记录贴。作业为python123的课程。
测验1: Python基本语法元素 (第1周)
1、Guido van Rossum正式对外发布Python版本的年份是:1991年
December, 1989 Implementation started
1990 Internal releases at CWI
February 20, 1991 0.9.0 (released to alt.sources)
February, 1991 0.9.1
鉴于Internal release不算对外发布,普遍认为Python语言诞生于1991年。
2、以下关于Python语言中“缩进”说法正确的是:
缩进在程序中长度统一且强制使用。
Python语言的缩进只要统一即可,不一定是4个空格(尽管这是惯例)。
3、IPO模型:input、progress、output
4、字符串是一个字符序列,给字符串s,以下表示s从右侧向左第三个字符的是:s[-3]
字符串有正向递增和反向递减两套序号体系
5、 以下不是Python语言合法命名的是:5MyGod
合法命名的首字符不能是数字。
编程作业
1、Hello World的条件输出
获得用户输入的一个整数,参考该整数值,打印输出"Hello World",要求:
如果输入值是0,直接输出"Hello World"
如果输入值大于0,以两个字符一行方式输出"Hello World"(空格也是字符)
如果输入值小于0,以垂直方式输出"Hello World"
a=int(input())
s='Hello World'
if a==0:
print(s)
elif a>0:
for i in range(0,len(s),2):
print(s[i:i+2])
elif a<0:
for i in s:
print(i)
方法2:
n = eval(input())
if n == 0:
print("Hello World")
elif n > 0:
print("He\nll\no \nWo\nrl\nd")
else:
for c in "Hello World":
print(c)
2、数值运算
获得用户输入的一个字符串,格式如下:
M OP N
其中,M和N是任何数字,OP代表一种操作,表示为如下四种:+, -, *, /(加减乘除)
根据OP,输出M OP N的运算结果,统一保存小数点后2位。
注意:M和OP、OP和N之间可以存在多个空格,不考虑输入错误情况。
s=input().split(' ')
#print(s,type(s))
if len(s)==1:
print('{:.2f}'.format(eval(s[0])))
else:
for i in s[:]:
if i == "":
s.remove(i)
# print(s,s[1])
if s[1] == '+':
x = float(s[0]) + float(s[2])
elif '-'in s[1]:
if s[1]=='-':
x = float(s[0]) - float(s[2])
else:
x=eval(s[0])+float(s[1])
elif s[1] == '*':
x = float(s[0]) * float(s[2])
elif s[1] == '/':
x = float(s[0]) / float(s[2])
print('{:.2f}'.format(x))
参考答案:
s = input()
print("{:.2f}".format(eval(s)))
eval果然很强大
测验2: Python基本图形绘制 (第2周)
1、import只有三种使用方法,以turtle库为例:
import turtle
from turtle import setup 或 from turtle import *
import turtle as t (其中t是别名,可以更换其他名称)
2、turtle坐标系的原点默认在屏幕正中间
3、画布正右方是turtle绘图中角度坐标系的绝对0度方向?
