-
装箱问题(贪心算法)
/*
- 问题描述:
* NUM个物品装入体积为V的箱子中,装入箱子的物品的总体积小于等于V。
* 现要求使用最少数量的箱子将这NUM个物品都放置进去。
- 此算法的一点说明:
* 该算法把使用到的箱子组成了一个链表。
*/
#include<stdio.h>
#include<stdlib.h>
#define NUM 6 //物品数量
#define V 100 //箱子的容积
typedef struct box //该结构体表示一个容积为V的箱子
{
int no; //箱子的编号
int size; //箱子中装入的物品的总体积
struct box * next; //指向下一个箱子
}BOX;
void scan(int obj[]); //输入NUM个物品的体积,并按照从大到小的顺序将其重新排列
int putInBox(int obj[]); //存放NUM个物品到箱子里
BOX* find_p(BOX* H, int volume); //给物品i(体积为volume)找到一个合适的位置,并返回这个位置
void add_list_tail(BOX *H, BOX *p); //将新建的箱子添加到H尾部
void print_list(BOX* H); //打印装箱结果
void init_list(BOX** H);
void main()
{
int obj[NUM], count;
scan(obj);
count = putInBox(obj);
printf("箱子总数:%d", count);
}
void scan(int obj[])
{
int i, j, temp, maxNumIndex;
printf("请输入这%d件物品的体积:", NUM);
for(i = 0; i < NUM; i++)
{
scanf("%d", &obj[i]);
}
for(j = 0; j < NUM-1; j++) //选择排序法
{
maxNumIndex = j;
for(i = j + 1; i < NUM; i++)
{
if(obj[maxNumIndex] < obj[i])
maxNumIndex = i;
}
if(maxNumIndex != j)
{
temp = obj[j];
obj[j] = obj[maxNumIndex];
obj[maxNumIndex] = temp;
}
}
}
int putInBox(int obj[])
{
int count = 0, i;
BOX* H = NULL;
//初始化首节点指针(该结点不用来装物品,仅仅用到它的next项 ——用来指向后面盛物品的箱子)
init_list(&H);
//开始将NUM个物品放入箱子
for(i = 0; i < NUM; i++)
{
//给物品i(体积为obj[i])找到一个合适的位置p
BOX* p = find_p(H, obj[i]);
//p可能为null,表示已存在的箱子都无法放入这个物品了;那么下一步就需要新建一个箱子
if(p == NULL)
{
count++;
p = (BOX*)malloc(sizeof(BOX));
p->no = count;
p->size = obj[i];
p->next = NULL;
add_list_tail(H, p);
}
else
{
p->size += obj[i];
}
}
print_list(H);
return count;
}
BOX* find_p(BOX* H, int volume)
{
BOX* p = H->next;
// p != null :表示p指向了某个箱子,那么进一步我们就要判断这个箱子可不可以装下这个物品
while(p != NULL)
{
if(p->size + volume <= V)
break;
p = p->next;
}
return p; //注意:p可能指向一个已存在的箱子,但也有可能为null
}
void print_list(BOX* H)
{
BOX* q = H->next;
while(q != NULL)
{
printf("%d号箱子中所装物品的总体积为:%d\n", q->no, q->size);
q = q->next;
}
}
void add_list_tail(BOX *H, BOX *p)
{
BOX* q = H;
while(q->next != NULL)
{
q = q->next;
}
q->next = p;
}
void init_list(BOX** H)
{
*H = (BOX*)malloc(sizeof(BOX));
(*H)->no = 0;
(*H)->size = 0;
(*H)->next = NULL;
}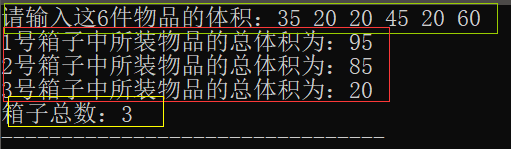

为何会称之为贪心算法呢?拿上面的一组数据为例,我们知道算法得出的结果是需要3个箱子。但实际上,只需要两个箱子,分别装60/20/20和45/35/20。所以说,贪心算法不一定能找到最优解,而是最优解的近似解。
-
找零方案(贪心算法)
/*
- 问题描述:
* 编写一段程序实现找零方案。
* 输入需要补给客户的金额,然后通过程序找出该金额找零的人民币张数最少的一组结果。
* 人民币有100元、50元、20元、10元、5元、1元、0.5元、0.1元的面额。
- 关键一点:
* 为了简化此算法,应该把小数类型的金额都变成整数!
