文章目录
前言
RocksDB作为单例数据存储引擎,它能支持良好的数据吞吐量,同样可以很好地作为大型分布式系统元数据的持久化存储。RocksDB作为存储框架,其内部在设计实现中有着许多与分布式存储系统相似的地方,例如包括数据索引,数据限流等等。比本文,笔者将简单聊聊RocksDB内部一些精妙的设计实现。
RocksDB部分功能设计
笔者这里简单挑选了以下5个设计点:
- Auto RateLimiter,自适应限流器,相比较于平常我们往往对IO操作做指定速率的限制,RocksDB在这里实现了自适应的限流器,自适应调整的做法弥补了指定限流速率做法的不足之处。
- Bulkloading by ingesting external SST file,大批量数据的离线导入。当我们有大量的数据准备写入系统时,我们有额外离线写入SST文件的方式,而非调用PUT操作一次次将记录写入,前者比后者高效不少。
- Bloom Filter,布隆过滤器,用以判断待查询key是否存在于所查询的SST文件内。
- Hash index to speed up point lookup,哈希索引加速数据key的查找,在RocksDB的SST文件内,额外设计了哈希索引增加查询效率,相比较于原先的二分查找方式。
- Indexing SST Files for Better Lookup Performance,添加SST索引提升key查找速度。和上一点提高在一个SST文件内的key查找,这里的索引指的跨SST文件间的。
下面我们逐一对上述功能设计做简单阐述。
Auto RateLimiter
RocksDB内部为了避免后台IO写入操作过快导致潜在对于用户Put操作的影响,于是设计了RateLimiter限流功能。限流器的设计在很多其它分布式系统内也比较常见,不过RocksDB在这里实现了更为智能化一些的RateLimiter。这个RateLimiter不是使用一个固定传入的限流值做流控,而是给定一个Rate的上界,下界。
当当前限定的Rate Limiter速率值被打破时(低于或高于当前值),则进行Rate Limiter在给定的range范围内的速率调整。
Bulkloading by ingesting external SST file
当用户需要进行大规模数据导入的时候,如果我们还是采用按照一条条记录PUT写入的方式做处理时,会引发大量的操作,而且还会影响到其它用户的PUT写入操作。
因此在RocksDB中,它支持预先离线写入K-V值到SST文件的方式,然后再将这些SST文件添加到RocksDB内部,这其中的过程包括SST sequence number号的生成,metadata block数据的关联,LSM树的重新组织等等。