4、turtle.circle(-90,90)绘制一个半径为90像素的弧形,圆心在小海龟当前行进的右侧
circle(x, y) 表示 以x长度为半径,y为角度,当前方向左侧x出为圆心,画圆。其中x和y都可以是负数,相应取反。
5、turtle.pendown()只是放下画笔,并不绘制任何内容。
6、turtle.done()用来停止画笔绘制,但绘图窗体不关闭
编程作业
turtle八边形绘制
描述:使用turtle库,绘制一个八边形。
import turtle as t
t.pensize(2)
for i in range(8):
t.fd(100)
t.left(45)
turtle八角图形绘制
描述:使用turtle库,绘制一个八角图形。
import turtle as t
t.pensize(2)
for i in range(8):
t.fd(100)
t.left(135)
测验3: 基本数据类型 (第3周)
1、pow(x, 0.5)能够计算x的平方根,计算负数的平方根将产生:复数
2、以下关于字符串.strip()方法功能说明正确的是:去掉字符串两侧指定字符
"按照指定字符分割字符串为数组"对应功能是.split()
"替换字符串中特定字符"对应功能是.replace()
"连接两个字符串序列"对应功能是+操作符
3、字符串是一个连续的字符序列,哪个选项可以实现打印字符信息的换行?\n
4、val=pow(2,1000),请用一行代码返回val结果的长度值。len(str(val))
5、Python语言的整数类型
十进制:一般表示
二进制:0b 或 0B 开头
八进制:0o 或 0O 开头
十六进制:0x 或 0X 开头
6、
name="Python语言程序设计课程"
print(name[0],name[2:-2],name[-1])
P thon语言程序设计 程
s[N:M]表示对字符串s的切片操作,从N到M,但不包含M
7、
s='PYTHON'
print("{0:3}".format(s))
PYTHON
{0:3}表示输出的宽度是3,但如果字符串超过长度3,则以字符串长度显示。
编程作业
1、平方根格式化
获得用户输入的一个整数a,计算a的平方根,保留小数点后3位,并打印输出。
输出结果采用宽度30个字符、右对齐输出、多余字符采用加号(+)填充。
如果结果超过30个字符,则以结果宽度为准。
a=int(input())
print('{0:+>30.3f}'.format(a**0.5))
2、字符串分段组合
获得输入的一个字符串s,以字符减号(-)分割s,将其中首尾两段用加号(+)组合后输出。
a=input().split('-')
print('%s+%s'%(a[0],a[-1]))
测验4: 程序的控制结构 (第4周)
1、程序的三种基本结构:顺序、循环、分支
2、哪个选项关于循环结构的描述是错误的?死循环无法退出,没有任何作用
3、哪个选项是用来判断当前Python语句在分支结构中?缩进
4、关于try-except,哪个选项的描述是错误的?使用了异常处理,程序将不会再出错
编程作业
1、四位玫瑰数
四位玫瑰数是4位数的自幂数。自幂数是指一个 n 位数,它的每个位上的数字的 n 次幂之和等于它本身。
例如:当n为3时,有1^3 + 5^3 + 3^3 = 153,153即是n为3时的一个自幂数,3位数的自幂数被称为水仙花数。
请输出所有4位数的四位玫瑰数,按照从小到大顺序,每个数字一行。
def mgh(n):
n=str(n)
sum=0
for i in range(len(n)):
a=int(n[i])**4
sum+=a
if sum==int(n):
print(n)
for n in range(1000,10000):
mgh(n)
for i in range(1000, 10000):
t = str(i)
if pow(eval(t[0]),4) + pow(eval(t[1]),4) + pow(eval(t[2]),4) + pow(eval(t[3]),4) == i :
print(i)
2、100以内素数之和
求100以内所有素数之和并输出。
素数指从大于1,且仅能被1和自己整除的整数。
提示:可以逐一判断100以内每个数是否为素数,然后求和。
sum=0
for n in range(2,101):
m=int(n**0.5)
i=2
while i<=m:
if n%i==0:
break
i+=1
if i>m:
sum+=n
print(sum)
测验5: 函数和代码复用 (第5周)
1、函数的作用:增强代码可读性、复用代码、降低编程复杂度
2、关于函数调用描述正确的是:自定义函数调用前必须定义
3、模块内高耦合、模块间低耦合。
4、递归不提高程序执行效率。
任何递归程序都可以通过堆栈或队列变成非递归程序(这是程序的高级应用)。
5、def vfunc(*a, b) 是错误的定义:*a表示可变参数,可变参数只能放在函数参数的最后。
