网站离线日志分析(log analize)
一.概述:
1.1项目背景
某网站系统实时产生日志信息,记录用户对系统的访问信息,例如:IP地址,用户名称,访问时间,请求和响应信息,其中IP地址信息是表示全国各地用户的访问情况,对IP地址的详细分析,可以了解各个地区对该网站系统访问的活跃度,用以判断该网站公司对区域活动的推广情况和投入成本。本项目为网站运营方向常用技术案例。
网站日志流量分析系统之(日志收集)已将数据落地收集,根据网站日志流量分析系统中架构图,接下来要做的事情就是做离线分析,编写程序或通过手写HQ对数据进行清洗。
1.2任务
1)对日志进行清洗。
2)统计该时间段内的PV。
3)统计该时间段内的UV。
4)统计该时间段跳出用户信息
将获取到的结果存为本地文件result1、result2。
二.数据格式分析
IP: 记录客户端的ip地址, 222.68.172.190
user: 记录客户端用户名称, –
time: 记录访问时间与时区, [18/Sep/2013:06:49:57 +0000]
request: 记录请求的url与http协议, “GET /images/my.jpg HTTP/1.1”
status: 记录请求状态,成功是200, 200
pv: 记录一天之内访问的数量,也就意味着一条日志代表一次点击量
uv: 记录一天之内独立访客数量,同一个客户在一天之内多次访问只能记录一个uv
人均浏览页数: 平均每个独立访客产生的 PV。人均浏览页数=浏览次数/独立访客。体现网站对访客的吸引程度。
跳出率:指某一范围内单页访问次数或访问者与总访问次数的百分比。其中跳出指单页访问或访问者的次数,即在一次访问中访问者进入网站后只访问了一个页面就离开的数量。
退出率:指某一范围内退出的访问者与综合访问量的百分比。 其中退出指访问者离开网站的次数,通常是基于某个范围的。
三.数据处理方案
- 过滤格式不正确的记录;
- 对每一行的日志信息进行切分并且过滤清洗掉不符合规则的数据
- 通过对日志信息的分析,按照空格切分后,下标为10的是url
- 长度小于10的暂且认为是不符合规则的数据
- 创建分析后要存入数据的表
- Clean类(主要使用Spark core进行格式清洗得到(IP,和格式转化后的时间)
- Change(使用SparkSQL进行PV、IP、跳出用户的查询)
- Hour类(使用SparkSQL 对24小时访问量的统计)
数据处理流程
数据清理
四.代码
Clean类(主要使用Spark core进行格式清洗得到(IP,和格式转化后的时间)
public class Clean {
public static void main(String[] args) {
final SimpleDateFormat FORMAT = new SimpleDateFormat("d/MMM/yyyy:HH:mm:ss", Locale.ENGLISH);
final SimpleDateFormat dateformat1 = new SimpleDateFormat("yyyy-MM-dd-HH");
final SimpleDateFormat dateformat2 = new SimpleDateFormat("yyyy-MM-dd-HH:mm:ss");
// 配置信息
SparkConf conf = new SparkConf().setAppName("WordCountLocal").setMaster("local[4]");
// 上下文sc
JavaSparkContext sc = new JavaSparkContext(conf);
// 要处理文件的路径
JavaRDD<String> lines = sc.textFile("hdfs://s01:9000/usr/access1.log");
// 数据清洗(IP 时间)
JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterable<String> call(String line) throws Exception {
String lines = line.toString();
String IP = lines.split(" - ")[0].trim();
int getTimeFirst = lines.indexOf("[");
int getTimeLast = lines.indexOf("]");
String time = lines.substring(getTimeFirst + 1, getTimeLast).trim();
Date dt = null;
String d1 = null;
try {
dt = FORMAT.parse(time);
d1 = dateformat1.format(dt);
} catch (ParseException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return Arrays.asList(IP + " " + d1);
}
}).distinct();
JavaRDD<String> word = lines.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterable<String> call(String line) throws Exception {
String lines = line.toString();
String IP = lines.split(" - ")[0].trim();
int getTimeFirst = lines.indexOf("[");
int getTimeLast = lines.indexOf("]");
String time = lines.substring(getTimeFirst + 1, getTimeLast).trim();
Date dt = null;
String d2 = null;
try {
dt = FORMAT.parse(time);
d2 = dateformat2.format(dt);
} catch (ParseException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return Arrays.asList(IP + " " + d2);
