java容器的继承关系图:
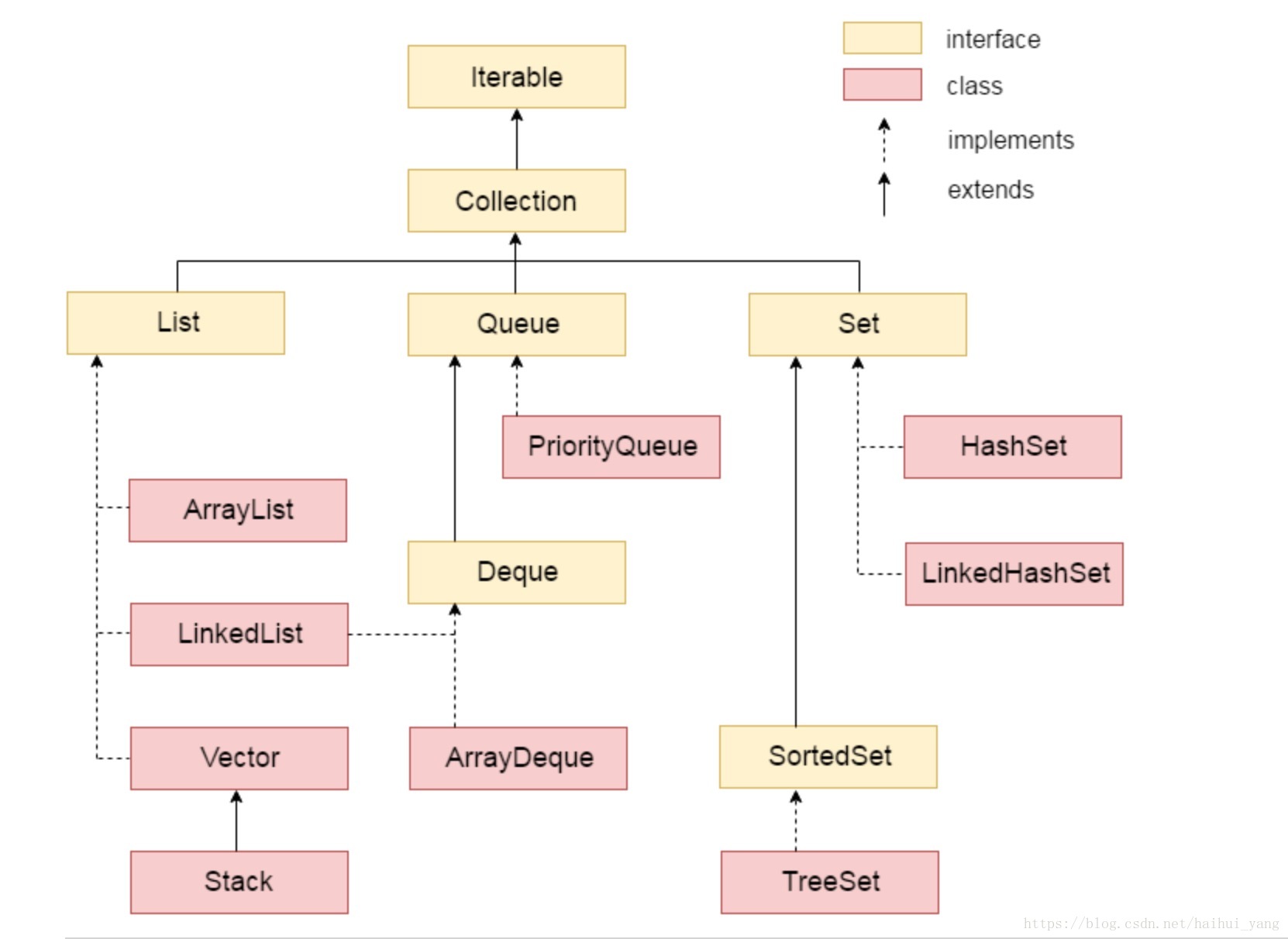
- 集合表示一组对象,称为其元素。有些集合允许重复元素,而另一些则不允许。有些是有序的,有些是无序的。JDK没有提供这个接口的任何直接实现:它提供了更具体的子接口(如
Set、List和Queue)的实现。
List
有序的元素序列,可以通过索引(即下标)访问元素。
####1.ArrayList(基于索引的动态数组)
-
实现了可变大小的数组,允许所有元素,包括
null值,底层使用数组(array)保存所有元素,所以随机访问很快,可以直接通过元素的下标值获取元素的值(size, isEmpty, get, set, iterator, listIterator这些方法的时间复杂度均为 O(1) ),但插入和删除较慢,因为需要移动array里的元素(即add, remove的时间复杂度为 O(n) ),未实现同步 -
每一个
ArrayList实例都有一个容量(capacity),使用Lists.newArrayList()创建的是一个capacity = 0的List,当在添加第一个元素的时候会扩展到默认的初始化容量(10),当对其添加的数据大于它的capacity就必须改变ArrayList的capacity(一般是原来大小的1.5倍),而这种resize操作是有开销的,所以如果事先知道数组的大小为actualSize,可以按照下面的方式初始化一个大小固定的ArrayList,以减去resize的开销:int actualSize = 100; List<Object> objectArrayList = Lists.newArrayListWithCapacity(actualSize); -
iterator()和listIterator(int)返回的迭代器是快速失败(fail-fast)的:如果在迭代器创建之后,原始的
List被修改了,迭代器会抛一个ConcurrentModificationException,原因是Iterator里的expectedModCount和List的modCount不一致。在迭代的时候如果需要修改List,只能通过Iterator的remove方法修改 -
从
array创建ArrayList的坑:Object[] array = new Object[10]; List<Object> arrayList1 = Lists.newArrayList(Arrays.asList(array)); List<Object> arrayList2 = Arrays.asList(array); //需要注意的是:Arrays.asList(array)返回的是一个fixed size array(上面的arrayList2),如果不用Lists.newArrayList(Arrays.asList(array))(上面的arrayList2)包装起来的话,对它进行add或remove操作就会报java.lang.UnsupportedOperationException
####2.LinkedList(双链表数据结构)
- 实现了
List接口,允许null值,底层使用链表保存所有元素(除了要存数据外,还需存next和pre两个指针,因此占用的内存比ArrayList多),因此,向LinkedList里面插入或移除元素时会特别快,但是对于随机访问方面相对较慢(需要遍历链表,遍历的时候会根据index选择从前往后或从后往前遍历,如果index < (size >> 1)则从前往后),无同步,想要实现同步可以这样:
```java
List list = Collections.synchronizedList(new LinkedList(...));
```
LinkedList还拥有了可以使其用作堆栈(stack),队列(queue)或者双向队列(deque)的方法(拥有pop,push, 从LinkedList的首部或尾部添加或删除元素等方法)。
3.Vector(实现了同步的ArrayList)
和 ArrayList 几乎一模一样,除开以下两点:
-
实现了同步,较
ArrayList有轻微的性能上的差距(一般不用它,而是使用ArrayList,在外部实现同步) -
二者的
resize的大小不一样:ArrayList是变为原来的1.5倍,而Vector为原来的2倍
4.Stack(java的堆栈实现是糟糕的,它继承了Vector)
stack 表示后进先出( LIFO )堆栈,继承于 Vector ,新增了五个方法:
-
push(E item):将item压入栈; -
pop():remove掉栈顶元素并返回remove掉的元素; -
peek():返回栈顶(Vector的最后一个元素)的第一个元素(无remove操作); -
empty():判断栈是否为空; -
search():返回查找到的离栈顶最近的元素的position; -
javadoc中建议:
Deque接口和它的实现提供了一个更完整、更一致的LIFO栈操作集,应该优先使用这个类。例如:Deque<Integer> stack = new ArrayDeque<Integer>();
ArrayList、LinkedList和Vector总结:
1.当集合内的元素需要频繁插入,删除操作时应使用LinkedList;当需要频繁查询时,使用ArrayList(大部分情况是使用ArrayList)
2.ArrayList和LinkedList都未实现同步,Vector是在ArrayList的基础上实现了同步,是线程安全的
3.相比而言,LinkedList占的内存要比ArrayList大(因为它必须维护下一个和前一个节点的链接)
###Set
不包含重复元素的集合。
1.HashSet
-
由
HashMap支持实现,无序,未实现同步,允许null值 -
add, remove, contains and size:这些方法的时间复杂度为O(1),迭代HashSet的时间与实际HashSet的size和内部支持实现的HashMap的capacity之和成线性关系。所以,如果对迭代性能敏感,就不要把HashSet的初始容量设置太高(或者负载因子太低)(实际上是减小HashMap的capacity值)。
2.LinkedHashSet
-
由
LinkedHashMap支持实现,有序(保证了元素的插入顺序),未实现同步,允许null值 -
与
HashSet相比:需要多维护一个linked list,所以总体上性能上会比HashMap稍微慢一点,但有一点例外:迭代LinkedHashSet的开销比迭代HashSet要小,原因是迭代LinkedHashSet只与size相关,而迭代HashSet还与capacity相关。
3.SortedSet
-
元素有序(按照自然排序或
Comparator排序) -
内部的元素都必须实现
Comparable接口,保证集合内部任意两个元素之间是可比较的 -
