链表使用时的疑惑:
首先定义一个头结点head, 结点pNode
1. pNode->next = head->next
根据结点定义,我们知道next代表个当前结点的下一个结点。而在头插法中,我们首先定义了头结点。此时的链表,只有一个头结点,头结点也是尾结点。为了保证链表的正常,我们通常将尾结点的下一个结点指向nullptr,也就是next = nullptr。而在此时的情况是head->next = nullptr。现在插入了一个结点pNode。此时pNode变为了尾结点,将pNode的下一个结点指向nullpte:pNode->next = nullptr ( head->next )。然后将pNode结点连接到head的下一个结点,head->next = pNode。而在之后的添加中,head->next指向的是第一个结点的位置。
文章目录
单链表
一、单链表模型
struct SinglyListNode
{
int val;
SinglyListNode* next;
SinglyListNode(int x) : val(x), next(NULL) {}
};
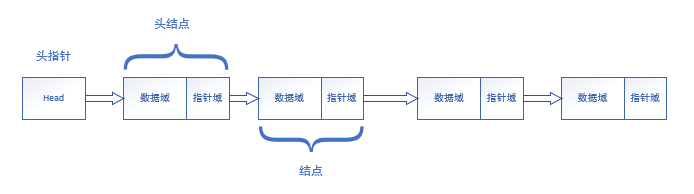
二、头指针和头结点
头指针
- 头指针是指链表第一个节点的数据域的指针,若链表有头结点,则是指向头结点的指针。
- 头指针具有标识作用,所以常用头指针冠以链表的名字。
- 无论链表是否为空,头指针均不为空。头指针是链表的必要元素。
头结点
- 头节点是为了操作的统一和方便而设立的,放在第一元素的节点之后,其数据与一般无意义(也可存放链表的长度)。
- 有了头结点后,对在第一个元素结点前插入结点和删除第一个结点,其操作与对其它结点的操作统一了。
- 头结点不一定是链表的必须要素。
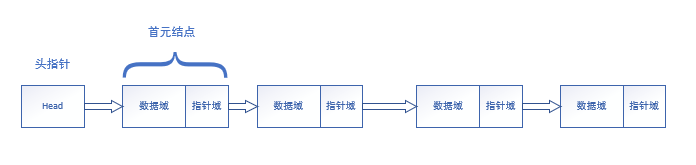
没有头结点的单链表是这样的:
三、创建单链表
参照:https://blog.csdn.net/songsong2017/article/details/88024883
1)带头结点的链表

1. 头插法

// 头插法
ListNode* CreateListHead(int nLen)
{
if (nLen < 1)
{
return nullptr;
}
// 创建头结点 - 数据域没有意义,可以标识为链表长度
ListNode* head = new ListNode(nLen);
// 此时头结点即是尾节点,尾结点赋空,防止出错
head->next = nullptr;
ListNode* s = nullptr;
srand(unsigned(time(0)));
while (nLen)
{
s = new ListNode(rand());
// 把指针插到链表中
s->next = head->next; // 这里 head - > next 其实就是结点1
head->next = s;
nLen--;
}
return head;
}
2. 尾插法

// 尾插法
ListNode* CreateListEnd(int nLen)
{
if (nLen < 1)
{
return nullptr;
}
// 创建头结点 - 数据域没有意义,可以标识为链表长度
ListNode* head = new ListNode(nLen);
ListNode* pTemp = head;
// 此时头结点即是尾节点,尾结点赋空,防止出错
head->next = nullptr;
ListNode* s = nullptr;
srand(unsigned(time(0)));
while (nLen)
{
s = new ListNode(rand());
// 将结点链接到上一个结点
pTemp->next = s;
// 此时当前节点为新添加的结点
pTemp = s;
nLen--;
}
// 尾结点的下一个结点赋空
s->next = nullptr;
return head;
}
2)无头结点的链表

1. 头插法

// 头插法
ListNode* CreateListNoHead(int nLen)
{
if (nLen < 1)
{
return nullptr;
}
srand(unsigned(time(0)));
// 新建一个结点
ListNode* pNode = new ListNode(rand());
pNode->next = nullptr;
ListNode* s = nullptr;
while (nLen)
{
s = new ListNode(rand());
// 将新建的结点下一个结点指向之前的一个结点
s->next = pNode;
// 移动当前结点
pNode = s;
nLen--;
}
return pNode;
}
2. 尾插法

