一、车牌字符识别简介
这一片文章是对EasyPR的字符识别部分进行改进,EasyPR已经很好的使用图片处理和机器学习的方式帮我们将车牌检测出来,并且将车牌的字符提取出来了,但EasyPR使用的是ANN进行的字符识别,这里加以改进,使用Lenet网络训练车牌的字符识别(包括中文), 提高识别精度 。
二、Lenet介绍
LeNet-5出自论文Gradient-Based Learning Applied to Document Recognition,是一种用于手写体字符识别的非常高效的卷积神经网络。
网络输入层要求: 32*32 的单通道图片
网络结构图:(生成工具 http://ethereon.github.io/netscope/#/editor )

三、准备训练数据集
训练数据连接:https://download.csdn.net/download/huxiny/11046136
四、训练数据预处理
1. 先将训练数据解压:

每一个文件夹下都有对应的字符,字符的数量不固定,有多有少
依据习惯将数据集分为train和test数据集,train数据集占80%,test数据集占20%
在项目的根目录下创建data文件夹,并在data文件夹中创建train文件夹和val文件夹,如下:
(train和val这两个文件夹的子目录要与解压数据的子目录一致,如上图,写个脚本自己创建就好了,很简单,)
2.运行下面脚本将data数据按比例分给train(80%)和test(20%):
(路径改为自己的保存路径)
import os
import shutil
path = "解压数据路径"
allDirs = []
for root, dirs, files in os.walk(path):
for dir in dirs:
allDirs.append(dir)
testDir = '/home/pzs/husin/Caffe_carPlate/data/test/'
trainDir = '/home/pzs/husin/Caffe_carPlate/data/train/'
print(allDirs)
for dir in allDirs:
sonDir = path+dir+'/'
for root, dirs, files in os.walk(sonDir):
filesNum = len(files)
for i in range(filesNum):
if i <= int(filesNum*0.2) : # 20%复制到test
shutil.copyfile(sonDir + files[i], testDir + dir + '/' + files[i])
else : # 80%复制到train
shutil.copyfile(sonDir + files[i], trainDir + dir + '/' + files[i])
3.修改文件名
因为该数据的图片命名比较混乱,这里用用一个脚本修改这些图片的文件名,命名规则‘文件夹_i(i表示第几个图片文件).jpg’:
(路径改为自己的保存路径)
import os
testDir = '/home/pzs/husin/Caffe_carPlate/data/test/'
trainDir = '/home/pzs/husin/Caffe_carPlate/data/train/'
def rename(renameDir):
allDirs = []
for root, dirs, files in os.walk(renameDir):
for dir in dirs:
allDirs.append(dir)
for dir in allDirs:
sonDir = renameDir+dir+'/'
for root, dirs, files in os.walk(sonDir):
filesNum = len(files)
for i in range(filesNum):
os.rename(sonDir+files[i], sonDir + dir +'_' + str(i)+'.jpg')
rename(testDir)
rename(trainDir)
结果如下:

4.在data目录下创建labels.txt, 内容如下:
0 n_0
1 n_1
2 n_2
3 n_3
4 n_4
5 n_5
6 n_6
7 n_7
8 n_8
9 n_9
10 c_A
11 c_B
12 c_C
13 c_D
14 c_E
15 c_F
16 c_G
17 c_H
18 c_I
19 c_J
20 c_K
21 c_L
22 c_N
23 c_M
24 c_O
25 c_P
26 c_Q
27 c_R
28 c_S
29 c_T
30 c_U
31 c_V
32 c_W
33 c_X
34 c_Y
35 c_Z
36 zh_ning
37 zh_e
38 zh_yun
39 zh_meng
40 zh_min
41 zh_jing
42 zh_jin
43 zh_su
44 zh_zang
45 zh_zhe
46 zh_yu
47 zh_xin
48 zh_gui
49 zh_yue
50 zh_lu
51 zh_ji
52 zh_qing
53 zh_gui1
54 zh_gan
55 zh_wan
56 zh_yu1
57 zh_sx
58 zh_xiang
59 zh_shan
60 zh_hei
61 zh_hu
62 zh_qiong
63 zh_liao
64 zh_gan1
65 zh_jl
66 zh_cuan
5. 接着继续在该目录下创建train.txt和val.txt文件。
