Random Ferns分类器原理及其应用
内容说明:主要介绍Fern分类器的原理以及几个应用,算是个人学习总结,若有错误之处,欢迎指出,同时也欢迎大家提供更多的Random Ferns的应用,不断学习,不断更新,不断完善。
参考资料:链接1: 随机蕨(Random Ferns)简介 【原理】
链接2: Random Ferns 【介绍它在目标跟踪的应用】
一、Random Ferns数学原理
Random Ferns涉及到的数学知识主要是概率论,用于分类。
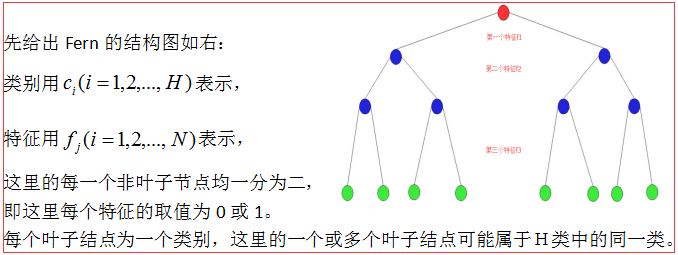



二、Random Ferns具体应用
2.1 Ferns 在目标跟踪中的应用
这里主要复制链接2中提到的Ferns在TLD中的应用,然后加上自己的理解,我没有看过TLD的详细文章,这里写出来主要是因为我在理解第二个应用时(ESR算法做人脸对齐)遇到了Ferns,这个链接让我对Ferns有了个比较好的理解,希望能更好地帮助大家一次性对Ferns的原理和应用有个深刻的理解。内容如下:
最近在做 Zdenek Kalal 的 TLD 算法,其成果发表在CVPR 2010 上,文章的名字做
P-N Learning: Bootstrapping BinaryClassifiers by Structural Constraints,是关于一个跟踪算法的,主要思想还是实时地对跟踪对象的模型进行更新。检测部分用到了一种作者称为 Fern 的结构,它是在 Random Forests 的基础上改进得到的,不妨称之为Random Fern。下面,根据我的理解和体会总结下 Random Fern 是怎么做的。
首先,不得不先说一下论文在进行检测时所使用的特征,是作者定义的一种称之为 2bitBP(2bit Binary Pattern)的特征。
2bitBP(2bit Binary Pattern)的特征
这种特征是种类似于 harr-like 的特征,这种特征包括了特征类型以及相应特征取值。
假定现在我们要判断一个Patch 块是不是我们要检测的目标。所谓特征类型,就是指在这个 Patch 在 (x,y)坐标,取的一个长 width,高 height 的框子,这个组合 (x, y, width, height) 就是相应的特征类型。
下面解释什么是特征的取值。在已经选定了特征类型的情况下,如果我们把框子左右分成相等的两部分,分别计算左右两部分的灰度和,那么就有两种情况:(1)左边灰度大,(2)右边灰度大,直观的看,就是左右两边哪边颜色更深。同样的,把框子分成上下相等的两部分,也会有两种情况,直观地看,就是上下两边哪边颜色更深。于是在分了上下左右后,总共会有4种情况,可以用 2bit 来描述这4种情况,即可得到相应的特征取值。这个过程可以参见图1。
实际上每种类型的特征都从某个角度来看待我们要跟踪的对象。比如图1中的红框,这个框子中,车灯的地方灰度应该要深一些,那么红框这个类型的特征,实际上就意味着,它认为,如果该 Patch 是一个车子,在相应的地方,相应的长和高,这个地方颜色也应该深一些。

图1 2bitBP特征说明
接下来,开始介绍 Random Ferns。
Random Ferns
前面已经提及,每种类型的特征都代表了一种看待跟踪对象的观点,那么是否可以用若干种类型的特征来进行一个组合,使之更好地描述跟踪的对象呢?答案是肯定的,还是举图1的例子,左边有一个车灯,右边也有一个车灯,如果我们把这两个框子都取到了,可以预见检测的效果会比只有一个框子来得好。Random Ferns 的思想就是用多个特征组合来表达对象。
下面,我们先讲一个 Fern 是怎么生成和决策的,再讲多个 Fern 的情况下,如何进行统一决策。
不妨假设我们选定了 nFeat 种类型的特征来表达对象。每个棵 Fern 实际上是一棵4叉树,如图2所示,选了多少种类型的特征,这棵4叉树就有多少层。对于一个 Patch,每一层就用相应的类型的特征去判断,计算出相应类型特征的特征取值,由于采用的是2bitBP特征,会有4种可能取值,在下一层又进行相同的操作,这样每个 Patch 最终会走到最末层的一个叶子节点上。
对于训练过程,要记录落到每个叶子结点上的正样本个数(用nP记),同时也要记录落到每个叶子结点上的负样本的个数(用nN记)。则可算出正样本落到每个叶子结点上的后验概率nP/(nP+nN)。
对于检测过程,要检测的 Patch 最终会落到某个叶子结点上,由于训练过程已经记录了 正样本落到每个叶子结点上的后验概率,最终可输出该 Patch 为正样本的概率。

图2 Fern结构理解
前面介绍了一个 Fern 的生成,以及用 Fern 检测一个 Patch,并给出它为正样本的概率。这样多个 Fern进行判断时,就会给出多个后验概率。这就好比我们让多个人来决策,看这个东西是不是正样本,每个人对应于一个 Fern。最终我们计算这一系列的 Fern 输出的后验的均值,看是否大于阈值,从而最终确定它是否是正样本。
【补充说明】这里的每一个2bitBP特征可以理解为原理中的分组,由两个1bit的特征构成一个小组,即S=2,它们之间是相关的,因为每一个Patch中上下和左右分别都有相同的像素点。而这里的每一个Patch之间是相互独立的,因为选择的是车子上不同地方的像素块。和原理中的示例介绍的不一样的地方是,这里不是简单的单个像素强度的差值,而是两块像素和的差值。
2.2 Ferns在人脸对齐中的应用
在CVPR2012上的一篇关于人脸对齐的文章Face Alignment by Explicit Shape Regression中使用到了Fern分类的方法,第二层的每一个回归量r都用一个Fern来表示,文中每个Fern选用的特征个数F=5,不同于上面原理中介绍的Fern的分类,它们2^N(2的N次方)个叶子结点中的类别属于H个类别中的一种,可以有很多个叶子结点属于同一个类别,而在ESR中的Fern,它们的每一个结点都表示一个相互独立的类别,所以对于特征F=5的Fern,它的类别数有2^5=32种。
ESR中Fern的个数:
文中利用两层回归级联,按照实验较好的数据,第一层T=10,第二层K=500,这样我们就有T*K=5000个Fern。
ESR中Fern的输入特征:
对于每一个Fern,它们的输入是5个01二元数值,每个数值表示的也是像素灰度差,原理中没有介绍如何寻找这样的一对对像素点,那么这里简单介绍一下ESR中找到这样的点的方法,更加详细的描述参见人脸对齐系列博客(三)。随机选取P个像素,计算两两之间的灰度差,得到P^2个(包括自身灰度差为0,以及像素A和像素B的A-B和B-A,本质上只有P(P-1)/2个)灰度差,也就是P^2个特征点,然后通过相关性选择其中的F个特征作为输入。
ESR中Fern的输出含义:
对于每一组F个特征的输出,即每一个叶子结点对应的是形状偏差,也就是落入该类别的所有样本偏离该类别中所有样本的平均形状的平均值,人脸对齐系列博客(三)中将会有更加详细的介绍。
【说明:若有其它应用,后期会补上。】