Bloom Filter
为了快速查找某个key是否存在于某个SST文件内,RocksDB会为每个SST文件单独存有对应的Bloom Filter内容文件。SST文件的key会经过哈希算法,被转化为多个位值表示。这些位值对应的Bloom Filter下标数组为将被标为1。key判断查找的时候就通过数组位值是否全为1来判断key是否存在于SST文件内。
每个SST文件对应的Bloom Filter内容会在初始时加载到内存中,然后后续key的判断在内存中的Bloom Filter内进行判断。

哈希索引加速数据key的查找
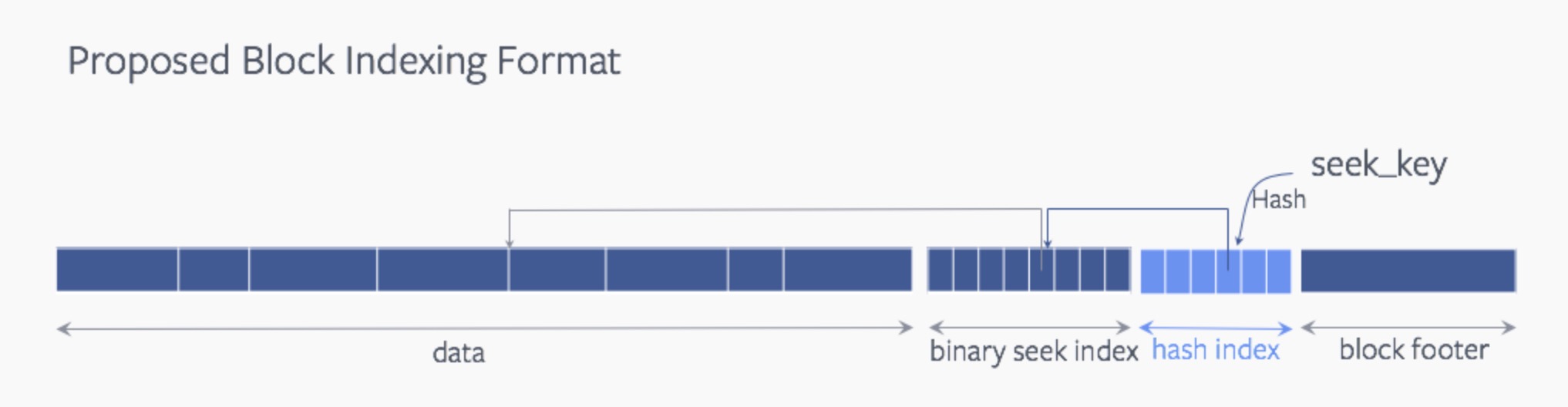
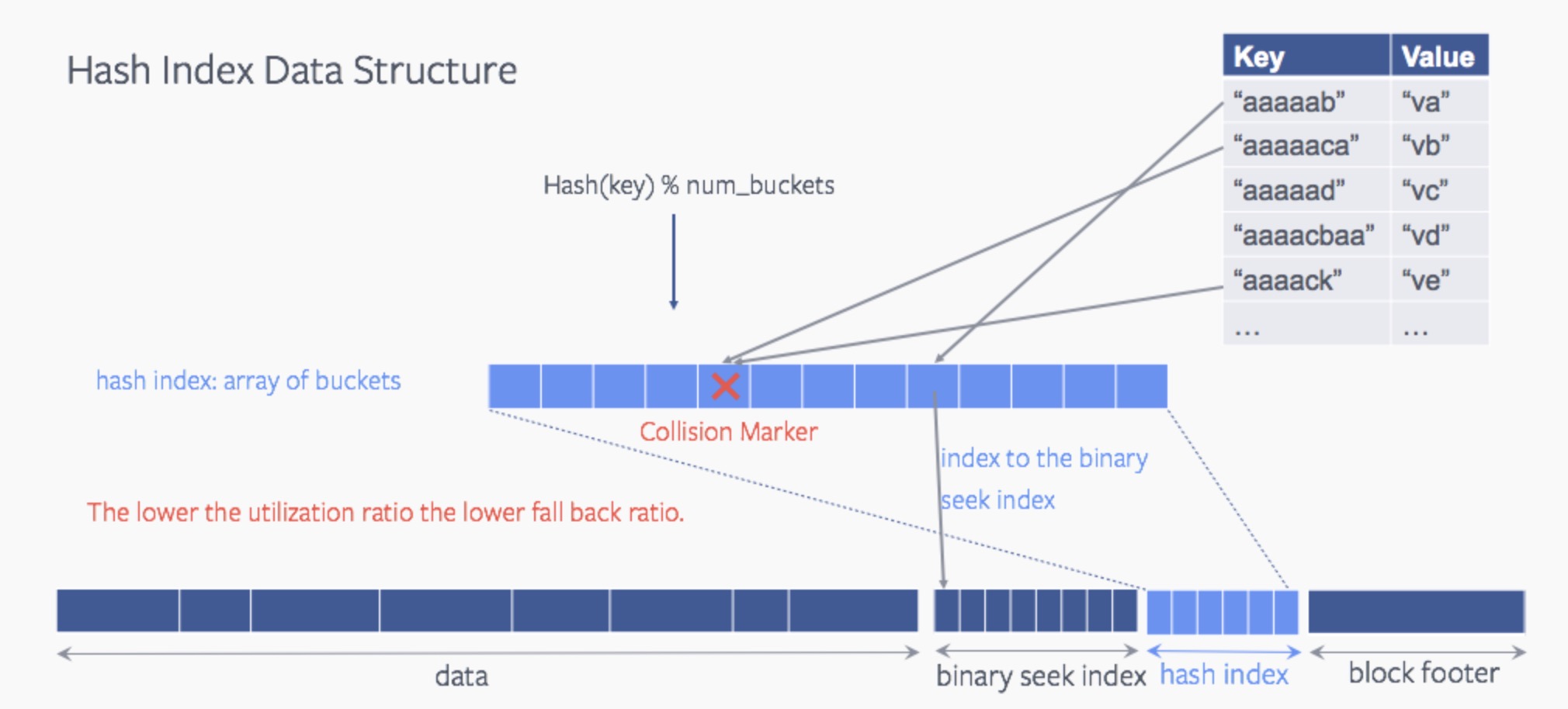
在传统方式下,RocksDB对一个SST文件进行key查找时采用的是二分查找的方式。为了加速对于key的查找,RocksDB内部在SST文件内添加了额外的结构来支持哈希索性。简单的解释就是哈希索性会通过key给出对应实际key的索性位置,然后系统根据key索性提供的位置信息进行实际数据的读取。哈希索性带来的主要变化key只要经过一次查找就能找到位置索性信息,而不是进行全局二分查找索性位置。