subSet(E fromElement, E toElement):返回该集合部分元素([from,to))的视图(view),操作该视图会映射到原集合上,而且该视图有限制:当添加一个此范围([from,to))之外的值会抛IllegalArgumentException。 -
headSet(E toElement):( < toElement):返回一个和subSet一样的视图([lowestElement, toElement)) -
tailSet(E fromElement):( >= fromElement):返回一个和subSet一样的视图([fromElement, highestElement])
4.TreeSet(SortedSet的实现)
-
基于
TreeMap的NavigableSet实现。未实现同步 -
add, remove and contains:时间复杂度为log(n)
###Queue
为在处理之前保存元素而设计的集合。提供了额外的插入( offer )、提取( poll )和检查( peek )操作,当操作失败时返回 null 或 false,而不是抛出异常。
一般来说,队列都是先进先出( FIFO )的方式,但也有例外:如优先级队列( PriorityQueue )。
队列实现通常不允许插入空元素,因为null被poll方法用作特殊返回值来指示队列不包含任何元素。
1.PriorityQueue
基于优先级堆(实际上是最小堆)实现,用数组存储堆
-
未实现同步(线程安全的优先级队列:
PriorityBlockingQueue),是无界队列,但有容量(capacity),添加元素时,如果容量不足,会自动增长。 -
iterator()方法不提供保证以特定的顺序遍历优先级队列中的元素。 -
offer, poll, remove() and add的时间复杂度为O(log(n)):往堆里增删元素 -
remove(Object)和contains(Object)为线性时间:java文档上是写的这两个方法的复杂度都是线性时间,即 O(n) ,因为是用数组存储堆的,所以contains就是遍历数组查找元素,因此,contains(Object)的复杂度是O(n)是没有问题的,但是我觉得remove(Object)操作的复杂度是O(n) + O(log(n)),即从数组里面找到它O(n),然后从堆里面删除它O(log(n))。(还是我理解错了,希望有大佬能够指导一下?) -
peek, element, and size为O(1):因为是取堆顶元素。
2.Deque
双向队列,支持两端元素的插入与删除。Deques也可以用作LIFO(后进先出)堆栈。这个接口应优先于传统的Stack类使用。
不支持通过索引访问元素。
虽然Deque实现不是严格要求禁止插入null值,强烈建议任何允许null元素的Deque实现的用户不要利用插入空值的能力,因为null被一些方法用作特殊返回值来指示该双端队列是空的。
3.ArrayDeque(Deque的实现)
-
未实现同步,不允许
null值。 -
当用作堆栈时,该类可能比
Stack快,并且在用作队列时比LinkedList快。
参考链接:
1.Create ArrayList from array
2.When to use LinkedList over ArrayList?
3.java中的容器讲解
4.Java ArrayList resize costs
5.collections in java
6.Why should I use Deque over Stack?
7.java文档
