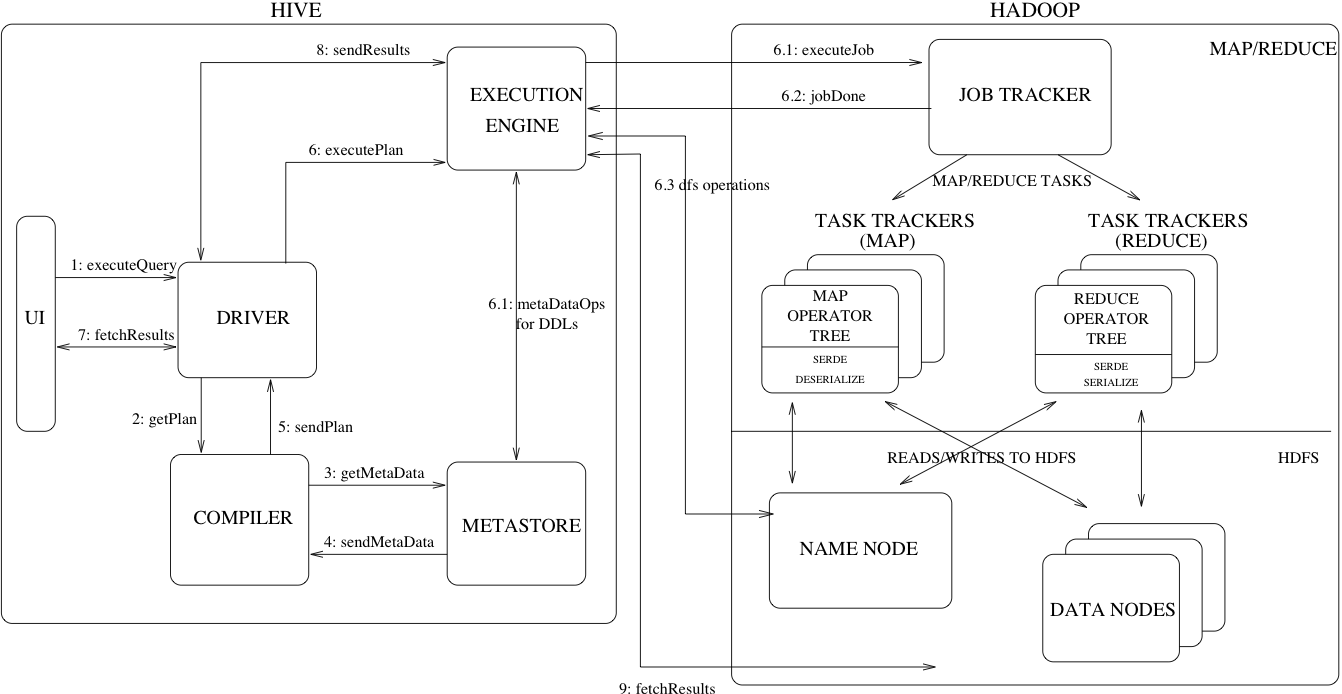
Figure 1 also shows how a typical query flows through the system.
图一显示一个普通的查询是如何流经Hive系统的。The UI calls the execute interface to the Driver (step 1 in Figure 1).
图中的第1步,UI向Driver调用执行接口The Driver creates a session handle for the query and sends the query to the compiler to generate an execution plan (step 2).
第2步,Driver为查询创建一个Session句柄,将查询发送到compiler编译器,生成一个执行计划(execution plan)。The compiler gets the necessary metadata from the metastore (steps 3 and 4).
第3-4步,编译器从metastore中获取必要的元数据信息。This metadata is used to typecheck the expressions in the query tree as well as to prune partitions based on query predicates. The plan generated by the compiler (step 5) is a DAG of stages with each stage being either a map/reduce job, a metadata operation or an operation on HDFS. For map/reduce stages, the plan contains map operator trees (operator trees that are executed on the mappers) and a reduce operator tree (for operations that need reducers). The execution engine submits these stages to appropriate components (steps 6, 6.1, 6.2 and 6.3). In each task (mapper/reducer) the deserializer associated with the table or intermediate outputs is used to read the rows from HDFS files and these are passed through the associated operator tree. Once the output is generated, it is written to a temporary HDFS file though the serializer (this happens in the mapper in case the operation does not need a reduce). The temporary files are used to provide data to subsequent map/reduce stages of the plan. For DML operations the final temporary file is moved to the table's location. This scheme is used to ensure that dirty data is not read (file rename being an atomic operation in HDFS). For queries, the contents of the temporary file are read by the execution engine directly from HDFS as part of the fetch call from the Driver (steps 7, 8 and 9).