ListNode* CreateListNoEnd(int nLen)
{
if (nLen < 1)
{
return nullptr;
}
srand(unsigned(time(0)));
ListNode* pNode = new ListNode(rand());
pNode->next = nullptr;
// 用于插入的指针结点
ListNode* pTemp = pNode;
ListNode* s = nullptr;
while (nLen)
{
s = new ListNode(rand());
// 将新建结点赋予到之前结点的下一个结点
pTemp->next = s;
// 移动当前结点
pTemp = s;
}
// 将尾结点赋空
pTemp->next = nullptr;
return pNode;
}
四、单链表基本操作
1. 查找操作
因为链表不支持随机访问,即链表的存取方式是顺序存取的(注意“存储”与“存取”是两个不一样的概念),所以要查找某结点,必须通过遍历的方式查找。例如:如果想查找第5个结点,必须先遍历走过第1~4个结点,才能得到第5个结点。
ListNode* SearchNode(ListNode* pNode, int elem)
{
ListNode* pTemp = pNode;
// 判断条件为pTemp->next,因为尾结点的next是nullptr,所以执行到尾结点停止
while (pTemp->next)
{
// 头结点不含有数据域,从第一个结点开始
pTemp = pTemp->next;
if (pTemp->val == elem)
{
return pTemp;
}
}
return nullptr;
}
2. 修改某结点的数据域
要修改某结点的数据域,首先通过遍历的方法找到该结点,然后直接修改该结点的数据域的值。
ListNode* ReplaceData(ListNode* pNode, int nPos, int elem)
{
// 引入一个中间变量,用于循环变量链表
ListNode* pTemp = pNode;
// 记录当前节点位置
int i = 1;
while (pTemp->next)
{
// 指向第一个结点
pTemp = pTemp->next;
if (i == nPos)
{
pTemp->val = elem;
return pNode;
}
else
{
i++;
}
}
if (i < nPos)
{
cout << "输入正确的位置!" << endl;
return nullptr;
}
}
3. 往链表中插入结点
ListNode* InsertNode(ListNode* pNode, int nPos, int elem)
{
ListNode* pTemp = pNode;
int i = 0;
// 1. 首先要找到插入结点的上一个结点,即第pos - 1个结点
while ((pTemp != nullptr) && (i < (nPos - 1)))
{
pTemp = pTemp->next;
++i;
}
// 2. 错误处理:链表为空或者插入位置不存在
if ((pTemp == nullptr) || (i > (nPos - 1)))
{
cout << "插入错误" << endl;
return pNode;
}
// 创建新节点
ListNode* s = new ListNode(elem);
s->next = pTemp->next;
pTemp->next = s;
return pNode;
}
4. 删除结点
ListNode* DeleteNode(ListNode* pNode, int nPos, int elem)
{
ListNode* pTemp = pNode;
int i = 0;
// 1. 首先要找到删除结点的上一个结点,即第pos - 1个结点
while ((pTemp != nullptr) && (i < (nPos - 1)))
{
pTemp = pTemp->next;
++i;
}
// 2. 错误处理:链表为空或者插入位置不存在
if ((pTemp == nullptr) || (i > (nPos - 1)))
{
cout << "插入错误" << endl;
return pNode;
}
// 定义一个指针,指向被删除结点
ListNode* DelNode = pTemp->next;
// 删除结点的上一个结点的指针域指向删除结点的下一个结点
pTemp->next = DelNode->next;
// 手动释放该结点,防止内存泄露
free(DelNode);
//防止出现野指针
DelNode = nullptr;
return pNode;
}
5. 打印链表
void PrintList(ListNode* pNode)
{
ListNode* pTemp = pNode;
int i = 1;
while (pTemp->next)
{
pTemp = pTemp->next;
cout << pTemp->val << "\t";
if ( !(i % 6) )
{
cout << "\n";
}
i++;
}
cout << endl;
}
双指针技巧
单链表问题由于顺序遍历的特性,有时候执行一些操作的时候会出现问题看似需要多次遍历才能获取数据。使用双指针法能在一次遍历中获取更多的数据,也可以节约更多的额外控件。
“双指针”就是用一个快指针一个慢指针同时进行单链表的顺序扫描。如此就可以使用快指针的时间差给慢指针提供更多的操作信息。
一、环形链表
判断链表中是否有环:

传统思路来看,遍历链表,如果出现重复的结点,那么它就是环形的。
bool hasCycle(ListNode* head)
{
// 选用set容器,因为它的find方法,会更好的帮助我们判断容器中是否存在某数
set<ListNode*> sList;
// 如果链表为空
if (!head)
{
return false;
}
while (head->next)
{
// 如果存在则是环形,否则将结点添加进容器
if (sList.find(head) != sList.end())
{
return true;
}
else
{
sList.insert(head);
head = head->next;
}
}
return false;
}
显然传统思路,占用的额外空间很多。这时候我们想象两个人以不同的速度在跑道上跑,如果这个跑道是环形的,那么总会有一个时间,跑的快的人会追上跑得慢的。依照这种思路我们可以定义两个步长不一样的指针,即是快慢指针。
bool hasCycleDoubleNode(ListNode* head)
{
// 定义快慢指针
ListNode* FastNode = head;
ListNode* SlowNode = head;
if (!head)
{
return false;
}
while (FastNode && FastNode->next)
{
// 为快慢指针设置不同的步长
SlowNode = SlowNode->next;
FastNode = FastNode->next->next;
if (SlowNode == FastNode)
{
return true;
}
}
return false;
}
二、环形链表II
给定一个链表,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。

使用传统的思路依然可以解决问题,而且很直观。但是会消耗很打的空间。
在不消耗空间的情况下,我们依然可以使用双指针的方式解决问题。
思路:快慢指针相遇时,让其中一个指针与头指针一起一步一步地走,相遇时侯就是环的入口点。
解法参考:https://blog.csdn.net/zhaohong_bo/article/details/91595336
数学原理:
设slow指向走了k个结点,那么fast指针就走了2k个结点(因为fast每次走两结点,slow每次走一个结点)
设链表开始到链表入口处结点数为L
设环的大小为c
设slow指针最后的位置相对于链表入口结点的位置差为x
这样的带环链表,若L比较长,且c比较小,那么当slow指针进环前,fast指针就可能会比slow指针多走n圈。所以对于slow指针k=L+x,对于fast指针2k=L+x+nc。两式联立能得到nc-x=L。若slow指针再走nc-x的结点个数,那么它一定指向环的入口结点。并且slow的指针走的结点个数恰好和L相等,所以当head指针从头开始遍历,slow指针同时遍历,当他们指向同一结点时,这个节点便是环的入口。
ListNode* detectCycle(ListNode* head)
{
if ( !head || !head->next)
{
return nullptr;
}
// 定义两个快慢指针
ListNode* FastNode = head->next->next;
ListNode* SlowNode = head->next;
// 判断是否有环
while (FastNode)
{
if ( !FastNode->next)
{
return nullptr;
}
if (FastNode == SlowNode)
{
break;
}
FastNode = FastNode->next->next;
SlowNode = SlowNode->next;
}
// 无环
if (!FastNode)
{
return nullptr;
}
ListNode* pStart = head;
while (pStart != SlowNode)
{
pStart = pStart->next;
SlowNode = SlowNode->next;
}
return SlowNode;
}
三、相交链表
找到两个单链表相交的起始节点。

