16-2 比较锡特卡和死亡谷的气温 :在有关锡特卡和死亡谷的图表中,气温刻度反映了数据范围的不同。为准确地比较锡特卡和死亡谷的气温范围,需要在 y 轴上使用相同的刻度。为此,请修改图 16-5 和图 16-6 所示图表的 y 轴设置,对锡特卡和死亡谷的气温范围进行直接比较(你也可以对任何两个地方的气温范围进行比较)。你还可以尝试在一个图表中呈现这两个数据集。
16-3 降雨量 :选择你感兴趣的任何地方,通过可视化将其降雨量呈现出来。为此,可先只涵盖一个月的数据,确定代码正确无误后,再使用一整年的数据来运行它。
实现例子效果如下图:

代码:
import csv
from datetime import datetime
from matplotlib import pyplot as plt
filename_sitka = 'data/sitka_weather_2014.csv'
filename_death = 'data/death_valley_2014.csv'
# 获取日期、最高温度、最低温度、日降水量
def get_data(filename):
with open(filename) as f:
reader = csv.reader(f)
header_row = next(reader)
# print(header_row)
dates, highs, lows, precipitationIns = [], [], [], []
for row in reader:
try:
current_date = datetime.strptime(row[0], "%Y-%m-%d")
high = int(row[1])
low = int(row[3])
precipitationIn = float(row[19])
except ValueError:
print(current_date, 'missing data')
else:
dates.append(current_date)
highs.append(high)
lows.append(low)
precipitationIns.append(precipitationIn)
return {'dates': dates, 'highs': highs, 'lows': lows, 'precipitationIns': precipitationIns}
sitka_data = get_data(filename_sitka)
death_data = get_data(filename_death)
# 根据数据绘制图形
fig = plt.figure(dpi=128, figsize=(10, 6))
plt.plot(sitka_data['dates'], sitka_data['highs'], c='red', alpha=1)
plt.plot(sitka_data['dates'], sitka_data['lows'], c='blue', alpha=1)
plt.plot(sitka_data['dates'], sitka_data['precipitationIns'], c='green', alpha=1)
plt.plot(death_data['dates'], death_data['highs'], c='red', alpha=1)
plt.plot(death_data['dates'], death_data['lows'], c='blue', alpha=1)
plt.plot(death_data['dates'], death_data['precipitationIns'], c='green', alpha=1)
# plt.fill_between(sitka_data['dates'], sitka_data['highs'], sitka_data['lows'], facecolor='red', alpha=0.1)
# plt.fill_between(death_data['dates'], death_data['highs'], death_data['lows'], facecolor='blue', alpha=0.1)
# 设置图形的格式
title = "Daily high and low temperatures - 2014\nDeath Valley, CA"
