作者:石文
时间:2018-10-29
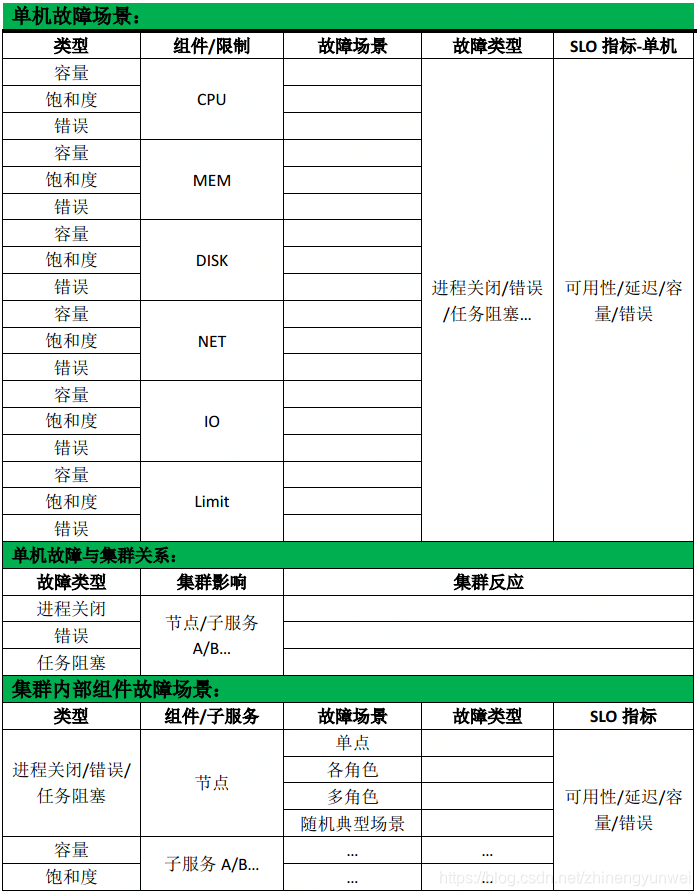
分布式系统故障场景梳理方法:
场景梳理逻辑关系:
- 单点硬件故障→单点进程故障类型→集群影响→集群故障场景
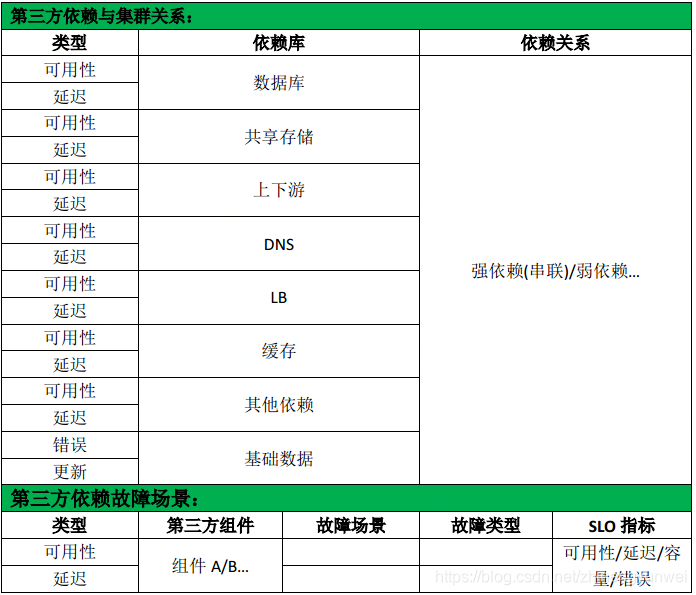
- 第三方依赖故障→集群依赖关系→集群影响→集群故障场景
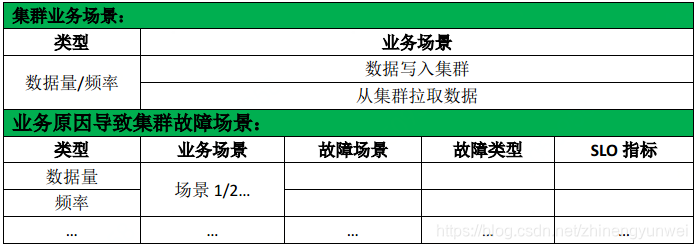
- 业务场景→集群负载/错误影响→集群故障场景
Kafka故障场景
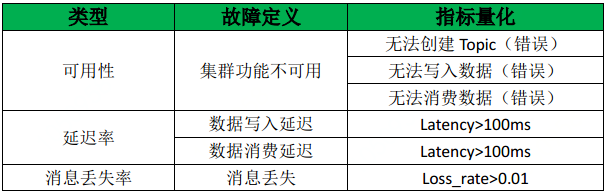
Kafka故障的定义是什么?
