/*垃圾话写在前面*/
听说期末考试成绩出来了,然而我的内心一片平静,(因为我知道我的人生圆满。。。。。。。。结束le);
2020.1.17
A.统计数字
题目描述
某次科研调查时得到了nnn个自然数,每个数均不超过1500000000(1.5×109)1500000000(1.5 \times 10^9)1500000000(1.5×109)。已知不相同的数不超过100001000010000个,现在需要统计这些自然数各自出现的次数,并按照自然数从小到大的顺序输出统计结果。
输入格式
共n+1n+1n+1行。
第一行是整数nnn,表示自然数的个数;
第222至n+1n+1n+1每行一个自然数。
输出格式
共mmm行(mmm为nnn个自然数中不相同数的个数),按照自然数从小到大的顺序输出。
每行输出222个整数,分别是自然数和该数出现的次数,其间用一个空格隔开。
输入输出样例
8 2 4 2 4 5 100 2 100
2 3 4 2 5 1 100 2
说明/提示
40%40\%40%的数据满足:1≤n≤10001 \le n \le 10001≤n≤1000
80%80\%80%的数据满足:1≤n≤500001 \le n \le 500001≤n≤50000
100%100\%100%的数据满足:1≤n≤2000001 \le n \le 2000001≤n≤200000,每个数均不超过1500000000(1.5×109)1500 000 000(1.5 \times 109)1500000000(1.5×109)
NOIP 2007 提高第一题
思路
一道比较水的题,sort排序,时间复杂度为 O(n*logn) .
CODE
1 #include <bits/stdc++.h> 2 using namespace std; 3 typedef long long ll; 4 5 inline ll read(){ 6 ll ans=0,f=1; 7 char ch=getchar(); 8 while(!isdigit(ch)) f*=(ch=='-')? -1:1,ch=getchar(); 9 do ans=(ans<<1)+(ans<<3)+(ch^48),ch=getchar(); 10 while(isdigit(ch)); 11 return ans*f; 12 } 13 14 inline bool cmp(int a,int b){ 15 return a<b; 16 } 17 18 const ll N=200001; 19 ll n; 20 ll x[N]; 21 22 int main(){ 23 // freopen("count.in","r",stdin); 24 // freopen("count.out","w",stdout); 25 n=read(); 26 memset(x,127,sizeof(x)); 27 for(int i=1;i<=n;i++){ 28 x[i]=read(); 29 } 30 sort(x+1,x+1+n,cmp); 31 int ans=1; 32 for(int i=2;i<=n;i++){ 33 if(x[i]==x[i-1]) ans++; 34 else { 35 printf("%d %d\n",x[i-1],ans); 36 ans=1; 37 } 38 } 39 cout<<x[n]<<" "<<ans; 40 return 0; 41 }
B.字符串的展开
题目描述
在初赛普及组的“阅读程序写结果”的问题中,我们曾给出一个字符串展开的例子:如果在输入的字符串中,含有类似于“d-h”或者“4-8”的字串,我们就把它当作一种简写,输出时,用连续递增的字母或数字串替代其中的减号,即,将上面两个子串分别输出为“defgh”和“45678"。在本题中,我们通过增加一些参数的设置,使字符串的展开更为灵活。具体约定如下:
(1) 遇到下面的情况需要做字符串的展开:在输入的字符串中,出现了减号“-”,减号两侧同为小写字母或同为数字,且按照ASCII码的顺序,减号右边的字符严格大于左边的字符。
(2) 参数p1p_1p1:展开方式。p1=1p_1=1p1=1时,对于字母子串,填充小写字母;p1=2p_1=2p1=2时,对于字母子串,填充大写字母。这两种情况下数字子串的填充方式相同。p1=3p_1=3p1=3时,不论是字母子串还是数字字串,都用与要填充的字母个数相同的星号“*”来填充。