6. 打开命令行输入下面命令:
ls train/0 | sed "s:^:0/:" | sed "s:$: 0:" >> train.txt
ls train/1 | sed "s:^:1/:" | sed "s:$: 1:" >> train.txt
ls train/2 | sed "s:^:2/:" | sed "s:$: 2:" >> train.txt
ls train/3 | sed "s:^:3/:" | sed "s:$: 3:" >> train.txt
ls train/4 | sed "s:^:4/:" | sed "s:$: 4:" >> train.txt
ls train/5 | sed "s:^:5/:" | sed "s:$: 5:" >> train.txt
ls train/6 | sed "s:^:6/:" | sed "s:$: 6:" >> train.txt
ls train/7 | sed "s:^:7/:" | sed "s:$: 7:" >> train.txt
ls train/8 | sed "s:^:8/:" | sed "s:$: 8:" >> train.txt
ls train/9 | sed "s:^:9/:" | sed "s:$: 9:" >> train.txt
ls train/A | sed "s:^:A/:" | sed "s:$: 10:" >> train.txt
ls train/B | sed "s:^:B/:" | sed "s:$: 11:" >> train.txt
ls train/C | sed "s:^:C/:" | sed "s:$: 12:" >> train.txt
ls train/D | sed "s:^:D/:" | sed "s:$: 13:" >> train.txt
ls train/E | sed "s:^:E/:" | sed "s:$: 14:" >> train.txt
ls train/F | sed "s:^:F/:" | sed "s:$: 15:" >> train.txt
ls train/G | sed "s:^:G/:" | sed "s:$: 16:" >> train.txt
ls train/H | sed "s:^:H/:" | sed "s:$: 17:" >> train.txt
ls train/I | sed "s:^:I/:" | sed "s:$: 18:" >> train.txt
ls train/J | sed "s:^:J/:" | sed "s:$: 19:" >> train.txt
ls train/K | sed "s:^:K/:" | sed "s:$: 20:" >> train.txt
ls train/L | sed "s:^:L/:" | sed "s:$: 21:" >> train.txt
ls train/N | sed "s:^:N/:" | sed "s:$: 22:" >> train.txt
ls train/M | sed "s:^:M/:" | sed "s:$: 23:" >> train.txt
ls train/O | sed "s:^:O/:" | sed "s:$: 24:" >> train.txt
ls train/P | sed "s:^:P/:" | sed "s:$: 25:" >> train.txt
ls train/Q | sed "s:^:Q/:" | sed "s:$: 26:" >> train.txt
ls train/R | sed "s:^:R/:" | sed "s:$: 27:" >> train.txt
ls train/S | sed "s:^:S/:" | sed "s:$: 28:" >> train.txt
ls train/T | sed "s:^:T/:" | sed "s:$: 29:" >> train.txt
ls train/U | sed "s:^:U/:" | sed "s:$: 30:" >> train.txt
ls train/V | sed "s:^:V/:" | sed "s:$: 31:" >> train.txt
ls train/W | sed "s:^:W/:" | sed "s:$: 32:" >> train.txt
ls train/X | sed "s:^:X/:" | sed "s:$: 33:" >> train.txt
ls train/Y | sed "s:^:Y/:" | sed "s:$: 34:" >> train.txt
ls train/Z | sed "s:^:Z/:" | sed "s:$: 35:" >> train.txt
ls train/zh_ning | sed "s:^:zh_ning/:" | sed "s:$: 36:" >> train.txt
ls train/zh_e | sed "s:^:zh_e/:" | sed "s:$: 37:" >> train.txt
ls train/zh_yun | sed "s:^:zh_yun/:" | sed "s:$: 38:" >> train.txt
ls train/zh_meng | sed "s:^:zh_meng/:" | sed "s:$: 39:" >> train.txt
ls train/zh_min | sed "s:^:zh_min/:" | sed "s:$: 40:" >> train.txt
