例如:
student(U , D , DOM , F)
U={ studentID , name , sex, department}
D:D1={数字或字符组成的字符串}
D2={英文或汉字}
D3={男,女}
D4={院系}
DOM:DOM{studentID}=D1
DOM{name}=D2
DOM{sex}=D3
DOM{department}=D4
F:studentID--->name
studentID--->sex
studentID--->department
ps:数据库模型分为数据模型、E-R模型、关系模型、层次模型和网状模型,其中关系模型是无数个关系模式的集合,而关系模式是对关系的描述。
2、规范化
我们可以通过设计适当的范式的模式来进行关系数据库的设计,我们主要有6种范式,分为1NF、2NF、3NF、BCNF、4NF和5NF,一般我们将一个低级的关系模式转换成若干个高级范式,这种过程就叫规范化。
(1)第一范式(1NF)
在关系模式R中,当且仅当所有域只包含原子值,即每个分量都是不可再分的数据项,则称关系模式R属于第一范式。所谓的不可再分就是实体的该属性不能含有多个值或者是不能有重复的属性值,如果有重复的属性值出现,那么就要定义一个新的实体,新的实体由重复的属性构成,并且新实体与实体之间是一对多的关系。
ps:在关系数据库中,任何关系数据库都必须满足第一范式,不满足第一范式的数据库就不是关系数据库。
例如:student{ studentID , name , name, sex, department },这个学生表就不符合第一范式,因为name属性重复了
正确的表:
student{ studentID , name , sex, department }
(2)第二范式(2NF)
第二范式的前提是必须满足第一范式,如关系模式R满足了第一范式,并且每个非主属性完全依赖于码,则关系模式R属于第二范式。也就是说在满足第一范式的条件下,关系模式R要求的实体的属性必须完全依赖于主键,完全依赖是说不能存在仅依赖主键一部分的属性。倘若存在,那么这个属性和主键的这部分就得分离出来重新定义一个实体,新实体与原实体之间是一对多的关系。为了区分通常要在表上加上一列来存储各个实例的唯一标识。
例如:有一张学生课程成绩表:
student{stuNo,stuName,age,sex,courseNo,courseName,credit,score} 如图:
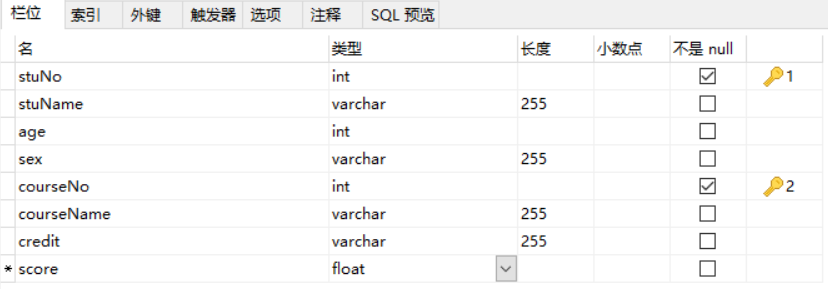
从上图得知该表有两个主键,因此该表的主键是联合主键(stuNo,courseName),从表可以看出,主键stuNo和courseName可以唯一确定score属性值,符合第二范式要求,但是,表中其他的属性,比如stuName属性可以直接由stuNo唯一确定,courseName属性可以直接由courseNo唯一确定,这就出现了仅依赖主键的一部分,不符合完全依赖,所以不符合第二范式,因此这张表就不符合第二范式。
如果想要让这表符合第二范式,那么就要将这张表进行拆分,前面提到进行拆分时要将依赖主键一部分的属性和主键分离出来建立新表,分离结果如下:
stuName、age、sex都是依赖部分主键stuNo