(3) 参数p2p_2p2:填充字符的重复个数。p2=kp_2=kp2=k表示同一个字符要连续填充k个。例如,当p2=3p_2=3p2=3时,子串“d-h”应扩展为“deeefffgggh”。减号两边的字符不变。
(4) 参数p3p_3p3:是否改为逆序:p3=1p3=1p3=1表示维持原来顺序,p3=2p_3=2p3=2表示采用逆序输出,注意这时候仍然不包括减号两端的字符。例如当p1=1p_1=1p1=1、p2=2p_2=2p2=2、p3=2p_3=2p3=2时,子串“d-h”应扩展为“dggffeeh”。
(5) 如果减号右边的字符恰好是左边字符的后继,只删除中间的减号,例如:“d-e”应输出为“de”,“3-4”应输出为“34”。如果减号右边的字符按照ASCII码的顺序小于或等于左边字符,输出时,要保留中间的减号,例如:“d-d”应输出为“d-d”,“3-1”应输出为“3-1”。
输入格式
共两行。
第111行为用空格隔开的333个正整数,依次表示参数p1,p2,p3p_1,p_2,p_3p1,p2,p3。
第222行为一行字符串,仅由数字、小写字母和减号“−-−”组成。行首和行末均无空格。
输出格式
共一行,为展开后的字符串。
输入输出样例
1 2 1 abcs-w1234-9s-4zz
abcsttuuvvw1234556677889s-4zz
2 3 2 a-d-d
aCCCBBBd-d
说明/提示
40%40\%40%的数据满足:字符串长度不超过555
100%100\%100%的数据满足:1≤p1≤3,1≤p2≤8,1≤p3≤21 \le p_1 \le 3,1 \le p_2 \le 8,1 \le p_3 \le 21≤p1≤3,1≤p2≤8,1≤p3≤2。字符串长度不超过100100100
NOIP 2007 提高第二题
思路
这道题看到一个“ - ” ,就要判断 一次,全用if语句加不停地for循环,代码就会显得很冗杂,所以一次性判断;
p.s.: 1.第一空与最后为“ - ”的,要直接输出,
2“ - ” 前后不同时为字母或数字的“ - ”不展开,直接输出;
3.单独打一个pd(判断)函数出来pd
code
1 #include <bits/stdc++.h> 2 using namespace std; 3 4 int p1,p2,p3; 5 6 inline int read(){ 7 int ans=0,f=1; 8 char ch=getchar(); 9 while(!isdigit(ch)) f*=(ch=='-')? -1:1,ch=getchar(); 10 do ans=(ans<<1)+(ans<<3)+(ch^48),ch=getchar(); 11 while(isdigit(ch)); 12 return ans*f; 13 } 14 15 inline bool pd(char a,char b){ 16 if(a>=b) return false; 17 if(isdigit(a) && isdigit(b)) return true; 18 if((a>='a' && a<='z') && (b>='a' && b<='z')) return true; 19 return false; 20 } 21 22 int main(){ 23 p1=read(),p2=read(),p3=read(); 24 string s; 25 cin >> s; 26 int l = s.length(); 27 for(int i=0;i<l;i++){ 28 if(i!=0 && i!=l-1 && s[i]=='-' && pd(s[i-1],s[i+1])){ 29 int cnt=-1*(!isdigit(s[i-1]) && p1==2)*32; 30 char b=s[i-1],e=s[i+1]; 31 if(p3==2) swap(b,e); 32 int d=(b<e) ?1:-1; 33 for(char k=b;k!=e;k+=d){ 34 if(k==b) continue; 35 for(int j=1;j<=p2;j++){ 36 if(p1==3) putchar('*'); 37 else putchar(k+cnt); 38 } 39 } 40 } 41 else putchar(s[i]); 42 } 43 return 0; 44 }
C.矩阵取数游戏
题目描述
帅帅经常跟同学玩一个矩阵取数游戏:对于一个给定的n×mn \times mn×m的矩阵,矩阵中的每个元素ai,ja_{i,j}ai,j均为非负整数。游戏规则如下:
- 每次取数时须从每行各取走一个元素,共nnn个。经过mmm次后取完矩阵内所有元素;
- 每次取走的各个元素只能是该元素所在行的行首或行尾;
- 每次取数都有一个得分值,为每行取数的得分之和,每行取数的得分 = 被取走的元素值×2i\times 2^i×2i,其中iii表示第iii次取数(从111开始编号);
- 游戏结束总得分为mmm次取数得分之和。
帅帅想请你帮忙写一个程序,对于任意矩阵,可以求出取数后的最大得分。
输入格式
输入文件包括n+1n+1n+1行:
第111行为两个用空格隔开的整数nnn和mmm。
第2∽n+12\backsim n+12∽n+1行为n×mn \times mn×m矩阵,其中每行有mmm个用单个空格隔开的非负整数。
输出格式
输出文件仅包含111行,为一个整数,即输入矩阵取数后的最大得分。
输入输出样例
2 3 1 2 3 3 4 2
82
说明/提示
NOIP 2007 提高第三题
数据范围:
60%的数据满足:1≤n,m≤301\le n, m \le 301≤n,m≤30,答案不超过101610^{16}1016
100%的数据满足:1≤n,m≤801\le n, m \le 801≤n,m≤80,0≤ai,j≤10000 \le a_{i,j} \le 10000≤ai,j≤1000
思路
/*标准错误答案*/
拿到这道题的我第一反应就是贪心(学) ,(<-_-> 滑稽),然而众所周知(肾悲战争是秘密进行的),这道题是用dp解决;
然后我就悲伤的去打了一波贪心,》》》》》》》
先写一个函数,将每行中选择的顺序用数组保存下来,最后在计算,(我还开了一波unsigned long long)
wrong code
inline void tanx(int x,int t){ int begin,end; for(int i=1;i<=m;i++){ if(!v[i]){ begin=i; break; } } if(t==m) { ji[x][m]=g[x][begin]; return ; } for(int i=m;i>0;i--){ if(!v[i]){ end=i; break; } } int minn=(g[x][begin]>g[x][end]) ?end:begin; ji[x][t]=g[x][minn]; v[minn]=1; tanx(x,t+1); }
然后再在main函数里面计算值。
我居然还有20分!!!!??(太棒了)
/*正解*/
这其实是一个dp; 我们设dp[i][j]为区间为 [i,j] 时,值的最大值;
于是可以得到 f[i][j] = max(f[i][j], f[i - 1][j] + base[m - j + i - 1] * ar[i - 1]);
f[i][j] = max(f[i][j], f[i][j + 1] + base[m - j + i - 1] * ar[j + 1]);
然后就是这道题最最最最最最最最最最最最最最最恶心的地方————————高精度计算
先用一波结构体定义长度与数组,每一位用四位压缩。
CODE
#include <bits/stdc++.h> using namespace std; const int N=85,mod=10000; int n,m; int ar[N]; struct node{ int p[505], len; node() { memset(p, 0, sizeof p); len = 0; } //这是构造函数,用于直接创建一个高精度变量 void print() { printf("%d", p[len]); for (int i = len - 1; i > 0; i--) { if (p[i] == 0) { printf("0000"); continue; } for (int k = 10; k * p[i] < mod; k *= 10) printf("0"); printf("%d", p[i]); } } }f[N][N],base[N],ans; node operator + (const node &a,const node &b){ node c; c.len = max(a.len, b.len); int x = 0; for (int i = 1; i <= c.len; i++) { c.p[i] = a.p[i] + b.p[i] + x; x = c.p[i] / mod; c.p[i] %= mod; } if (x > 0) c.p[++c.len] = x; return c; } node