ls train/zh_jing | sed "s:^:zh_jing/:" | sed "s:$: 41:" >> train.txt
ls train/zh_jin | sed "s:^:zh_jin/:" | sed "s:$: 42:" >> train.txt
ls train/zh_su | sed "s:^:zh_su/:" | sed "s:$: 43:" >> train.txt
ls train/zh_zang | sed "s:^:zh_zang/:" | sed "s:$: 44:" >> train.txt
ls train/zh_zhe | sed "s:^:zh_zhe/:" | sed "s:$: 45:" >> train.txt
ls train/zh_yu | sed "s:^:zh_yu/:" | sed "s:$: 46:" >> train.txt
ls train/zh_xin | sed "s:^:zh_xin/:" | sed "s:$: 47:" >> train.txt
ls train/zh_gui | sed "s:^:zh_gui/:" | sed "s:$: 48:" >> train.txt
ls train/zh_yue | sed "s:^:zh_yue/:" | sed "s:$: 49:" >> train.txt
ls train/zh_lu | sed "s:^:zh_lu/:" | sed "s:$: 50:" >> train.txt
ls train/zh_ji | sed "s:^:zh_ji/:" | sed "s:$: 51:" >> train.txt
ls train/zh_qing | sed "s:^:zh_qing/:" | sed "s:$: 52:" >> train.txt
ls train/zh_gui1 | sed "s:^:zh_gui1/:" | sed "s:$: 53:" >> train.txt
ls train/zh_gan | sed "s:^:zh_gan/:" | sed "s:$: 54:" >> train.txt
ls train/zh_wan | sed "s:^:zh_wan/:" | sed "s:$: 55:" >> train.txt
ls train/zh_yu1 | sed "s:^:zh_yu1/:" | sed "s:$: 56:" >> train.txt
ls train/zh_sx | sed "s:^:zh_sx/:" | sed "s:$: 57:" >> train.txt
ls train/zh_xiang | sed "s:^:zh_xiang/:" | sed "s:$: 58:" >> train.txt
ls train/zh_shan | sed "s:^:zh_shan/:" | sed "s:$: 59:" >> train.txt
ls train/zh_hei | sed "s:^:zh_hei/:" | sed "s:$: 60:" >> train.txt
ls train/zh_hu | sed "s:^:zh_hu/:" | sed "s:$: 61:" >> train.txt
ls train/zh_qiong | sed "s:^:zh_qiong/:" | sed "s:$: 62:" >> train.txt
ls train/zh_liao | sed "s:^:zh_liao/:" | sed "s:$: 63:" >> train.txt
ls train/zh_gan1 | sed "s:^:zh_gan1/:" | sed "s:$: 64:" >> train.txt
ls train/zh_jl | sed "s:^:zh_jl/:" | sed "s:$: 65:" >> train.txt
ls train/zh_cuan | sed "s:^:zh_cuan/:" | sed "s:$: 66:" >> train.txt
打开train.txt文件可以看到:

val.txt同理:
ls val/0 | sed "s:^:0/:" | sed "s:$: 0:" >> val.txt
ls val/1 | sed "s:^:1/:" | sed "s:$: 1:" >> val.txt
ls val/2 | sed "s:^:2/:" | sed "s:$: 2:" >> val.txt
ls val/3 | sed "s:^:3/:" | sed "s:$: 3:" >> val.txt
ls val/4 | sed "s:^:4/:" | sed "s:$: 4:" >> val.txt
ls val/5 | sed "s:^:5/:" | sed "s:$: 5:" >> val.txt
ls val/6 | sed "s:^:6/:" | sed "s:$: 6:" >> val.txt
ls val/7 | sed "s:^:7/:" | sed "s:$: 7:" >> val.txt
ls val/8 | sed "s:^:8/:" | sed "s:$: 8:" >> val.txt
ls val/9 | sed "s:^:9/:" | sed "s:$: 9:" >> val.txt
ls val/A | sed "s:^:A/:" | sed "s:$: 10:" >> val.txt
ls val/B | sed "s:^:B/:" | sed "s:$: 11:" >> val.txt
