1. 背景介绍
由于之前在研究基于pyspark+GPU的实时及离线研究时,GPU的性能(运行时间)并没有得到提升或提升不明显。基于这个原因,该研究只针对基于python写cuda程序的数值计算加速算法(不考虑使用spark的场景),进一步研究对GPU的性能研究及使用场景分析。(之前项目上对GPU研究方面过多,暂时只能推出一点内容)
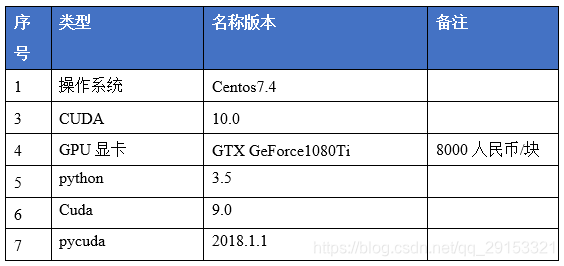
2. 测试环境
2.1. 硬件

2.2. 软件
3. 测试过程
3.1 测试数据及测试逻辑
(1)测试数据为python程序中自动生成的numpy类型的数组a和b。
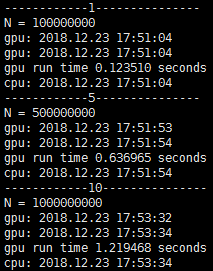
每个数组长度为1亿。
每个数组长度为10亿。
每个数组长度为100亿。
(2)测试逻辑为数组间的数值运算。
3.2 测试代码
import pycuda.autoinit
import pycuda.driver as drv
import numpy as np
from timeit import default_timer as timer
from pycuda.compiler import SourceModule
mod = SourceModule("""
__global__ void func(float *a, float *b, size_t N)
{
const int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i >= N)
{
return;
}
float temp_a = a[i];
float temp_b = b[i];
a[i] = (temp_a * 10 + 2 ) * ((temp_b + 2) * 10 - 5 ) * 5;
// a[i] = a[i] + b[i];
}
""")
func = mod.get_function("func")
def test(N):
# N = 1024 * 1024 * 90 # float: 4M = 1024 * 1024
print("N = %d" % N)
N = np.int32(N)
a = np.random.randn(N).astype(np.float32)
b = np.random.randn(N).astype(np.float32)
# copy a to aa
aa = np.empty_like(a)
aa[:] = a
# GPU run
nTheads = 256
nBlocks = int( ( N + nTheads - 1 ) / nTheads )
start = timer()
func(
drv.InOut(a), drv.In(b), N,
block=( nTheads, 1, 1 ), grid=( nBlocks, 1 ) )
run_time = timer() - start
print("gpu run time %f seconds " % run_time)
# cpu run
start = timer()
aa = (aa * 10 + 2 ) * ((b + 2) * 10 - 5 ) * 5
run_time = timer() - start
print("cpu run time %f seconds " % run_time)
# check result
r = a - aa
#print( min(r), max(aa) )
def main():
for n in range(1, 10):
N = 1024 * 1024 * (n * 10)
print("------------%d---------------" % n)
test(N)
if __name__ == '__main__':
main()
4. 算法测试
4.1. CPU 构建
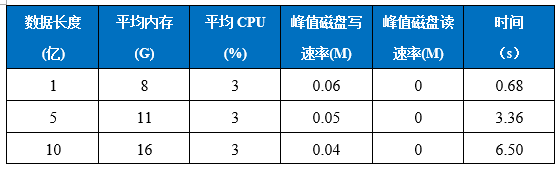
4.1.1. 资源列表
4.1.2. 截图列表
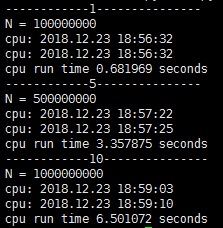
传统硬件概览

4.2. GPU 构建
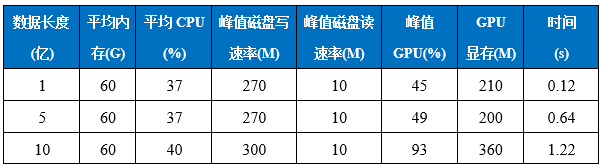
4.2.1. 资源列表
4.2.2. 截图列表
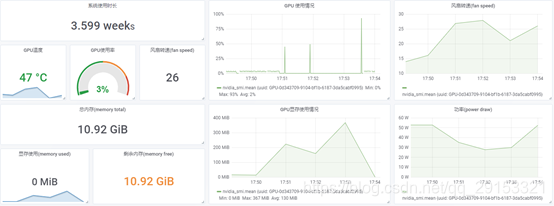
传统资源概览

GPU硬件概览
4.3. 构建测试总结
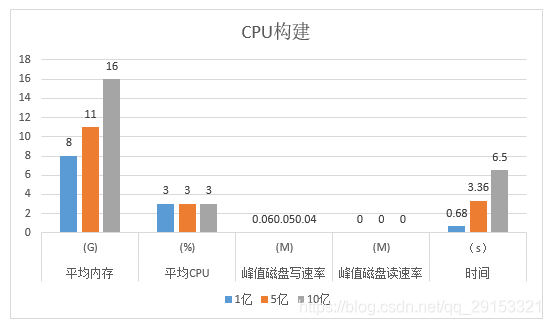
CPU情况下:
平均内存:1亿 < 5亿 < 10亿
平均CPU:1亿 = 5亿 = 10亿
峰值磁盘写速率:1亿 ≈ 5亿 ≈ 10亿
峰值磁盘读速率:1亿 = 5亿 = 10亿
时间:1亿 < 5亿 < 10亿
GPU情况下:
平均内存:1亿 = 5亿 = 10亿
平均CPU:1亿 ≈ 5亿 ≈ 10亿
峰值磁盘写速率:1亿 ≈ 5亿≈ 10亿
峰值磁盘读速率:1亿 = 5亿 = 10亿
峰值GPU:1亿 < 5亿 < 10亿
GPU显存:10亿 < 1亿 < 5亿
时间: 1亿 < 5亿 < 10亿
结论
- 无论是CPU或者GPU同等运行条件下,随着数据量(数据长度)的增加,对于CPU的资源消费基本上保持不变,但是对GPU的利用率一直在提高。
- GPU运行时间比CPU运行时间快4-5倍。