operator * (const node &a,const int &b){ node c; c.len = a.len; int x = 0; for (int i = 1; i <= c.len; i++) { c.p[i] = a.p[i] * b + x; x = c.p[i] / mod; c.p[i] %= mod; } while (x > 0) c.p[++c.len] = x % mod, x /= mod; return c; } node max(const node &a,const node &b){ if (a.len > b.len) return a; else if (a.len < b.len) return b; for (int i = a.len; i > 0; i--) if (a.p[i] > b.p[i]) return a; else if (a.p[i] < b.p[i]) return b; return a; } inline void basetwo(){ base[0].p[1]=1,base[0].len=1; for(int i=1;i<=m+2;i++){ base[i]=base[i-1]*2; } } inline int read(){ int p=0,f=1; char ch=getchar(); while(!isdigit(ch)) f*=(ch=='-')? -1:1,ch=getchar(); do p=(p<<1)+(p<<3)+(ch^48),ch=getchar(); while(isdigit(ch)); return p*f; } int main(){ n=read(),m=read(); basetwo(); while(n--){ memset(f,0,sizeof f); for(int i=1;i<=m;i++) ar[i]=read(); for(int i=1;i<=m;i++){ for(int j=m;j>=i;j--){ f[i][j] = max(f[i][j], f[i - 1][j] + base[m - j + i - 1] * ar[i - 1]); f[i][j] = max(f[i][j], f[i][j + 1] + base[m - j + i - 1] * ar[j + 1]); } } node Max; for (int i = 1; i <= m; i++) Max = max(Max, f[i][i] + base[m] * ar[i]); ans = ans + Max; } ans.print(); return 0; }
高精度太难受了;。。。
D. 【NOIP2007 提高组】 树网的核
题目描述
设T=(V,E,W)T=(V,E,W)T=(V,E,W)是一个无圈且连通的无向图(也称为无根树),每条边到有正整数的权,我们称TTT为树网(treebetwork),其中VVV,EEE分别表示结点与边的集合,WWW表示各边长度的集合,并设TTT有nnn个结点。
路径:树网中任何两结点aaa,bbb都存在唯一的一条简单路径,用d(a,b)d(a, b)d(a,b)表示以a,ba, ba,b为端点的路径的长度,它是该路径上各边长度之和。我们称d(a,b)d(a, b)d(a,b)为a,ba, ba,b两结点间的距离。
D(v,P)=min{d(v,u)}D(v, P)=\min\{d(v, u)\}D(v,P)=min{d(v,u)}, uuu为路径PPP上的结点。
树网的直径:树网中最长的路径成为树网的直径。对于给定的树网TTT,直径不一定是唯一的,但可以证明:各直径的中点(不一定恰好是某个结点,可能在某条边的内部)是唯一的,我们称该点为树网的中心。
偏心距ECC(F)\mathrm{ECC}(F)ECC(F):树网T中距路径F最远的结点到路径FFF的距离,即
ECC(F)=max{d(v,F),v∈V}\mathrm{ECC}(F)=\max\{d(v, F),v \in V\}ECC(F)=max{d(v,F),v∈V}
任务:对于给定的树网T=(V,E,W)T=(V, E, W)T=(V,E,W)和非负整数sss,求一个路径FFF,他是某直径上的一段路径(该路径两端均为树网中的结点),其长度不超过sss(可以等于s),使偏心距ECC(F)ECC(F)ECC(F)最小。我们称这个路径为树网T=(V,E,W)T=(V, E, W)T=(V,E,W)的核(Core)。必要时,FFF可以退化为某个结点。一般来说,在上述定义下,核不一定只有一个,但最小偏心距是唯一的。