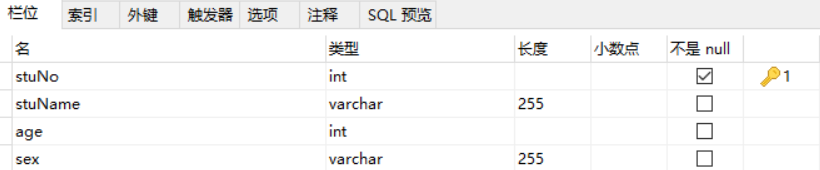
courseName、credit都依赖部分主键courseNo

分离到最后的原表为:

(3)第三范式(3NF)
如果关系模式R满足第二范式(2NF)并且R中的非主属性都不传递依赖与R中的候选码,则称该关系模式R为第三范式(3NF)。也就是说在满足第二范式的条件下,只要满足不存在X在属性组Y及非主属性Z(Z⊄Y)使得X->Y,Y->Z就说明该关系模式为第三范式。
例如:
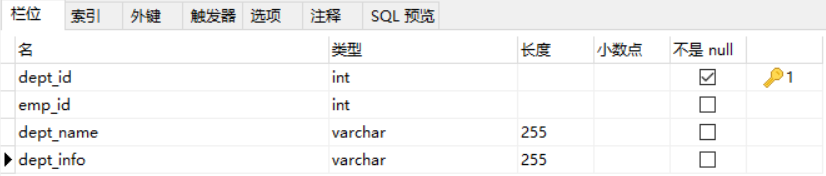
这有一张员工信息表,Employee(emp_id,emp_name,emp_age,dept_id,dept_name,dept_info)
如图:
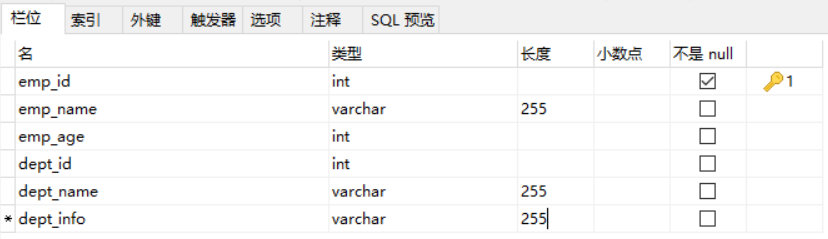
从表中我们可以看出主键是emp_id,它能唯一标识确定其他所有属性,所以dept_id在这里是属于非主属性,但是,我们发现dept_name依赖于dept_id,而dept_id又依赖于emp_id,因此这就存在了传递依赖,此外传递依赖存在一个很大的缺点,数据冗余。
我们的解决方法是将存在传递依赖的属性分离出来,重新定义一个表,这里的dept_name和dept_info存在传递依赖,所以将这两个属性删掉然后新建一个表,如图:
删除后的原表:
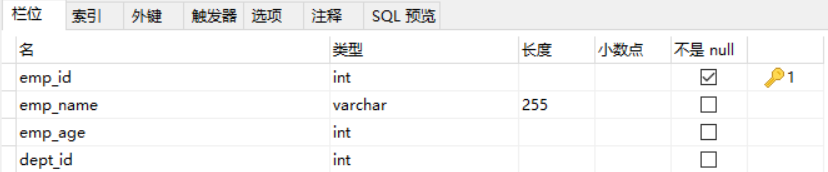
新建的表:
(4)巴克斯范式(BCNF)
当3NF消除了主属性对码的部分依赖和传递依赖,则称为BCNF。BCNF是实质上是3NF的升级版,3NF只是考虑了非主属性对键的依赖情况,而BCNF除此之外还考虑了主属性对键的依赖情况,BCNF要求的条件比3NF的要高,因此如果关系模式是BCNF的,则该关系模式必然3NF,反之则不成立。特性如下:
1.所有非主属性对每一个码都是完全函数依赖。
2.所有的主属性对每一个不包含它的码,也是完全函数依赖。
3.没有任何属性完全函数依赖于非码的任何一组属性。
例如:
假设仓库管理关系表为StorehouseManage(仓库ID, 存储物品ID, 管理员ID, 数量),且有一个管理员只在一个仓库工作;一个仓库可以存储多种物品。这个数据库表中存在如下决定关系:
(仓库ID, 存储物品ID) →(管理员ID, 数量)
(管理员ID, 存储物品ID) → (仓库ID, 数量)
所以,(仓库ID, 存储物品ID)和(管理员ID, 存储物品ID)都是StorehouseManage的候选关键字,表中的唯一非关键字段为数量,它是符合第三范式的。但是,由于存在如下决定关系:
(仓库ID) → (管理员ID)
(管理员ID) → (仓库ID)
即存在关键字段决定关键字段的情况,所以其不符合BCNF范式。
把仓库管理关系表分解为二个关系表:
仓库管理:StorehouseManage(仓库ID, 管理员ID);
仓库:Storehouse(仓库ID, 存储物品ID, 数量)。
这样的数据库表是符合BCNF范式的。
(5)第四范式(4NF)
4NF是限制关系模式的属性间不允许有非平凡且非函数的多值依赖。由于第四范式软考不怎么考,所以在这里就不详细讲解。
PS:如果还没看明白可以看看别的大神的理解:点击打开链接