6、函数可以包含0个或多个return语句
7、以下关于递归函数基例的说法错误的是:每个递归函数都只能有一个基例
编程作业
1、随机密码生成
补充编程模板中代码,完成如下功能:
以整数17为随机数种子,获取用户输入整数N为长度,产生3个长度为N位的密码,密码的每位是一个数字。每个密码单独一行输出。
产生密码采用random.randint()函数。
import random
def genpwd(length):
x=random.randint(10**(length-1),10**length-1)
print(x)
length = eval(input())
random.seed(17)
for i in range(3):
genpwd(length)
2、连续质数计算
补充编程模板中代码,完成如下功能:
获得用户输入数字N,计算并输出从N开始的5个质数,单行输出,质数间用逗号,分割。
注意:需要考虑用户输入的数字N可能是浮点数,应对输入取整数;最后一个输出后不用逗号。
def prime(m):
if type(m)!=int:
m+=1
m=round(m)
x=0
while x<=4:
c = int(m ** 0.5)
i = 2
while i <= c:
if m % i == 0:
break
i += 1
if i > c:
print(m,end=',') if x<4 else print(m)
x+=1
m+=1
n = eval(input())
prime(n)
测验6: 组合数据类型 (第6周)
1、集合类型和字典类型最外侧都用{}表示,不同在于,集合类型元素是普通元素,字典类型元素是键值对。
字典在程序设计中非常常用,因此,直接采用{}默认生成一个空字典。
2、S和T是两个集合,哪个选项对S^T的描述是正确的?S和T的补运算,包括集合S和T中的非相同元素
3、关于Python组合数据类型,以下描述错误的是:序列类型是二维元素向量,元素之间存在先后关系,通过序号访问
4、序列s,哪个选项对s.index(x)的描述是正确的?返回序列s中元素x第一次出现的序号
5、给定字典d,哪个选项对x in d的描述是正确的?判断x是否是字典d中的键
编程作业:
1、数字不同数之和
获得用户输入的一个整数N,输出N中所出现不同数字的和。
例如:用户输入 123123123,其中所出现的不同数字为:1、2、3,这几个数字和为6。
a=input()
s=(str(set(a)).lstrip('{')).rstrip('}')
s=list(s)
#print(s,type(s))
sum=0
for i in s[:]:
if i in ["'", ',', ' ']:
s.remove(i)
#print(s)
for i in s:
sum+=int(i)
print(sum)
参考答案
n = input()
ss = set(n)
s = 0
for i in ss:
s += eval(i)
print(s)
2、人名最多数统计
编程模板中给出了一个字符串,其中包含了含有重复的人名,请直接输出出现最多的人名。
ls=s.split(' ')
for i in ls[:]:
if i in ['', '\n']:
ls.remove(i)
se=set(ls)
d1={}
d=d1.fromkeys(se,0)
for i in ls:
if i in d:
d[i]+=1
l,k=0,0
for i,j in d.items():
if j>k:
l,k=i,j
print(l)
参考答案
ls = s.split()
d = {}
for i in ls:
d[i] = d.get(i, 0) + 1
max_name, max_cnt = "", 0
for k in d:
if d[k] > max_cnt:
max_name, max_cnt = k, d[k]
print(max_name)
测验7: 文件和数据格式化 (第7周)
1、关于文件关闭的close()方法,哪个选项的描述是正确的?文件处理后可以不用close()方法关闭文件,程序退出时会默认关闭
2、对于Python文件,以下描述正确的是:同一个文件可以既采用文本方式打开,也可以采用二进制方式打开
3、以下选项对文件描述错误的是:文件是程序的集合和抽象
4、关于CSV文件的描述,哪个选项的描述是错误的?CSV文件通过多种编码表示字符
编程作业
1、文本的平均列数
打印输出附件文件的平均列数,计算方法如下:
(1)有效行指包含至少一个字符的行,不计算空行;
(2)每行的列数为其有效字符数;
(3)平均列数为有效行的列数平均值,采用四舍五入方式取整数进位。
f=open('latex.log','r',encoding='utf-8')
s,m = 0,0
for line in f:#对文件逐行读取
line = line.strip('\n')
if len(line) == 0:
continue
s += 1
m+=len(line)