故障场景
- 单点硬件故障→集群故障场景
- 第三方依赖故障→集群故障场景

- 业务场景→集群故障场景
Kafka压测
Kafka数据丢失:
Kafka什么情况下一定会丢失数据?
Kafka什么情况的一定不会丢失数据?
Kafka数据写入降低百毫秒级?
Kafka的Topic分片规模的设置与延迟的关系?
80%通用场景 + 20%业务特性 = 相对完善和通用的故障场景
要区分现象和原因,列举的是现象而非原因
chaosmonkey 第一版里面有一些破坏性的shell脚本可以用
节点故障
各个角色单独关闭至少一台机器,直至服务故障(线下)
各个角色同时关闭一台机器
任意一个交换机故障
单机资源:CPU、MEM、NET、DISK、IO、Ulimit
磁盘
磁盘空间写满
磁盘故障(只读)
磁盘IO饱和
节点故障,网络分区,丢包和慢速网络————目的是找出RabbitMQ集群丢失消息的方式和时间
第三方依赖:数据库、缓存、共享存储、上下游、DNS、LB、基础设施等
业务特性
集群Topic leader丢失
集群中的单个Topic分区异常的多
集群中总的分区过多
集群出现大面积的分区迁移
容量
数据写入量——单条record信息过大
消息写入量——批量消息过多
Kafka故障因子来自如下几个方面:
生产者外部—每秒数据写入量(控制参数:record batch-size和throughput,thread_pool)
自身内部—磁盘空间,节点数丢失,业务饱和度(分片数量,IO饱和度,内存不足?)
依赖关系模块—Zookeeper问题
Kafka故障指标:
功能不可用
出现消息丢失——Topic没有leader
消息延迟——大于100ms
以此梳理出Kafka的故障场景:
数据写入量——单条record信息过大
消息写入量——批量消息过多
集群磁盘空间被写满——单机被打满后集群会做什么事情
集群节点丢失1/5
集群节点丢失1/3
集群节点丢失1/2
集群Topic leader丢失
集群中的单个Topic分区异常的多
集群中总的分区过多
集群出现大面积的分区迁移——磁盘IO饱和
集群磁盘故障
Zookeeper集群功能不可用
12-1.ZK集群节点丢失1/2
12-2.ZK集群被频繁请求
12-3.ZK集群leader选举
故障场景演练
数据写入量——单条record信息过大
考虑如下场景的比较,比较消息写入延迟率
(1)topic:test1(6,1),–record-size=838860(0.8M)–throughput 4096
(1)topic:test1(6,1),–record-size=4(KB)–throughput 4096
考虑到集群默认有消息最大请求限制(message.max.bytes=1000000,1MB以内)。
org.apache.kafka.common.errors.NotLeaderForPartitionException: This server is not the leader for that topic-partition.
2.消息写入量——批量消息过多
(1)topic:test1(6,1),–record-size=4(KB),–throughput 1000
(2)topic:test1(6,1),–record-size=4(0.1M),–throughput 100000000
org.apache.kafka.common.errors.NotLeaderForPartitionException: This server is not the leader for that topic-partition.