ls val/C | sed "s:^:C/:" | sed "s:$: 12:" >> val.txt
ls val/D | sed "s:^:D/:" | sed "s:$: 13:" >> val.txt
ls val/E | sed "s:^:E/:" | sed "s:$: 14:" >> val.txt
ls val/F | sed "s:^:F/:" | sed "s:$: 15:" >> val.txt
ls val/G | sed "s:^:G/:" | sed "s:$: 16:" >> val.txt
ls val/H | sed "s:^:H/:" | sed "s:$: 17:" >> val.txt
ls val/I | sed "s:^:I/:" | sed "s:$: 18:" >> val.txt
ls val/J | sed "s:^:J/:" | sed "s:$: 19:" >> val.txt
ls val/K | sed "s:^:K/:" | sed "s:$: 20:" >> val.txt
ls val/L | sed "s:^:L/:" | sed "s:$: 21:" >> val.txt
ls val/N | sed "s:^:N/:" | sed "s:$: 22:" >> val.txt
ls val/M | sed "s:^:M/:" | sed "s:$: 23:" >> val.txt
ls val/O | sed "s:^:O/:" | sed "s:$: 24:" >> val.txt
ls val/P | sed "s:^:P/:" | sed "s:$: 25:" >> val.txt
ls val/Q | sed "s:^:Q/:" | sed "s:$: 26:" >> val.txt
ls val/R | sed "s:^:R/:" | sed "s:$: 27:" >> val.txt
ls val/S | sed "s:^:S/:" | sed "s:$: 28:" >> val.txt
ls val/T | sed "s:^:T/:" | sed "s:$: 29:" >> val.txt
ls val/U | sed "s:^:U/:" | sed "s:$: 30:" >> val.txt
ls val/V | sed "s:^:V/:" | sed "s:$: 31:" >> val.txt
ls val/W | sed "s:^:W/:" | sed "s:$: 32:" >> val.txt
ls val/X | sed "s:^:X/:" | sed "s:$: 33:" >> val.txt
ls val/Y | sed "s:^:Y/:" | sed "s:$: 34:" >> val.txt
ls val/Z | sed "s:^:Z/:" | sed "s:$: 35:" >> val.txt
ls val/zh_ning | sed "s:^:zh_ning/:" | sed "s:$: 36:" >> val.txt
ls val/zh_e | sed "s:^:zh_e/:" | sed "s:$: 37:" >> val.txt
ls val/zh_yun | sed "s:^:zh_yun/:" | sed "s:$: 38:" >> val.txt
ls val/zh_meng | sed "s:^:zh_meng/:" | sed "s:$: 39:" >> val.txt
ls val/zh_min | sed "s:^:zh_min/:" | sed "s:$: 40:" >> val.txt
ls val/zh_jing | sed "s:^:zh_jing/:" | sed "s:$: 41:" >> val.txt
ls val/zh_jin | sed "s:^:zh_jin/:" | sed "s:$: 42:" >> val.txt
ls val/zh_su | sed "s:^:zh_su/:" | sed "s:$: 43:" >> val.txt
ls val/zh_zang | sed "s:^:zh_zang/:" | sed "s:$: 44:" >> val.txt
ls val/zh_zhe | sed "s:^:zh_zhe/:" | sed "s:$: 45:" >> val.txt
ls val/zh_yu | sed "s:^:zh_yu/:" | sed "s:$: 46:" >> val.txt
ls val/zh_xin | sed "s:^:zh_xin/:" | sed "s:$: 47:" >> val.txt
ls val/zh_gui | sed "s:^:zh_gui/:" | sed "s:$: 48:" >> val.txt
ls val/zh_yue | sed "s:^:zh_yue/:" | sed "s:$: 49:" >> val.txt
ls val/zh_lu | sed "s:^:zh_lu/:" | sed "s:$: 50:" >> val.txt
ls val/zh_ji | sed "s:^:zh_ji/:" | sed "s:$: 51:" >> val.txt
ls val/zh_qing | sed "s:^:zh_qing/:" | sed "s:$: 52:" >> val.txt
ls val/zh_gui1 | sed "s:^:zh_gui1/:" | sed "s:$: 53:" >> val.txt