#print("共{}行,{}列".format(s,m))#总计多少有效行
print(round(m/s))
2、CSV格式清洗与转换
附件是一个CSV格式文件,提取数据进行如下格式转换:
(1)按行进行倒序排列;
(2)每行数据倒序排列;
(3)使用分号(;)代替逗号(,)分割数据,无空格;
按照上述要求转换后将数据输出。
f = open("data.csv")
ll=[]
for line in f:
line = line.strip("\n")
line=line.replace(' ','')
ls = line.split(",")
ls = ls[::-1]
ls=";".join(ls)
ll.insert(0,ls)
for line in ll:
print(line)
f.close()
测验8: 程序设计方法学 (第8周)
1、关于os.path子库,以下选项中用来计算相对路径的函数是:os.path.relpath(path)
2、以下选项对计算思维本质描述正确的是:抽象和自动化
3、关于计算思维,以下选项描述正确的是:计算思维是基于计算机的思维模式
4、自顶向下设计主要由下列哪个语法元素实现?函数
5、关于Python的os库,以下选项描述正确的是:os库提供了路径操作、进程管理等若干类功能
6、以下选项关于计算生态描述错误的是:高质量计算生态需要顶层设计的参与才能保障
7、关于用户体验,以下选项描述正确的是:编程只是手段,程序最终为人类服务,用户体验很重要
8、关于os库,以下选项中可以启动进程执行程序的函数是:os.system()
编程作业:
1、英文字符的鲁棒输入
获得用户的任何可能输入,将其中的英文字符进行打印输出,程序不出现错误。
s=input()
x=''
for i in s:
if 65<=ord(i)<=90 or 97<=ord(i)<=122:
x+=i
print(x)
2、数字的鲁棒输入
获得用户输入的一个数字,可能是浮点数或复数,如果是整数仅接收十进制形式,且只能是数字。对输入数字进行平方运算,输出结果。
要求:
(1)无论用户输入何种内容,程序无错误;
(2)如果输入有误,请输出"输入有误"。
try:
x = input()
if 'j'in x or '.'in x or x.isdigit() :
x=eval(x)
print(x ** 2)
except:
print('输入有误')
测验9: Python计算生态纵览 (第9周)
1、以下选项不是Python图形用户界面方向第三方库的是:Vizard是虚拟现实第三方库。
2、以下选项不是Python文本处理方向第三方库的是:pyovr是增强现实开发库。
3、以下选项不是Python数据可视化方向第三方库的是:Pyramid是Web开发框架库。
4、以下选项不是Python数据分析方向第三方库是:Scrapy是网络爬虫库
5、以下选项不是Python网络应用开发方向第三方库的是:numpy是多维度数据处理第三方库。
6、以下选项不是Python人工智能方向第三方库的是:Seaborn是数据可视化第三方库。
7、以下选项不是Python网络爬虫方向第三方库的是:Python-Goose是Web提取第三方库。
8、以下选项不是Python Web信息提取方向第三方库的是:wxPython是GUI第三方库。
9、以下选项不是Python游戏开发方向第三方库的是:aip是baidu的人工智能功能Python访问接口。
10、以下选项不是Python网站开发框架方向第三方库的是:redis-py是redis数据的Python访问接口。
编程作业:
1、系统基本信息获取
获取系统的递归深度、当前执行文件路径、系统最大UNICODE编码值等3个信息,并打印输出。
输出格式如下:
RECLIMIT:<深度>, EXEPATH:<文件路径>, UNICODE:<最大编码值>
提示:请在sys标准库中寻找上述功能。
import sys
print("RECLIMIT:{}, EXEPATH:{}, UNICODE:{}".format(sys.getrecursionlimit(), sys.executable, sys.maxunicode))
2、二维数据表格输出
tabulate能够对二维数据进行表格输出,是Python优秀的第三方计算生态。
参考编程模板中给定的数据和代码,编写程序,能够输出如下风格效果的表格数据。
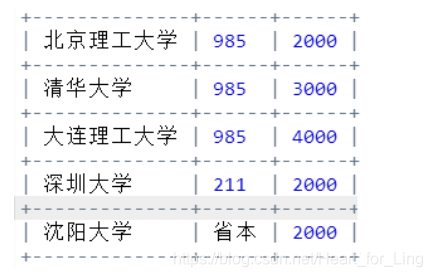
from tabulate import tabulate
data = [ ["北京理工大学", "985", 2000], \
["清华大学", "985", 3000], \
["大连理工大学", "985", 4000], \
["深圳大学", "211", 2000], \
["沈阳大学", "省本", 2000], \
]
print(tabulate(data, tablefmt="grid"))