解法参考:https://www.cnblogs.com/yxh-amysear/p/9608796.html
传统思路,两个链表长为x,y。如果x较长,则让x先走x-y步,然后再一起走,如果相交,那么两者肯定会相遇。
LinkNode* getIntersectionNode(LinkNode* headA, LinkNode* headB)
{
if ( !headA || !headB )
{
return nullptr;
}
LinkNode* pA = headA;
LinkNode* pB = headB;
int nALen, nBLen;
nALen = nBLen = 0;
// 计算两个链表的长度
while (pA->next)
{
pA = pA->next;
nALen++;
}
while (pB->next)
{
pB = pB->next;
nBLen++;
}
pA = headA;
pB = headB;
int nStep = nBLen > nALen ? (nBLen - nALen) : (nALen - nBLen);
while (nStep--)
{
if (nBLen > nALen)
{
pB = pB->next;
}
else
{
pA = pA->next;
}
}
while ( pB && pB != pA)
{
pB = pB->next;
pA = pA->next;
}
return pA;
}
逻辑思路分为两轮:
- ListA + ListB = A + intersection + Bb + intersection
- ListB + ListA = Bb + intersection + A + intersection
用大A表示ListA里面非共有 Bb表示listB里面非共有的,可以看到在第二个intersection的开头两个链表长度是一样的,必然相等
所以我们可以遍历A再遍历B,另一个遍历B再遍历A,两个指针必定在第二个交集处相遇,没有交集就是空指针。如果两个链表存在相交,它们末尾的结点必然相同。因此当 pApA/pBpB 到达链表结尾时,记录下链表 A/B 对应的元素。若最后元素不相同,则两个链表不相交。
LinkNode* getIntersectionNode(LinkNode* headA, LinkNode* headB)
{
if ( !headA || !headB)
{
return nullptr;
}
LinkNode* pA = headA;
LinkNode* pB = headB;
// 在这里第一轮体现在pA和pB第一次到达尾部会移向另一链表的表头
// 而第二轮体现在如果pA或pB相交就返回交点, 不相交最后就是null==null
// 因为第二轮之后,pA和pB必然同时指向两个链表的末尾。它们的next都为null。所以null = null
while (pA != pB)
{
pA = pA == nullptr ? headB : pA->next;
pB = pB == nullptr ? headA : pB->next;
}
return pA;
}
四、删除链表的倒数第N个节点
给定一个链表,删除链表的倒数第 n 个节点,并且返回链表的头结点。
图解:https://blog.csdn.net/jrrrj/article/details/81362741
我们注意到这个问题可以容易地简化成另一个问题:删除从列表开头数起的第 (L - n + 1)(L−n+1) 个结点,其中 LL 是列表的长度。只要我们找到列表的长度 LL,这个问题就很容易解决。
LinkNode* removeNthFromEnd(LinkNode* head, int n)
{
// 无头链表,那么如果要删除首元结点,那么就不太容易了
// 我们可以用一个链表存储这个链表
LinkNode* StoreTemp = new LinkNode(0);
StoreTemp->next = head;
LinkNode* pTemp = head;
// 第一个遍历,计算链表的长度
int nLen = 0;
while (pTemp)
{
pTemp = pTemp->next;
nLen++;
}
// 第二次遍历,删除指定结点
pTemp = StoreTemp;
nLen -= n;
while (nLen--)
{
pTemp = pTemp->next;
}
LinkNode* DelTemp = pTemp->next;
pTemp->next = DelTemp->next;
delete DelTemp;
DelTemp = nullptr;
return StoreTemp->next;
}
典型的利用双指针法解题。首先让指针first指向头节点,然后让其向后移动n步,接着让指针sec指向头结点,并和first一起向后移动。当first的next指针为NULL时,sec即指向了要删除节点的前一个节点,接着让first指向的next指针指向要删除节点的下一个节点即可。注意如果要删除的节点是首节点,那么first向后移动结束时会为NULL,这样加一个判断其是否为NULL的条件,若为NULL则返回头结点的next指针。
LinkNode* removeNthFromEnd(LinkNode* head, int n)
{
LinkNode* StoreTemp = new LinkNode(0);
StoreTemp->next = head;
// 定义快慢指针
LinkNode* FastNode = StoreTemp;
LinkNode* SlowNode = StoreTemp;
// 先让它走
for (int i = 0; i <= n; i++)
{
FastNode = FastNode->next;
if (!FastNode)
{
return nullptr;
}
}
while (FastNode)
{
FastNode = FastNode->next;
SlowNode = SlowNode->next;
}
SlowNode->next = SlowNode->next->next;
return StoreTemp->next;
}
链表的经典问题
一、反转链表
参考:https://www.imooc.com/article/274692
注意观察示例:1->2->3->4->5->NULL的反转可以看成:NULL<-1<-2<-3<-4<-5。会发现链表的反转基本上就是箭头的方向的反转,即节点前驱和后继互换角色。我们定义三个变量cur,pre和next分别表示当前节点,以及其前驱后继。cur初始化为head,其他初始化为NULL。我们从头节点1开始遍历,1的next和pre原来分别是2和NULL(初始值)互换后1的next和pre变成NULL和2,依次这样遍历下去。注意最后应该返回pre,不是cur。遍历结束后cur的值是NULL。
LinkNode* reverseList(LinkNode* head)
{
// 定义前驱结点、当前节点
LinkNode* prev = nullptr;
LinkNode* curr = head;
// 遍历,直到最后
while (curr)
{
// 记录下后继结点
LinkNode* nextTemp = curr->next;
// 反转
curr->next = prev;
prev = curr;
curr = nextTemp;
}
return prev;
}
上述的递归解法
LinkNode* reverseList(LinkNode* head)
{
if (!head || !head->next)
{
return head;
}
LinkNode* pTemp = reverseList(head->next);
head->next->next = head;
head->next = nullptr;
return pTemp;
}
迭代头插法,新建一个链表,将原始的链表元素通过头插法,逐一插入,也可以额达到反转的效果。
LinkNode* reverseList(LinkNode* head)
{
//迭代头插法,将元素插入头,前面插入的就会被往后挤
LinkNode* StoreTemp = new LinkNode(0);
StoreTemp->next = NULL;
LinkNode* Cur = head;
LinkNode* pTemp = nullptr;
while (pTemp)
{
// 取出节点
pTemp = Cur;
// 链表后移
Cur = Cur->next;
pTemp->next = StoreTemp->next;
StoreTemp->next = pTemp;
}
return StoreTemp->next;
}