ls val/zh_gan | sed "s:^:zh_gan/:" | sed "s:$: 54:" >> val.txt
ls val/zh_wan | sed "s:^:zh_wan/:" | sed "s:$: 55:" >> val.txt
ls val/zh_yu1 | sed "s:^:zh_yu1/:" | sed "s:$: 56:" >> val.txt
ls val/zh_sx | sed "s:^:zh_sx/:" | sed "s:$: 57:" >> val.txt
ls val/zh_xiang | sed "s:^:zh_xiang/:" | sed "s:$: 58:" >> val.txt
ls val/zh_shan | sed "s:^:zh_shan/:" | sed "s:$: 59:" >> val.txt
ls val/zh_hei | sed "s:^:zh_hei/:" | sed "s:$: 60:" >> val.txt
ls val/zh_hu | sed "s:^:zh_hu/:" | sed "s:$: 61:" >> val.txt
ls val/zh_qiong | sed "s:^:zh_qiong/:" | sed "s:$: 62:" >> val.txt
ls val/zh_liao | sed "s:^:zh_liao/:" | sed "s:$: 63:" >> val.txt
ls val/zh_gan1 | sed "s:^:zh_gan1/:" | sed "s:$: 64:" >> val.txt
ls val/zh_jl | sed "s:^:zh_jl/:" | sed "s:$: 65:" >> val.txt
ls val/zh_cuan | sed "s:^:zh_cuan/:" | sed "s:$: 66:" >> val.txt
最后data文件夹内容如下:

五、生成lmdb文件和均值文件
1.生成lmdb文件
lmdb是caffe使用的一种输入数据格式,在训练之前,我们必须把图片转换为caffe支持的格式才能进行训练,caffe中提供了create_imagenet.sh脚本,可以将图片转换为lmdb格式。
改脚本不仅仅能够只是将图片转换为lmdb格式,还可以对图片进行一些预处理,如resize,将图片转换为灰度图等等。
先在本项目的根目录下创建文件夹,名为lmdb。
将caffe/examples/Imagenet目录下的create_imagenet.sh脚本考本到该项目的根目录下,并将其内如修改如下:
#!/usr/bin/env sh
# Create the imagenet lmdb inputs
# N.B. set the path to the imagenet train + val data dirs
set -e
EXAMPLE=/home/pzs/husin/Caffe_carPlate/lmdb
DATA=/home/pzs/husin/Caffe_carPlate/data
TOOLS=~/caffe/caffe/build/tools
TRAIN_DATA_ROOT=/home/pzs/husin/Caffe_carPlate/data/train/
VAL_DATA_ROOT=/home/pzs/husin/Caffe_carPlate/data/val/
# Set RESIZE=true to resize the images to 256x256. Leave as false if images have
# already been resized using another tool.
RESIZE=true
if $RESIZE; then
RESIZE_HEIGHT=32
RESIZE_WIDTH=32
else
RESIZE_HEIGHT=0
RESIZE_WIDTH=0
fi
if [ ! -d "$TRAIN_DATA_ROOT" ]; then
echo "Error: TRAIN_DATA_ROOT is not a path to a directory: $TRAIN_DATA_ROOT"
echo "Set the TRAIN_DATA_ROOT variable in create_imagenet.sh to the path" \
"where the ImageNet training data is stored."
exit 1
fi
if [ ! -d "$VAL_DATA_ROOT" ]; then
echo "Error: VAL_DATA_ROOT is not a path to a directory: $VAL_DATA_ROOT"
echo "Set the VAL_DATA_ROOT variable in create_imagenet.sh to the path" \
"where the ImageNet validation data is stored."
exit 1
fi
echo "Creating train lmdb..."
GLOG_logtostderr=1 $TOOLS/convert_imageset \
--resize_height=$RESIZE_HEIGHT \
--resize_width=$RESIZE_WIDTH \
--shuffle \
--gray=true \
$TRAIN_DATA_ROOT \
$DATA/train.txt \
$EXAMPLE/fer2013_train_lmdb
echo "Creating val lmdb..."