*/
#include<stdio.h>
#define PARVALUE_NUM 8 //人民币的面额共有8种
int parvalue[PARVALUE_NUM] = {10000, 5000, 2000, 500, 100, 50, 10}; //8种面额均扩大100倍,都按照整数来算
int num[PARVALUE_NUM] = {0}; //保存找零结果:需要100元num[0]张,需要50元num[1]张...
void exchange(int m);
void main()
{
float m;
printf("请输入找零的金额(保留小数点后两位):");
scanf("%f", &m);
exchange((int)100*m); //注意:把m变成整数
printf("%.2f元零钱的组成:\n", m);
int i=0;
for(i; i < PARVALUE_NUM; i++)
{
if(num[i] > 0)
{
printf("%.2f元: %d张\n", parvalue[i]/100.0, num[i]);
}
}
}
void exchange(int m)
{
int *result, i;
for(i=0; i < PARVALUE_NUM; i++)
{
if(m >= parvalue[i])//找到比m小的最大面额或等于m的面额
break;
}
while(m > 0 && i < PARVALUE_NUM)
{
if(m >= parvalue[i])
{
m -= parvalue[i];
num[i]++;
}
else if(m < 10 && m >= 5)//表示末位大于等于5小于等于9,此时找一个一毛钱
{
num[PARVALUE_NUM-1]++;
break;
}
else
i++;
}
}
-
彩票组合(试探法)
问题描述:假设有一种彩票,每注由7个1~29的数字组成,且这七个数字不能相同,编写程序生成所有的号码组合。
碎碎念:想要穷举?不可能。。。时间复杂度太大了。嗯,要用试探法。
#include<stdio.h>
#define N 7
#define MAX 29
void produce(int n, int m);
int lottery[N] = {0}, num[MAX];
void main()
{
int i;
for(i = 0; i < MAX; i++)
num[i] = i+1; //备选号1~29
produce(MAX, N);
}
void produce(int n, int m)
{
int i, j;
for(i = n; i >= m; i--)
{
lottery[m-1] = num[i-1];
if(m > 1)
produce(i-1, m-1);
else //m为1,可打印出一注彩票
{
for(j = N - 1; j >= 0; j--)
printf("%3d", lottery[j]);
printf("\n");
}
}
}
嗯...看起来不像是试探,而是穷举...因为每个组合都是符合要求的一组结果,这得益于算法的写法,已经不可能出现重复的了。看上图易明白。
-
求模式串在文本串中的匹配位置(DP)(KMP)
下面都是将str看做文本串,ptr看做模式串,我们想要查找模式串ptr在文本串str中的位置,即str中与ptr匹配的部分。下面有两种方式可以进行匹配,一种是时间复杂度高的“暴力匹配”,一种是经过优化了的“KMP算法匹配”。PS. 关于两者的时间复杂度,将在讲解完两算法后进行分析
一、暴力匹配
假设现在文本串str匹配到 i 位置,模式串ptr匹配到 j 位置,则有:
- 如果当前字符匹配成功(即str[i] == ptr[j]),则i++,j++,继续匹配下一个字符;
- 如果当前字符匹配失败(即str[i] != ptr[j]),令i = i - (j - 1),j = 0。
- 匹配失败时的操作的实质:i回溯(j-1) 个位置,j 被置为0。以期望重新开始进行匹配。至于为何回溯(j-1) 个位置,下面看图很容易理解:
- 对于上图来说,回溯过去后同样不匹配,又需要重新变换i和j的值。所以此次回溯其实是一种无用功,那么如何避免这种无用功呢?有没有一种办法可以让i 不必往回退,只需要移动j 即可呢?答案是肯定的,即下面要介绍的KMP算法。

一段完整代码(考虑到了有多部分匹配的情况) :
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
int* ViolentMatch(char* s, char* p);
int main()
{
char *str = "aaaabceabce";
char *ptr = "abce";
int *index = ViolentMatch(str, ptr), i;
if(index == NULL)
{
printf("文本串中没有与模式串匹配的部分!");
return 0;
}
for(i = 0; i < sizeof(index)/sizeof(int); i++)
{
if(index[i] != -1)