以及另外一种报错:
org.apache.kafka.common.errors.TimeoutException: Expiring 1 record(s) for test2-0 due to 30001 ms has passed since last append
极端场景为:
topic:test1(6,1),–record-size=838860(0.8M),–throughput 100000000
3.Broker 数据盘没有空间导致kafka自动关闭
[2018-10-29 16:50:16,939] FATAL [Replica Manager on Broker 0]: Halting due to unrecoverable I/O error while handling produce request: (kafka.server.ReplicaManager) kafka.common.KafkaStorageException: I/O exception in append to log 'test2-0' at kafka.log.Log.append(Log.scala:349) at kafka.cluster.Partition$$anonfun$10.apply(Partition.scala:443) at kafka.cluster.Partition$$anonfun$10.apply(Partition.scala:429) at kafka.utils.CoreUtils$.inLock(CoreUtils.scala:234) at kafka.utils.CoreUtils$.inReadLock(CoreUtils.scala:240) at kafka.cluster.Partition.appendMessagesToLeader(Partition.scala:429) at kafka.server.ReplicaManager$$anonfun$appendToLocalLog$2.apply(ReplicaManager.scala:407) at kafka.server.ReplicaManager$$anonfun$appendToLocalLog$2.apply(ReplicaManager.scala:393) at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234) at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234) at scala.collection.mutable.HashMap$$anonfun$foreach$1.apply(HashMap.scala:99) at scala.collection.mutable.HashMap$$anonfun$foreach$1.apply(HashMap.scala:99) at scala.collection.mutable.HashTable$class.foreachEntry(HashTable.scala:230) at scala.collection.mutable.HashMap.foreachEntry(HashMap.scala:40) at scala.collection.mutable.HashMap.foreach(HashMap.scala:99) at scala.collection.TraversableLike$class.map(TraversableLike.scala:234) at scala.collection.AbstractTraversable.map(Traversable.scala:104) at kafka.server.ReplicaManager.appendToLocalLog(ReplicaManager.scala:393) at kafka.server.ReplicaManager.appendMessages(ReplicaManager.scala:330) at kafka.server.KafkaApis.handleProducerRequest(KafkaApis.scala:436) at kafka.server.KafkaApis.handle(KafkaApis.scala:78) at kafka.server.KafkaRequestHandler.run(KafkaRequestHandler.scala:60) at java.lang.Thread.run(Thread.java:745) Caused by: java.io.IOException: No space left on device at sun.nio.ch.FileDispatcherImpl.write0(Native Method) at sun.nio.ch.FileDispatcherImpl.write(FileDispatcherImpl.java:60) at sun.nio.ch.IOUtil.writeFromNativeBuffer(IOUtil.java:93) at sun.nio.ch.IOUtil.write(IOUtil.java:65) at sun.nio.ch.FileChannelImpl.write(FileChannelImpl.java:211) at kafka.message.ByteBufferMessageSet.writeFullyTo(ByteBufferMessageSet.scala:304) at kafka.log.FileMessageSet.append(FileMessageSet.scala:354) at kafka.log.LogSegment.append(LogSegment.scala:97) at kafka.log.Log.append(Log.scala:409) ... 22 more
8.集群中的单个Topic分区异常的多
考虑如下场景的比较,比较消息写入延迟率
(1-1)topic:test1(6000,1),–record-size=838860(0.8M)–throughput 100000000
org.apache.kafka.common.errors.NotLeaderForPartitionException: This server is not the leader for that topic-partition.
(1-2)topic:test1(6000,1),–record-size=838860(0.8M)–throughput 1000000
(1-3)topic:test1(6000,1),–record-size=4(KB)–throughput 100000000
(1-4)topic:test1(6000,1),–record-size=4(KB)–throughput 100000000
10.集群出现大面积的分区迁移——磁盘IO饱和
11.Zookeeper集群功能不可用