plt.title(title, fontsize=20)
plt.xlabel('', fontsize=16)
# 绘制斜的日期标签
fig.autofmt_xdate()
plt.ylabel("Temperature (F)", fontsize=16)
plt.tick_params(axis='both', which='major', labelsize=16)
# 图例
plt.legend(('high', 'low', 'precipitationIn'))
plt.show()16-4 探索 :生成一些图表,对你好奇的任何地方的其他天气数据进行研究。
实现例子效果如下图:
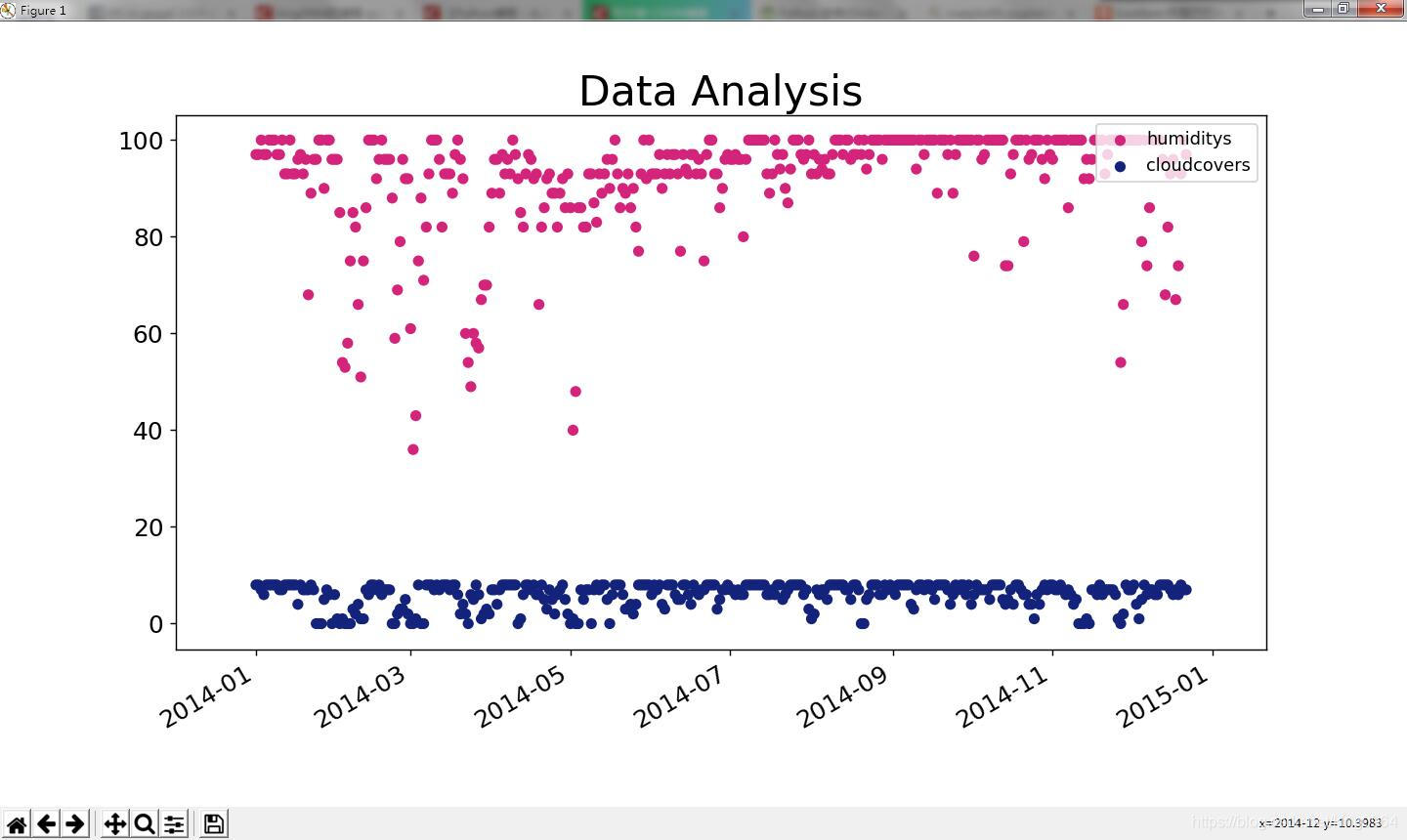
代码:
import csv
from datetime import datetime
from matplotlib import pyplot as plt
filename_sitka = 'data/sitka_weather_2014.csv'
with open(filename_sitka) as f:
reader = csv.reader(f)
header_row = next(reader)
dates, humiditys, cloudcovers = [], [], []
for row in reader:
try:
current_date = datetime.strptime(row[0], "%Y-%m-%d")
humidity = int(row[7])
cloudcover = int(row[20])
except ValueError:
print(current_date, 'missing data')
else:
dates.append(current_date)
humiditys.append(humidity)
cloudcovers.append(cloudcover)
fig = plt.figure(dpi=128, figsize=(10, 6))
# 显示图表
plt.scatter(dates, humiditys, c='#d4237a', edgecolor='none', s=40)
plt.scatter(dates, cloudcovers, c='#13227a', edgecolor='none', s=40)
# 设置图表标题并给坐标轴加上标签
# 日期斜显示
plt.title('Data Analysis', fontsize=24)
fig.autofmt_xdate()
plt.xlabel('', fontsize=14)
plt.ylabel('', fontsize=14)
# 设置刻度标记的大小
plt.tick_params(axis='both', which='major', labelsize=14)
# 图例(文本、文本大小、显示位置、圆点和文本距离)
plt.legend(('humiditys', 'cloudcovers'), fontsize=10, loc='upper right', handletextpad=0.5)
plt.show()16-5 涵盖所有国家 :本节制作人口地图时,对于大约 12 个国家,程序不能自动确定其两个字母的国别码。请找出这些国家,在字典 COUNTRIES 中找到它们的国别码;然后,对于每个这样的国家,都在 get_country_code() 中添加一个 if-elif 代码块,以返回其国别码:
if country_name == 'Yemen, Rep.'
return 'ye'
elif --snip--
将这些代码放在遍历 COUNTRIES 的循环和语句 return None 之间。完成这样的修改后,你看到的地图将更完整。
16-6 国内生产总值 : Open Knowledge Foundation 提供了一个数据集,其中包含全球各国的国内生产总值( GDP ),可在 http://data.okfn.org/data/core/gdp/ 找到这个数据集。请下载这个数据集的 JSON 版本,并绘制一个图表,将全球各国最近一年的 GDP 呈现出来。
数据下载地址效果图:

实现例子效果如下图:

代码:
country_codes.py(用来返回国别码,这里只处理了‘Yemen’情况,其它11个未确定的国别码可根据else的数据自行修改)。
from pygal_maps_world.i18n import COUNTRIES
def get_country_code(country_name):
""" 根据指定的国家,返回 Pygal 使用的两个字母的国别码 """
for code, name in COUNTRIES.items():
if country_name.find('Yemen') >= 0:
return 'ye'
elif name == country_name:
return code
else:
# 输出未确定国别码的国家
print(country_name)
# 如果没有找到指定的国家,就返回 None
return Noneworld_gdp.py(生成svg图表)。
因为pygal.i18n已经不存在了,改成了 pygal_maps_world,所以直接使用文章的“from pygal.i18n import COUNTRIES”会报错;
命令终端执行pip install pygal_maps_world,然后改成import pygal_maps_world.maps和wm = pygal_maps_world.maps.World()后可正常绘制图表。
import json
from country_codes import get_country_code
import pygal_maps_world.maps
from pygal.style import LightColorizedStyle as LCS, RotateStyle as RS
# 将数据加载到一个列表中
filename = 'data/gdp_json.json'
with open(filename) as f:
gdp_data = json.load(f)
# 创建一个包含gdp数据的字典
cc_gdp = {}
for gdp_dict in gdp_data:
if gdp_dict['Year'] == 2016:
country = gdp_dict['Country Name']
gdpValue = int(float(gdp_dict['Value']))
code = get_country_code(country)
if code:
cc_gdp[code] = gdpValue
# 根据gdp将所有的国家分成三组
cc_gdp_1, cc_gdp_2, cc_gdp_3 = {}, {}, {}
for cc, gdp in cc_gdp.items():
if gdp < 10000000000:
cc_gdp_1[cc] = gdp
elif gdp < 500000000000:
cc_gdp_2[cc] = gdp
else:
cc_gdp_3[cc] = gdp
# 看看每组分别包含多少个国家
print(len(cc_gdp_1), len(cc_gdp_2), len(cc_gdp_3))
wm_style = RS('#d95e07', base_style=LCS)
wm = pygal_maps_world.maps.World(style=wm_style)
wm.title = 'World GDP in 2016, by Country'
wm.add('0-10bn', cc_gdp_1)
wm.add('10bn-500bn', cc_gdp_2)
wm.add('>500bn', cc_gdp_3)
wm.render_to_file('data/world_gdp.svg')16-7 选择你自己的数据 :世界银行( The World Bank )提供了很多数据集,其中包含有关全球各国的信息。请访问 http://data.worldbank.org/indicator/ ,并找到一个你感兴趣的数据集。单击该数据集,再单击链接 Download Data 并选择 CSV 。你将收到三个 CSV 文件,其中两个包含字样 Metadata ,你应使用第三个 CSV 文件。编写一个程序,生成一个字典,它将两个字母的 Pygal 国别码作为键,并将你从这个文件中选择的数据作为值。使用 Worldmap 制作一个地图,在其中呈现这些数据,并根据你的喜好设置这个地图的样式。
数据下载地址效果图:

实现例子效果如下图:

代码:
country_codes.py(用来返回国别码,代码跟上面一样)。
children_out_school.py(生成svg图表)。
import csv
from country_codes import get_country_code
import pygal_maps_world.maps
from pygal.style import LightColorizedStyle as LCS, RotateStyle as RS
# 将数据加载到一个列表中
filename = 'data/children_out_school.csv'
with open(filename) as f:
reader = csv.reader(f)
header_row = next(reader)
# 创建一个包含gdp数据的字典
children_numbers = {}
for row in reader:
try:
country_name = row[0]
children_number = int(row[60])
except ValueError:
print(country_name, 'missing data')
else:
code = get_country_code(country_name)
if code:
children_numbers[code] = children_number
# 根据数量将所有的国家分成三组
children_number_1, children_number_2, children_number_3 = {}, {}, {}
for i, value in children_numbers.items():
if value < 1000:
children_number_1[i] = value
elif value < 10000:
children_number_2[i] = value
else:
children_number_3[i] = value
# 看看每组分别包含多少个国家
print(len(children_number_1), len(children_number_2), len(children_number_3))
wm_style = RS('#d95e07', base_style=LCS)
wm = pygal_maps_world.maps.World(style=wm_style)
wm.title = 'Children Out School in 2018, by Country'
wm.add('0-1000', children_number_1)
wm.add('1000-10000', children_number_2)
wm.add('>10000', children_number_3)
wm.render_to_file('data/children_numbers.svg')