的通用方法,还可以很方便的开发自己的通用方法。
简化单表操作(CRUD)
支持单表操作,不支持通用的多表联合查询。
不是表中的字段的属性必须加@Transient注解(序列化)
不支持devtools热加载
