DataFrame创建
DataFrame是一个【表格型】的数据结构,可以看做是【由Series组成的字典】(共用同一个索引)。DataFrame由按一定顺序排列的多列数据组成。设计初衷是将Series的使用场景从一维拓展到多维。DataFrame既有行索引,也有列索引。
行索引:index
列索引:columns
值:values(numpy的二维数组)
DataFrame的创建
最常用的方法是传递一个字典来创建。DataFrame以字典的键作为每一【列】的名称,以字典的值(一个数组)作为每一列。
此外,DataFrame会自动加上每一行的索引(和Series一样)。
同Series一样,若传入的列与字典的键不匹配,则相应的值为NaN。
from pandas import DataFrame
# data=None numpy.array 2维度表格
# index=None 行索引, 所有的Series对象公用一个行索引
# columns=None 列索引, 每一个Series的name属性
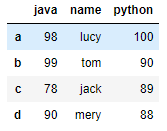
dic = {
"name":["lucy","tom","jack","mery"],
"python":[100,90,89,88],
"java":[98,99,78,90]
}
DataFrame(data=dic, index=list("abcd"))
输出:
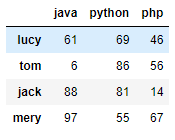
index = ["lucy","tom","jack","mery"]
columns = ["java","python","php"]
data = np.random.randint(0,100,size=(4,3))
DataFrame(data=data, index=index, columns=columns)
输出:
从文件中读取DataFrame对象
读取一个excel表格
- index_col 以哪一列作为行索引
- header 指定哪一行作为列索引
- sheet_name 可以设置工作表的索引或名称
import pandas as pd
df = pd.read_excel('data.xlsx', index_col=0, sheet_name=0)
df
使用Series构造DataFrame
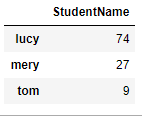
s = Series(data=np.random.randint(0,100,size=3), index=["lucy","mery","tom"],name="StudentName")
DataFrame(data=s)