GLOG_logtostderr=1 $TOOLS/convert_imageset \
--resize_height=$RESIZE_HEIGHT \
--resize_width=$RESIZE_WIDTH \
--shuffle \
--gray=true \
$VAL_DATA_ROOT \
$DATA/val.txt \
$EXAMPLE/fer2013_val_lmdb
echo "Done."
因为lenet网络的输入图像大小要求为3232,所以要将图片resize成3232,并且lenet的输入图像是单通道的,我们将其转换为灰度图。
运行该脚本:
sudo ./create_imagenet.sh
转换成功后会在lmdb下生成两个文件夹,分别保存了train数据的lmdb文件和val数据的lmdb文件。

2. 生成均值文件
使用下面命令生成均值文件,在lmdb文件夹下生成均值文件meantrain.binaryproto
~/caffe/caffe/build/tools/compute_image_mean fer2013_train_lmdb meantrain.binaryproto

注意一下:均值文件只需要一个就好了,即有train数据计算出来的均值文件,不需要把val数据的也计算出来。
六、构建网络
自此数据处理工作依然已经全部完成,接下来搭建lenet网络模型。
1. 在该项目的根目录下创建我文件夹prototxt
创建train_val.prototxt文件,内容如下:
name: "LeNet"
layer {
name: "family_name"
type: "Data"
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param {
mirror: true
mean_file: "/home/pzs/husin/Caffe_carPlate/lmdb/meantrain.binaryproto"
}
data_param {
source: "/home/pzs/husin/Caffe_carPlate/lmdb/fer2013_train_lmdb"
batch_size: 64
backend: LMDB
}
}
layer {
name: "family_name"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST
}
transform_param {
mirror: true
mean_file: "/home/pzs/husin/Caffe_carPlate/lmdb/meantrain.binaryproto"
}
data_param {
source: "/home/pzs/husin/Caffe_carPlate/lmdb/fer2013_train_lmdb"
batch_size: 32
backend: LMDB
}
}
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 20
kernel_size: 5
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "conv2"
type: "Convolution"
bottom: "pool1"
top: "conv2"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 50
kernel_size: 5
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "pool2"
type: "Pooling"
bottom: "conv2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "ip1"
type: "InnerProduct"
bottom: "pool2"
top: "ip1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
inner_product_param {
num_output: 1000
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "relu1"
type: "ReLU"
bottom: "ip1"
top: "ip1"
}
layer {
name: "ip2"
type: "InnerProduct"
bottom: "ip1"
top: "ip2"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
inner_product_param {
num_output: 67
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "accuracy"
type: "Accuracy"
bottom: "ip2"
bottom: "label"
top: "accuracy"
include {
phase: TEST
}
}
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "ip2"
bottom: "label"
top: "loss"
}
上述创建了lenet网络结构,lmdb数据和均值文件地址要改为自己的路径。
2. 创建lenet_solver.prototxt文件:
net: "/home/pzs/husin/Caffe_carPlate/prototxt/train_val.prototxt" # 训练网络结构文件
test_iter: 100 # 测试阶段迭代次数,测试阶段的batch_size为32,设置迭代次数为100,能够包含样本3200(测试图片共有3269张)
test_interval: 1000 # 训练迭代1000次,进行一次测试
base_lr: 0.0001 # 网络学习率
momentum: 0.9 # 动量,可以加快网络收敛速度,一般为0.9
weight_decay: 0.0005 # 网络权衰量
lr_policy: "inv" # 学习速率的衰减策略
gamma: 0.0001 # 该策略的参数
power: 0.75 # 该策略的参数
display: 1000 # 每次迭代1000次,在屏幕上打印一次日志
max_iter: 200000 # 最大迭代20万次
snapshot: 5000 # 5000次代保存一次模型
snapshot_prefix: "/home/pzs/husin/Caffe_carPlate/backups" # 模型保存路径
solver_mode: CPU
该文件保存模型训练预设的一些超参数。
七、训练网络
运行命令~/caffe/caffe/build/tools/caffe train -solver=prototxt/lenet_solver.prototxt
输出如下:

当训练迭代次数到4000次时精度已经达到99.9%了,loss非常低了,可以认为训练结果比较理想,没有太大的必要继续训练下去了。
训练的时候出现 Restarting data prefetching from start. 原因及解释如下:

八、训练结果
这里使用python脚本来调用验证训练好的模型,但先需要解决一个问题,caffe支持的meantrain.binaryproto均值文件,python接口并不支持,需要将其转换为.npy文件,下面是转换脚本:
import caffe
import numpy as np
MEAN_PROTO_PATH = '/home/pzs/husin/Caffe_carPlate/lmdb/meantrain.binaryproto'
MEAN_NPY_PATH = '/home/pzs/husin/Caffe_carPlate/lmdb/mean.npy'
blob = caffe.proto.caffe_pb2.BlobProto()
data = open(MEAN_PROTO_PATH, 'rb').read()
blob.ParseFromString(data)
array = np.array(caffe.io.blobproto_to_array(blob)) # 将blob中的均值转换成numpy格式文件
mean_npy = array[0]
np.save(MEAN_NPY_PATH, mean_npy)
运行脚本得到mean.npy文件。
接下来用训练好的模型对一张图片进行分类:
在prototxt文件夹下创建deploy.protoxtx文件,内容如下:
name: "LeNet"
layer {
name: "data"
type: "Input"
top: "data"
input_param { shape: { dim: 10 dim: 1 dim: 32 dim: 32 } }
}
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 20
kernel_size: 5
stride: 1
}
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "conv2"
type: "Convolution"
bottom: "pool1"
top: "conv2"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 50
kernel_size: 5
stride: 1
}
}
layer {
name: "pool2"
type: "Pooling"
bottom: "conv2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "ip1"
type: "InnerProduct"
bottom: "pool2"
top: "ip1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
inner_product_param {
num_output: 1000
}
}
layer {
name: "relu1"
type: "ReLU"
bottom: "ip1"
top: "ip1"
}
layer {
name: "ip2"
type: "InnerProduct"
bottom: "ip1"
top: "ip2"
param {
lr_mult: 1
}
param {zifu
lr_mult: 2
}
inner_product_param {
num_output: 67
}
}
layer {
name: "prob"
type: "Softmax"
bottom: "ip2"
top: "prob"
}
网络结构如下:

在项目根目录下创建recognize.py, 内容为:
#coding=utf-8
import caffe
import numpy as np
def faceRecognition(imagepath):
root = '/home/pzs/husin/Caffe_carPlate/'
deploy = root + 'prototxt/deploy.prototxt'
caffe_model = root + 'backups/lenet_solver_iter_5000.caffemodel'
mean_file = root + 'lmdb/mean.npy'
img = imagepath
labels_filename = root + 'data/labels.txt'
net = caffe.Net(deploy, caffe_model, caffe.TEST) # 加载model和network
transformer = caffe.io.Transformer({'data': net.blobs['data'].data.shape}) # 设置图片的shape格式(1,1,32,32)
transformer.set_transpose('data', (2,0,1)) # 改变维度的顺序,由原始图片(32,32,1)变为(1,32,32)
transformer.set_mean('data', np.load(mean_file).mean(1).mean(1)) # 减去均值 ####
transformer.set_raw_scale('data', 255)
net.blobs['data'].reshape(1, 1, 32, 32)
im = caffe.io.load_image(img, False) # 加载图片
net.blobs['data'].data[...] = transformer.preprocess('data', im) # 执行上面设置的图片预处理操作,并将图片载入到blob中
# 执行测试
out = net.forward()
labels = np.loadtxt(labels_filename, str, delimiter='\t')
prob = net.blobs['prob'].data[0].flatten() # 取出最后一层(Softmax)属于某个类别的概率值,并打印
order = prob.argsort()[-1] # 将概率值排序,取出最大值所在的序号
character = labels[order]
return character # character是最终识别的字符
character = faceRecognition('/home/pzs/husin/Caffe_carPlate/zh_shan.jpg')
print(character)
随便一张图片来测试
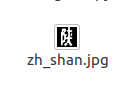
执行py脚本,结果如下:

结果正确,成功的识别了中文字符。
工程地址:
(完整的工程项目,包括训练数据集和训练结果模型)
https://download.csdn.net/download/huxiny/11058110