printf("文本串中从第%d个字符处开始与模式串匹配。\n", index[i] + 1);
}
return 1;
}
int* ViolentMatch(char* s, char* p)
{
int sLen = strlen(s);
int pLen = strlen(p);
int n = sLen/pLen; //最多能匹配到n份
int *index = (int *)malloc(n * sizeof(int));
int k, i = 0, j = 0, x = 0;
for(k=0; k < n; k++)
{
index[k] = -1;
}
while (i < sLen && j < pLen)
{
if (s[i] == p[j])
{
//如果当前字符匹配成功(即str[i] == ptr[j]),则i++,j++
i++;
j++;
if (j == pLen) //已匹配到一组,先保存起来。
{
index[x++] = i - j;
j = 0;
//x需要调整到下一个,但前面已经做了,所以此处不可再使i++
}
}
else
{
//如果当前字符匹配失败(即str[i] != ptr[j]),令i = i - (j - 1),j = 0
i = i - j + 1;
j = 0;
}
}
if (index[0] != -1 )
return index;
else
return NULL;
}

二、KMP算法匹配
Knuth-Morris-Pratt 字符串匹配算法,简称为 “KMP算法”,常用于在一个文本串S内查找一个模式串P 的出现位置,这个算法由Donald Knuth、Vaughan Pratt、James H. Morris三人于1977年联合发表,故取这3人的姓氏命名此算法。
KMP算法的关键是利用匹配失败后的信息以及模式串本身具有的特点,使得在匹配失败时,能够尽量减少模式串与主串的匹配次数以达到快速匹配的目的。具体实现就是实现一个next()函数,该函数本身包含了模式串的局部匹配信息。
假设现在文本串str匹配到 i 位置,模式串ptr匹配到 j 位置,则:
- 如果j = -1,或者当前字符匹配成功(即S[i] == P[j]),则令i++,j++,继续匹配下一个字符;
- 如果j != -1,且当前字符匹配失败(即S[i] != P[j]),则令 i 不变,j = next[j]。
- 匹配失败时的操作的实质:模式串ptr下一次比较的字符的索引变为next[j],此值大于0。如果next [j] 等于0或-1,则表示跳到模式串的开头字符。这里先不必知道next[ ]的含义,我们可以实现如下代码:
int KmpSearch(char* s, char* p, int next[]) { int i = 0; int j = 0; int sLen = strlen(s); int pLen = strlen(p); while (i < sLen && j < pLen) { // 如果j = -1,或者当前字符匹配成功(即S[i] == P[j]),则令i++,j++,继续匹配下一个字符 if (j == -1 || s[i] == p[j]) { i++; j++; } else { // 如果j != -1,且当前字符匹配失败(即S[i] != P[j]),则令 i 不变,j = next[j] j = next[j]; // next[j]即为j所对应的next值 } } if (j == pLen) return i - j; else return -1; }
- 至于为何匹配失败时,回溯到next[j]位置,我们先不必知道。讲解完如何求next[ ]后再讲解其中的过程。
下面,最重要的,如何写next()函数得到next[ ]数组?
首先要知道的是next[ ]数组在本算法中指的是什么:某字符串的前缀和后缀能够匹配上的最大长度;此处“某字符串”指的是“当前ptr正在匹配的字符之前的(不包括正在匹配的这个字符)那些字符所组成的字符串”。例如next [j] = k代表:j 之前的字符所组成的字符串中有最大长度为k 的相同前缀后缀。下面看一个实例,这里假设模式串为“abaabcac”,则:
next[0] = -1 索引0前的字符串:空 —— 规定为-1
next[1] = 0 索引1前的字符串:a —— 规定为0
next[2] = 0 索引2前的字符串:ab —— 前缀和后缀没有匹配部分,所以为0. (如果是“aa”, 则最长相同前缀后缀为1)
next[3] = 1 索引3前的字符串:aba —— 最长相同前缀后缀为1,即“a”
next[4] = 1 索引4前的字符串:abaa —— 最长相同前缀后缀为1,即“a”
next[5] = 2 索引5前的字符串:abaab —— 最长相同前缀后缀为2,即“ab”
next[6] = 0 索引6前的字符串:abaabc —— 最长相同前缀后缀为0
next[7] = 1 索引7前的字符串:abaabca —— 最长相同前缀后缀为1,即“a”
- 注意:前缀和后缀都是从左往右看的,请参考next[5]的结果。
知道了上面的求法,下面写代码进行实现。那我们先分析其中的规律,仍以模式串“abaabcac”为例:
- 当我们求next[5]时,应该让ptr[1]与ptr[4]比较,结果是ptr[1] == ptr[4]。又因为next[4] = 1,所以next[5]应该为next[4] + 1,即2。用代码表示这种情况:next[i+1] = next[i] + 1; (这里的‘i+1’对应下面代码中的‘i++’,‘next[i] + 1’对应下面代码中的‘j++’)
- 而当我们求next[6]时,让ptr[2]与ptr[5]比较,发现ptr[2] != ptr[5](‘a’与‘c’比较),那此时就不能简单的令next[6] = next[5] + 1了,而是去寻求较短的一个能够匹配的前缀与后缀。即,我们发现“aba”与“abc”不匹配,所以我们看“ab”与“bc”是否匹配,结果又是不匹配;那么继续看“a”与“c”是否匹配,结果是不匹配。所以,当此轮比较的结果是不匹配时,下一步要进行比较的字符应该如何设置呢?答案就是,此时我们仍要利用前面得出的匹配结果来更高效地得出本轮结果(是的,文本串与模式串匹配时也是使用了我们找出了的全部next值;而模式串的“自身匹配”时,也用到了已产生的next值)。
啊,如何利用呢?先看个图:
图中,第一个k部分中的两个蓝色区域是匹配的;而又因为两个k部分是匹配的,所以图中的四个蓝色部分都是匹配的。此时我们正在比较ptr[k] 与ptr[j],结果是不匹配。根据上面我们得到的“对称信息”(即,匹配信息),我们发现,下一步我们可以直接比较ptr[ next[k] ]!所以,应该令j = next[k]啊!(这是递归的一种体现,递归出口是j = -1)
分析完在比较字符是否匹配时的两种结果后,现在我们可以看代码了:
void get_Next(char* ptr, int next[]) { int pLen = strlen(ptr); next[0] = -1; int i = 0, j = -1; //i用来从0开始遍历模式串,从而为模式串的每一个字符找出正确的next值 //j用来设置next[i]值;j的初值设为-1是因为执行if(j == -1 || s[i] == s[j])时,将next[1]置为0 //i值一直处于前进状态;j会回退——当不符合条件时,j回退到next[j] while(i < pLen - 1) { if(j == -1 || ptr[i] == ptr[j]) //注意:两条件不能交换位置,因为j为-1时执行ptr[j]是越界的,但如果先判断j == -1,则符合的话就不会执行后面的条件了 //ptr[i]表示后缀;ptr[j]表示前缀 { i++; j++; next[i] = j; } else { j = next[j]; } } }

上面我们还遗留了一个问题,也就是文本串与模式串进行匹配时,遇到两字符不匹配的情况时,为何令j变为j = next[j](两段代码中都有此语句,要注意弄清两者的含义。这是最关键的语句了)?下面就可以进行具体的过程分析了。
我们对模式串做了如上分析得到next[ ]数组后,在进行字符的匹配时,我们可以将字符串看成下面的样子:图中的模式字符串3,4部分是一样的,即我们求出的next[j]部分。在索引j之前,文本串与模式串都是匹配的(1,2,3,4部分相同),但索引j对应的两字符不再匹配。此时,从图中易知,我们下一步可以直接让3部分与2部分对应起来,然后比较C和A是否一样。(倘若使用“暴力匹配算法,那就是让模式串重新与文本串的索引为1处对齐,你知道,这并不匹配!只会让我们做更多无用功)
上图我们知道了,'A'和'B'不匹配时,我们下一步是让'B'和'C'进行比较,易知,文本串比较的索引值不变,而模式串的索引值应该从j变为next[j]!
到此为止,KMP算法已介绍完毕。加上下面的main()就可以运行出结果(C语言实现):
#include<stdio.h>
#include<string.h>
void get_Next(char* ptr, int next[]);
int KmpSearch(char* s, char* p, int next[]);
void main()
{
char *str = "aaabcdef";
char *ptr = "abc";
int n = strlen(ptr), index;
int next[n], ;
get_Next(ptr, next);
index = KmpSearch(str, ptr, next);
printf("%d", index);
}实际上,KMP算法还可以进一步优化,此处不再涉及,有兴趣可以看这里。
三、KMP算法的一点优化
考虑这样一种情况:
模式串与文本串匹配时失配(图中的一行数字表示对应的next值):
下一步我们应该这样比较:
然而,问题在于,模式串中前缀“ab”与后缀“ab”是匹配的,后缀里的“b”与文本串中的当前字符失配,那么前缀中的“b”也一定会失配。这又是无用功。所以我们应该思考如何避免这种无用功。显然,模式串移动到的位置与next值有关,对于模式串“abab”,我们求next[3]时,不应该按照之前的算法得出结果为1了。所以我们应该思考如何修改next值呢,如何优化get_Next()函数?