如果此过程中存在多个key到同一个值的情况即哈希冲突的情况,则对这些key进行failback的处理,退回到二分查找的方式。
以下是官网介绍的查找方式图:
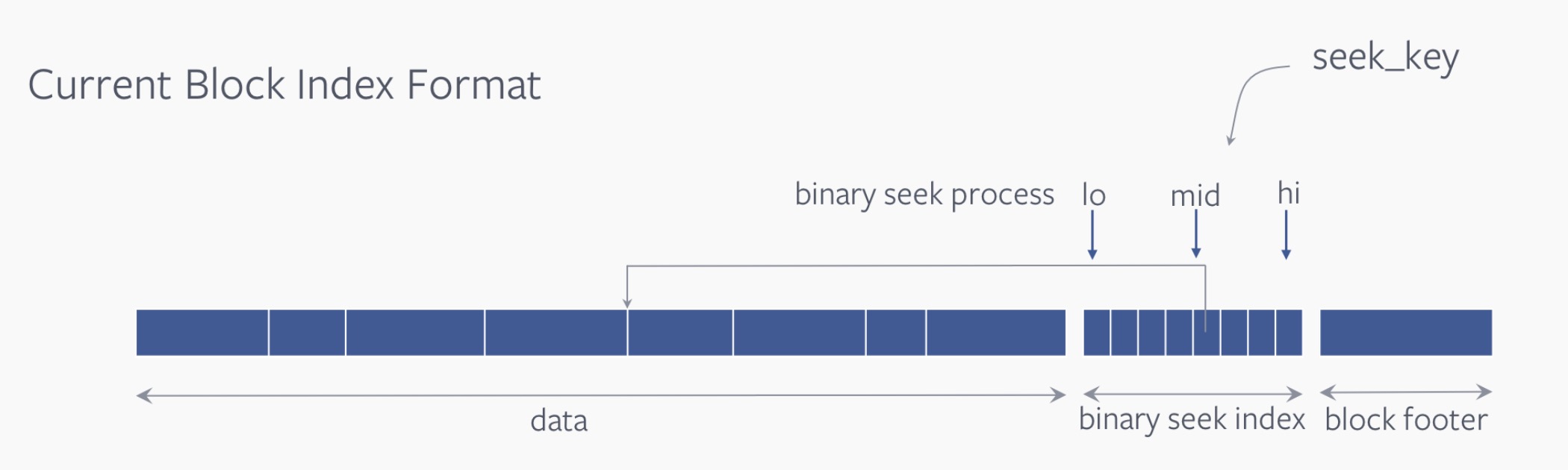
1.原始二分查找key的方式
在data段内,相邻的key会被组织在一起分组存放。这里二分查找的位置即每个block段的offset值。
2.增加了哈希索引查找的方式
3.哈希索引查找冲突,退回到二分查找方式
SST文件的索性查找
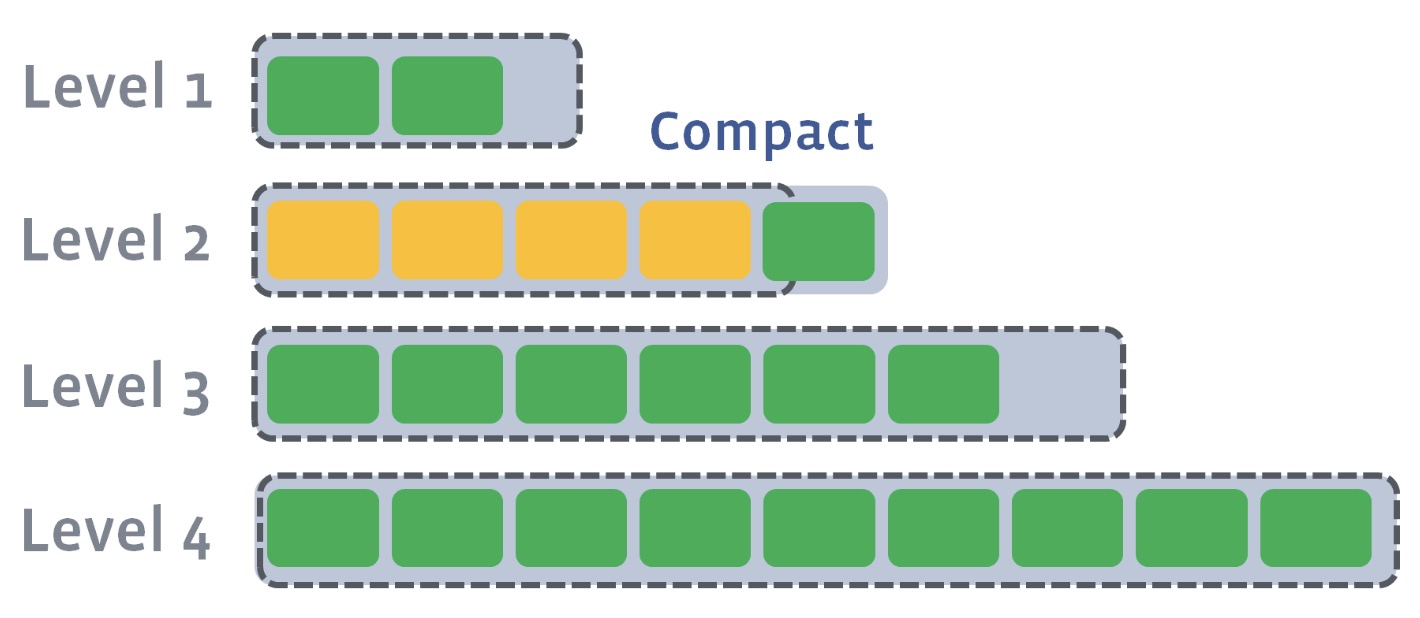
在RocksDB中,存在定期Compact行为来将低level的SST文件合并到高level的文件内,以此去除无效key,重复key的存放。
Compact行为如下图所示:
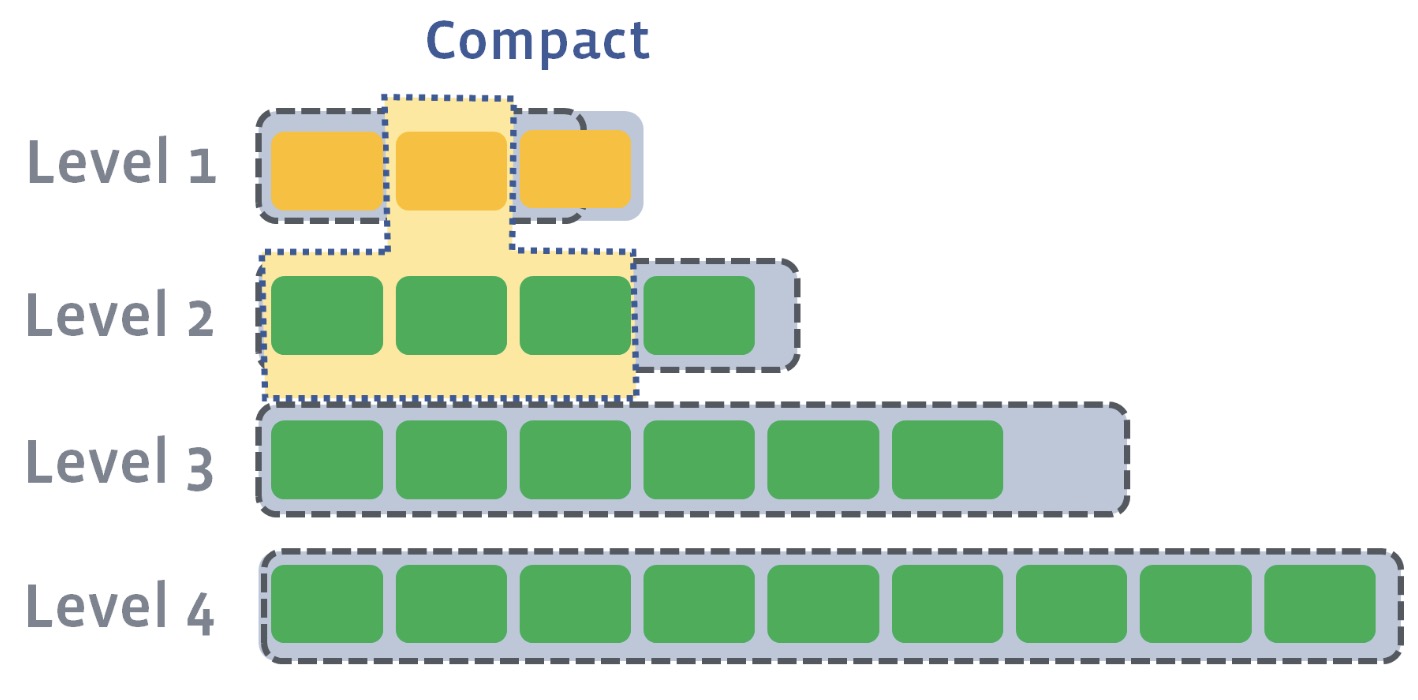
Compact操作后,
所以有的时候我们需要查询的key并不是在一个SST文件内能被立马查询到,它可能存在于别的SST文件内。在此SST文件组织前提下,我们自然联想到的查找方式是串行逐一进行SST文件的查找。但是这种查询是一种高效的查询方式吗?里面是否存在无效的查找过程呢?