}
}).distinct();
words.saveAsTextFile("hdfs://s01:9000/usr/result1");
word.saveAsTextFile("hdfs://s01:9000/usr/result2");
}
}
Change(使用SparkSQL进行PV、IP、跳出用户的查询)
public class Change {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setAppName("DataFrameCreate").setMaster("local[4]");
JavaSparkContext sc = new JavaSparkContext(conf);
SQLContext sqlContext = new SQLContext(sc);
JavaRDD<String> lines = sc.textFile("hdfs://s01:9000/usr/10");
JavaRDD<Row> jRDD = lines.map(new Function<String, Row>() {
@Override
public Row call(String line) throws Exception {
String[] lineSplited = line.split(" ");
return RowFactory.create(lineSplited[0],
lineSplited[1]
);
}
});
List<StructField> structFields = new ArrayList<StructField>();
StructField IP = DataTypes.createStructField("IP", DataTypes.StringType, true);
structFields.add(IP);
StructField time = DataTypes.createStructField("time", DataTypes.StringType, true);
structFields.add(time);
StructType structType = DataTypes.createStructType(structFields);
// 1javaRDD<row> StructType
DataFrame df = sqlContext.createDataFrame(jRDD, structType);
df.registerTempTable("users");
// PV
DataFrame pvdf = sqlContext.sql("select count(1) from users where time like'2012-01-04%'");
// IP
DataFrame ipdf = sqlContext.sql("select count(DISTINCT IP) from users where time like'2012-01-04%'");
// 跳出用户数
DataFrame tdf = sqlContext.sql(
"SELECT COUNT(1) FROM (SELECT COUNT(IP) AS times1 FROM users WHERE time like'2012-01-04%' GROUP BY IP HAVING times1=1) e");
pvdf.javaRDD().foreach(new VoidFunction<Row>() {
private static final long serialVersionUID = 1L;
@Override
public void call(Row row) throws Exception {
String sql = "insert into pv values("
+ "'" + Long.valueOf(row.getLong(0)) + "'" + ")";
Class.forName("com.mysql.jdbc.Driver");
Connection conn = null;
Statement stmt = null;
try {
conn = DriverManager.getConnection(
"jdbc:mysql://s01:3306/data", "hive", "hive");
stmt = conn.createStatement();
stmt.executeUpdate(sql);
} catch (Exception e) {
e.printStackTrace();
} finally {
if (stmt != null) {
stmt.close();
}
if (conn != null) {
conn.close();
}
}
}
});
ipdf.javaRDD().foreach(new VoidFunction<Row>() {
private static final long serialVersionUID = 1L;
@Override
public void call(Row row) throws Exception {
String sql = "insert into ip values("
+ "'" + Long.valueOf(row.getLong(0)) + "'" + ")";
Class.forName("com.mysql.jdbc.Driver");
Connection conn = null;
Statement stmt = null;
try {
conn = DriverManager.getConnection(
"jdbc:mysql://s01:3306/data", "hive", "hive");
stmt = conn.createStatement();
stmt.executeUpdate(sql);
} catch (Exception e) {
e.printStackTrace();
} finally {
if (stmt != null) {
stmt.close();
}
if (conn != null) {
conn.close();
}
}
}
});
tdf.javaRDD().foreach(new VoidFunction<Row>() {