当我们判断出ptr[0] == ptr[2]时,需要进一步判断ptr[++0]与ptr[++2],即ptr[1]与ptr[3]是否相等。如果不相等,我们仍可以直接令{ i++; j++; next[i] = j; }。但如果相等,我们就需要进一步递归出结果:{ i++; j++; next[ i ] = next[ j ]; },这说明应该看第一个“b”的前面那一部分了(而不再是直接看第二个“b”的前面那一部分,即next[3],结果为1),即next[1],结果为0。
因此,代码优化如下:
void get_Next(char* ptr, int next[]) { int pLen = strlen(ptr); next[0] = -1; int i = 0, j = -1; //i用来从0开始遍历模式串,从而为模式串的每一个字符找出正确的next值 //j用来设置next[i]值;j的初值设为-1是因为执行if(j == -1 || s[i] == s[j])时,将next[1]置为0 //i值一直处于前进状态;j会回退——当不符合条件时,j回退到next[j] while(i < pLen - 1) { if(j == -1 || ptr[i] == ptr[j]) //注意:两条件不能交换位置,因为j为-1时执行ptr[j]是越界的,但如果先判断j == -1,则符合的话就不会执行后面的条件了 //ptr[i]表示后缀;ptr[j]表示前缀 { i++; j++; if(ptr[i] == ptr[j]) next[i] = next[j]; else next[i] = j; } else { j = next[j]; } } }这样,对一个模式串求next[ ]数组,优化前与优化后程序运行结果对比:
对next的值进行如下总结:
- next[0] = -1:任何串的第一个字符的模式值规定为-1。
- next[1] = 0: 任何串的第二个字符的模式值规定为0。
- next[i] = -1: ptr[i-1] == ptr[j-1] 且 ptr[i] == ptr[j] 且 next[j] = -1
- next[i] = 0: ptr[i-1] == ptr[j-1] 且 ptr[i] != ptr[j] 且 next[j-1] = -1
- next[i] = j: i的前面n个字符与开头的n个字符相等,且ptr[i] != ptr[j]。




如果还有精力,可以试着理解下面把next[0]设为0的情况下的KMP算法:
#include<stdio.h>
#include<string.h>
void getNext(const char P[],int next[])
{
int q,k = 0;
int m = strlen(P);
next[0] = 0;
for (q = 1; q < m; q++)
{
while(k > 0 && P[q] != P[k])
k = next[k-1];
if (P[q] == P[k])
{
k++;
next[q] = k;
}
}
}
int kmp(const char T[],const char P[],int next[])
{
int n,m;
int i,q;
n = strlen(T);
m = strlen(P);
getNext(P,next);
for (i = 0,q = 0; i < n; ++i)
{
while(q > 0 && P[q] != T[i])
q = next[q-1];
if (P[q] == T[i])
{
q++;
}
if (q == m)
{
printf("??????λ????:%d\n",(i-m+1));
}
}
}
int main()
{
int i;
int next[20]={};
char T[] = "ababxbababcadfdsss";
char P[] = "ababa";
printf("%s\n",T);
printf("%s\n",P );
kmp(T,P,next);
for (i = 0; i < strlen(P); ++i)
{
printf("%d ",next[i]);
}
printf("\n");
return 0;
}
四、时间复杂度分析
在最开始时,我们提到了两者的时间复杂度。在已经明白两种算法的基础上,我们下面来分析一下两者的时间复杂度分别是多少。
暴力匹配时,我们从目标字符串str(假设长度为n)的第一个下标选取和ptr长度(长度为m)一样的子字符串进行比较,如果一样,就返回开始处的下标值,不一样,选取str下一个下标,同样选取长度为n的字符串进行比较,直到str的末尾(实际比较时,下标移动到n-m)。这样的时间复杂度是O(n*m)。
对于KMP算法,我们发现如果某个字符匹配成功,模式串首字符的位置保持不动,仅仅是i++、j++;如果匹配失配,i 不变(即 i 不回溯),模式串会跳过匹配过的next [j]个字符。整个算法最坏的情况是,当模式串首字符位于i - j的位置时才匹配成功,算法结束。所以,如果文本串的长度为n,模式串的长度为m,那么匹配过程的时间复杂度为O(n);算上计算next的O(m)时间,KMP的整体时间复杂度为O(m + n)。
参考“文献”:
KMP算法最浅显理解——一看就明白
从头到尾彻底理解KMP