下面的图给出了树网的一个实例。图中,A−BA-BA−B与A−CA-CA−C是两条直径,长度均为202020。点WWW是树网的中心,EFEFEF边的长度为555。如果指定s=11s=11s=11,则树网的核为路径DEFG(也可以取为路径DEF),偏心距为888。如果指定s=0s=0s=0(或s=1s=1s=1、s=2s=2s=2),则树网的核为结点FFF,偏心距为121212。
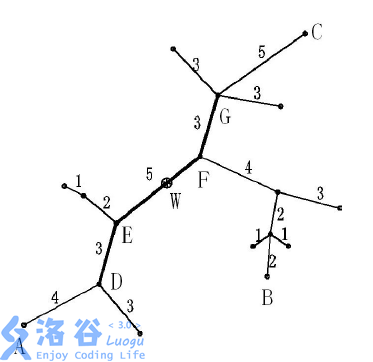 (图片来自洛谷)
(图片来自洛谷)
输入格式
共nnn行。
第111行,两个正整数nnn和sss,中间用一个空格隔开。其中nnn为树网结点的个数,sss为树网的核的长度的上界。设结点编号以此为1,2,…,n1,2,…,n1,2,…,n。
从第222行到第nnn行,每行给出333个用空格隔开的正整数,依次表示每一条边的两个端点编号和长度。例如,“2472 4 7247”表示连接结点222与444的边的长度为777。
输出格式
一个非负整数,为指定意义下的最小偏心距。
输入输出样例
5 2 1 2 5 2 3 2 2 4 4 2 5 3
5
8 6 1 3 2 2 3 2 3 4 6 4 5 3 4 6 4 4 7 2 7 8 3
5
说明/提示
40%40\%40%的数据满足:5≤n≤155 \le n \le 155≤n≤15
70%70\%70%的数据满足:5≤n≤805 \le n \le 805≤n≤80
100%100\%100%的数据满足:5≤n≤300,0≤s≤10005 \le n \le 300,0 \le s \le 10005≤n≤300,0≤s≤1000。边长度为不超过100010001000的正整数
NOIP 2007 提高第四题
思路
先用两遍dfs求出图的直径;
我们找的最小值肯定要么是两端点到直径端点的贡献,要么是直径上的点的贡献,
code
#include<bits/stdc++.h>
#define N 500005
using namespace std;
int n,m,x,y,z,k,id,top,ans=2e9;
int dis[N],fa[N];
bool mark[N];
int head[N],ver[N],edge[N],next[N],tot;
inline void add(int x,int y,int z){
ver[++tot]=y;edge[tot]=z;
next[tot]=head[x],head[x]=tot;
}
void dfs(int f,int x){
fa[x]=f;
if(dis[x]>dis[k])k=x;
for(int i=head[x];i;i=next[i]){
int y=ver[i];
if(y==f||mark[y])continue;
dis[y]=dis[x]+edge[i];
dfs(x,y);
}
}
inline int read(){
int ans=0,f=1;
char ch=getchar();
while(!isdigit(ch)) f*=(ch=='-')? -1:1,ch=getchar();
do ans=(ans<<1)+(ans<<3)+(ch^48),ch=getchar();
while(isdigit(ch));
return ans*f;
}
int main(){
n=read(),m=read();
for(int i=1;i<n;i++){
x=read(),y=read(),z=read();
add(x,y,z),add(y,x,z);
}
dis[1]=1,dfs(0,1);
dis[k]=0,dfs(0,k);
//k表示最远的端点
top=k;
for(int i=top,j=top,l=1,r=0;i;i=fa[i]){
while(dis[j]-dis[i]>m)j=fa[j];
//进行尺取,选路径。
x=max(dis[top]-dis[j],dis[i]);//路径两端点到直径端点的最小贡献.
ans=min(ans,x);
}
for(int i=top;i;i=fa[i])mark[i]=1;//标记直径,重新计算每个点的贡献。
for(int i=top;i;i=fa[i]){
k=i,dis[k]=0;
dfs(fa[i],i);
}
for(int i=1;i<=n;i++)
ans=max(ans,dis[i]);
printf("%d\n",ans);
return 0;
}