private static final long serialVersionUID = 1L;
@Override
public void call(Row row) throws Exception {
String sql = "insert into tdf values("
+ "'" + Long.valueOf(row.getLong(0)) + "'" + ")";
Class.forName("com.mysql.jdbc.Driver");
Connection conn = null;
Statement stmt = null;
try {
conn = DriverManager.getConnection(
"jdbc:mysql://s01:3306/data", "hive", "hive");
stmt = conn.createStatement();
stmt.executeUpdate(sql);
} catch (Exception e) {
e.printStackTrace();
} finally {
if (stmt != null) {
stmt.close();
}
if (conn != null) {
conn.close();
}
}
}
});
}
}
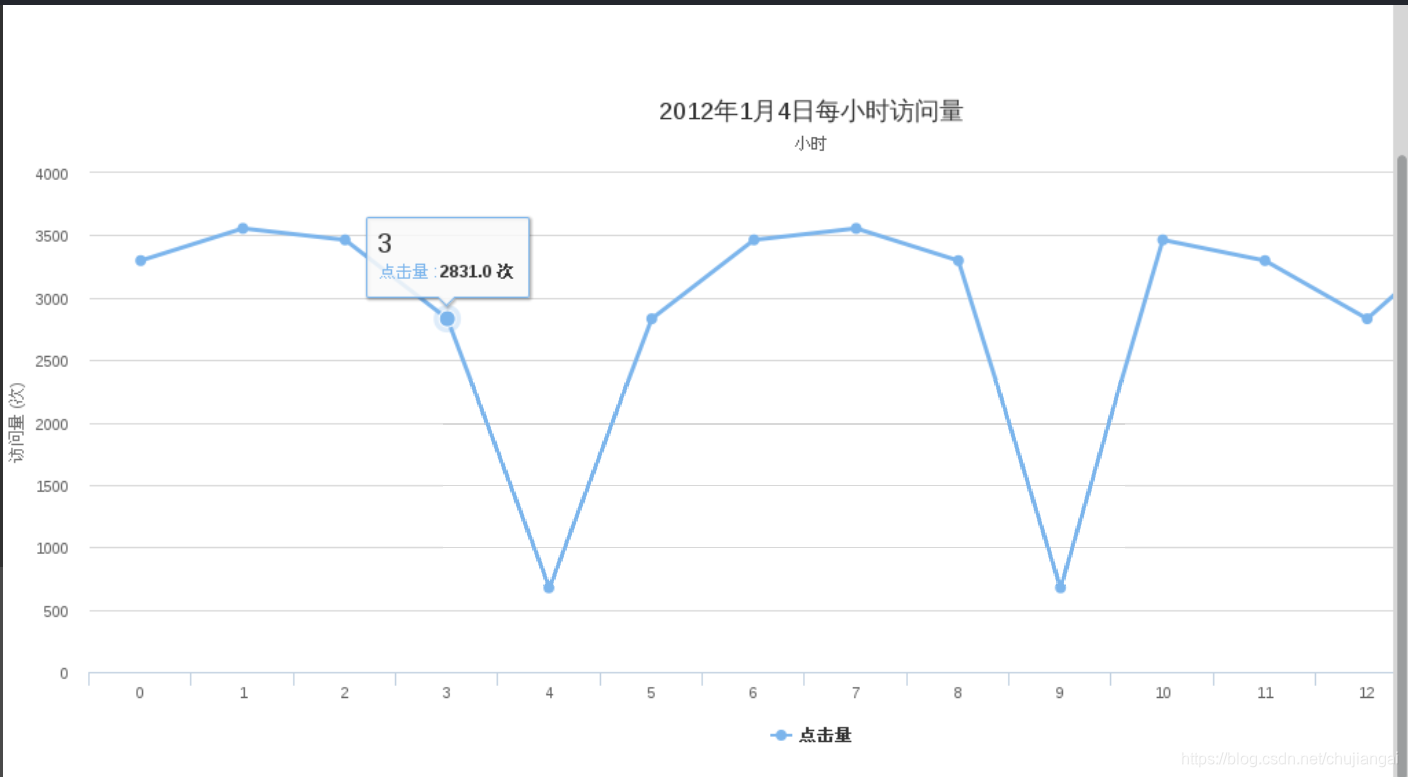
Hour类(使用SparkSQL 对24小时访问量的统计)
public class Hour {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setAppName("DataFrameCreate").setMaster("local[4]");
JavaSparkContext sc = new JavaSparkContext(conf);
SQLContext sqlContext = new SQLContext(sc);
JavaRDD<String> lines = sc.textFile("hdfs://s01:9000/usr/11");
JavaRDD<Row> jRDD = lines.map(new Function<String, Row>() {
@Override
public Row call(String line) throws Exception {
String[] lineSplited = line.split(" ");
return RowFactory.create(lineSplited[0],
lineSplited[1]
);
}
});
List<StructField> structFields = new ArrayList<StructField>();
StructField IP = DataTypes.createStructField("IP", DataTypes.StringType, true);
structFields.add(IP);
StructField time = DataTypes.createStructField("time", DataTypes.StringType, true);
structFields.add(time);
StructType structType = DataTypes.createStructType(structFields);
// 1javaRDD<row> StructType
DataFrame df = sqlContext.createDataFrame(jRDD, structType);
df.registerTempTable("users");
// 每小时的访问
DataFrame pvdf = sqlContext.sql(
"select count(1) from users where time between '2012-01-04-0' and '2012-01-04-24' group by time sort by time");
pvdf.javaRDD().foreach(new VoidFunction<Row>() {
private static final long serialVersionUID = 1L;
@Override
public void call(Row row) throws Exception {
String sql = "insert into times values("
+ "'" + Long.valueOf(row.getLong(0)) + "'" + ")";
Class.forName("com.mysql.jdbc.Driver");
Connection conn = null;
Statement stmt = null;
try {
conn = DriverManager.getConnection(
"jdbc:mysql://s01:3306/data", "hive", "hive");
stmt = conn.createStatement();
stmt.executeUpdate(sql);
} catch (Exception e) {
e.printStackTrace();
} finally {
if (stmt != null) {
stmt.close();
}
if (conn != null) {
conn.close();
}
}
}
});
}
}
五.总结
1.数据提取、清洗、处理(ETL)是大数据处理中一个非常重要的阶段
数据清洗部分必须要有,清洗的方法有很多,可以先使用空格切分每条记录,然后按照记录长度低于一定值的视为不正确的记录。
数据清理使用空格切分后,每一个属性字段和切分后形成的元素并非对应。细心分析元数据文件后发现,每个字段内部也会存在空格。
2.结果分析:该网站2012年1月4日PV 数34万、独立 IP 数8549,用户通常在工作日的上午0:00-2:00,6:00-8:00及10:00访问量最大。日间主要是通过 PC 端浏览器访问,休息日及夜间通过移动设备访问较多。
通过简单的描述可以粗略的看出,这个网站的经营状况,可以看到用户从哪里来、有哪些潜在的用户可以挖掘、网站是否存在倒闭风险等。
附录1
参考文献
[1] 林子雨,《spark编程实战》
运行结果

记大三上,spark课设