其实SST文件在每个Level段内是有按照key进行排序的,而且上个level段的SST文件也能找到对应下level段的一个位置,如下:
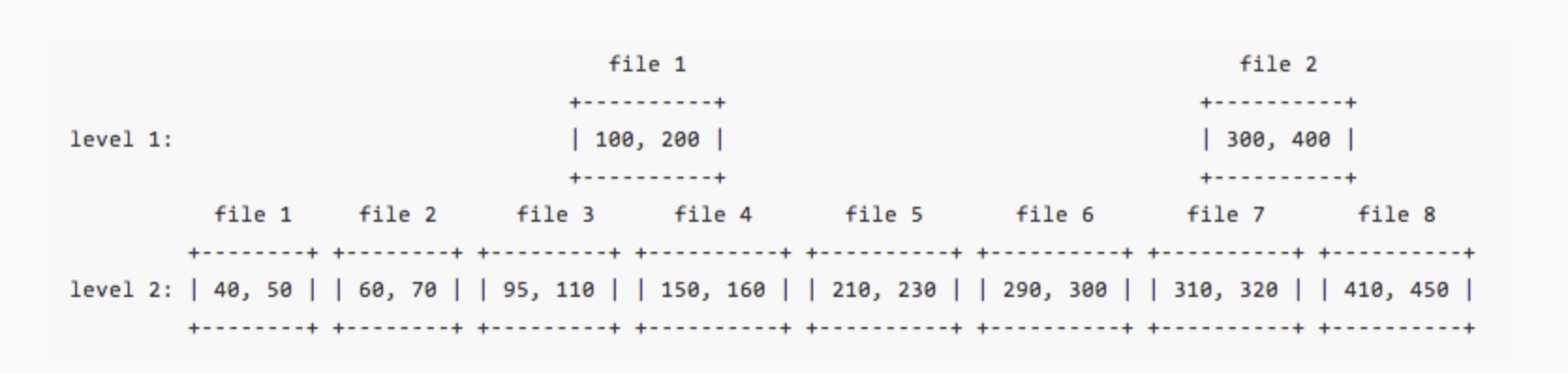
如上图所示,level1内的file1对应level2的位置在file3,file4间。因此假设我们有个待查询key为280,然后系统发现在level1的file1和file2的key区间都没有包含此key,则它可以在level2中直接缩小范围进行查找,范围段为[file1在level2的上界, file2在level2的下界],也就是说level2的file4,5,6和7这四个文件中进行查找。
通过上下SST文件索引信息的记录,我们可以减少不必要的SST文件查找过程,提升key查找效率。
RocksDB内部有着很多好的设计和实现,笔者今天简单挑选了其中的一小部分做了阐述,更多内容可详见RocksDB官方博客或wiki链接。
引用
[1].https://rocksdb.org/blog/2018/08/23/data-block-hash-index.html . Improving Point-Lookup Using Data Block Hash Index
[2].https://rocksdb.org/blog/2014/04/21/indexing-sst-files-for-better-lookup-performance.html . Indexing SST Files for Better Lookup Performance
