股价趋势预测模型构建
(一)建立模型
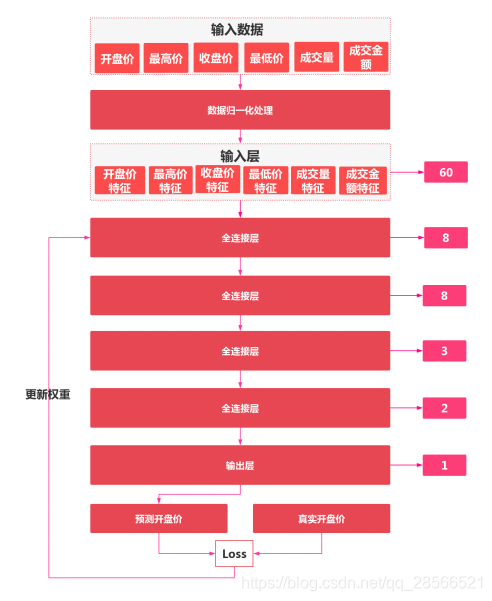
读取10天的数据进行归一化处理变成[-1,1]区间的特征数据,中间经过4个全连接的神经网络层得到一个预测的开盘价输出,最后根据真实开盘价与预测开盘价的梯度更新权重。
(二)数据准备
Tushare是一个基于python的、免费的、开源的财经数据接口包。本文的金融数据来源将使用Tushare的API。所采用的训练集股票数据来自上证50指数,股票代码是从600000-603808中抽取了833只股票。时间区间为2016年9月19日至2019年3月18日这三年的日K线数据。所采用的测试集股票数据来自沪深300指数的两只股票:000538.(云南白药)、000858(五粮液)近三年的数据作为测试集对模型进行验证。数据的维度包括:开盘价、最高价、收盘价、最低价、成交量、成交金额,将这六个交易信息作为特征提取。
数据预处理采用最大最小归一化的方法,将所有数据全部映射到[-1,1]的区间。这样就可以避免不同的股票因为价格相差大而导致预测趋势产生的巨大波动。
(三)训练过程
模型说明
1.输入层一共有6个维度的数据,每次训练会输入10天的数据,一共有60个神经元
2.隐藏层一共设置了4层,每一层的神经元个数分别设置为8、 8、 3、 2。激活函数统一使用relu
3.输出层的神经元设置为1个,且不使用激活函数。输出数据为-1,至1之间的浮点数值,表示未来一天的价格。
4.初始化权重w0和b0,w0是呈正态分布的随机值,b0则统一设初始值为0
开始训练
1.在数据输入之前先对数据进行归一化的处理,在下面的归一化公式中:X_Scaled表示归一化之后的数据,X_input表示输入数据集中的每一个数据,X_min表示输入数据集中的最小值,X_max表示输入数据集中的最大值。
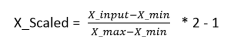
2.对于输入数据来说,做的工作主要就是加权求和,输入数据经过处理之后跟原来的数据维度保持一致,但是数值会随着权重和偏置值的变化而变化。
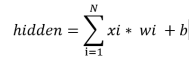
3.在上一步的数据计算完成之后得到结果hidden,再使用激活函数对数据进行处理,这里选用relu作为激活函数,将hidden中为负数的值变成0,这样可以形成神经网络的稀疏性,减少参数间的依赖关系。最后将结果作为下一层的输出
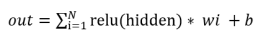
其中relu函数的数学公式为:
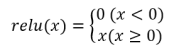
4.对于输出层来说就不需要加上激活函数了,加权求和就可以得到结果即表示未来一天的开盘价。
pred = out * wi + b
5.这时候就得到了预测的开盘价pred,与真实的开盘价Y,进行平方差均值计算就可以得到loss
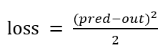
6.得到loss之后就可以通过TensorFlow中的优化器来更新权重,其内部实现细节中包含的梯度下降法和反向传播算法已经在上文给出这里不再赘述。
实验结果数据分析
模型刚开始训练时loss值在0-0.35之间波动(如图5.1、5.2所示),而且很不稳定预测的价格趋势与真实的趋势相差非常大,当训练数据达到400之后模型才开始慢慢收敛至0.15左右。
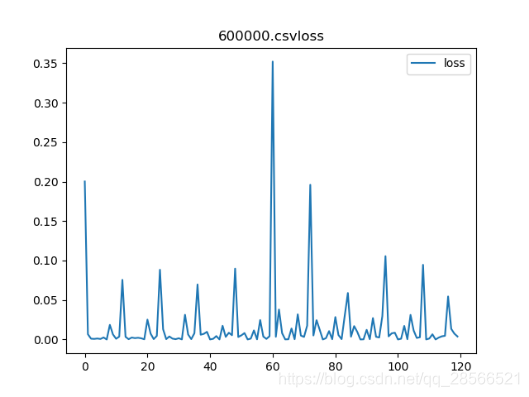
上图显示的是股票代码为600000的loss的变化过程,横轴表示训练批次,纵轴表示loss值。

在上图中显示的是股票代码为600000的真实开盘价走势和神经网络拟合的开盘价走势,横轴表示归一化之后的开盘价;纵轴表示训练的数据,每一批数据共有6*10个,对应输入层的神经元个数。(下同)
当模型训练到八万次时,loss值的波动开始趋于稳定(如图5.3所示)。正常情况下可以保持在0-0.1之间。也就是在大多数情况下预测的趋势的准确的,但是一些重大的利好或利空消息也会让模型的预测出现偏差。
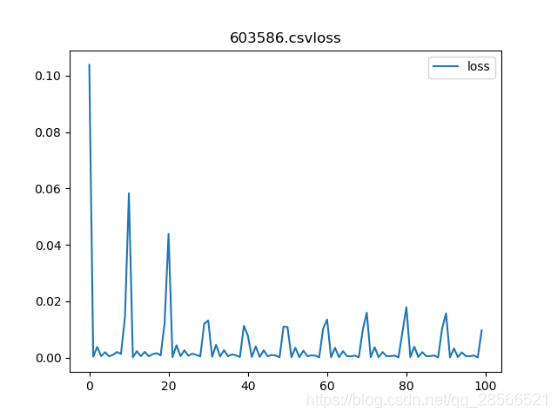
loss趋势(2)
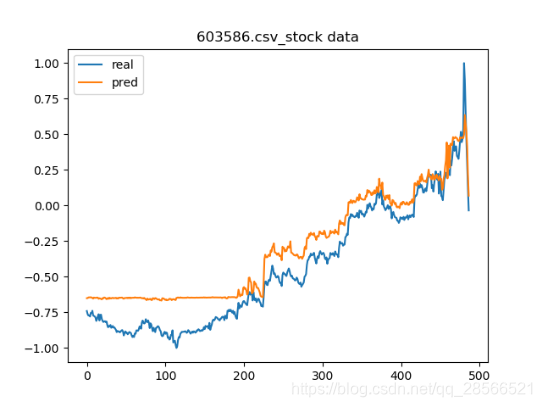
通过上图可以很直观得看到预测趋势与真实趋势已经非常接近了,虽然也有一些误差,但是不像刚开始训练时的误差那么明显。
以上的图片都是在训练集的预测效果,现使用股票000538.(云南白药)、000858(五粮液)近三年的数据作为测试集进行预测。这两只股票是从来没有在训练集中出现过的,可以保证测试集数据跟训练集数据完全独立。

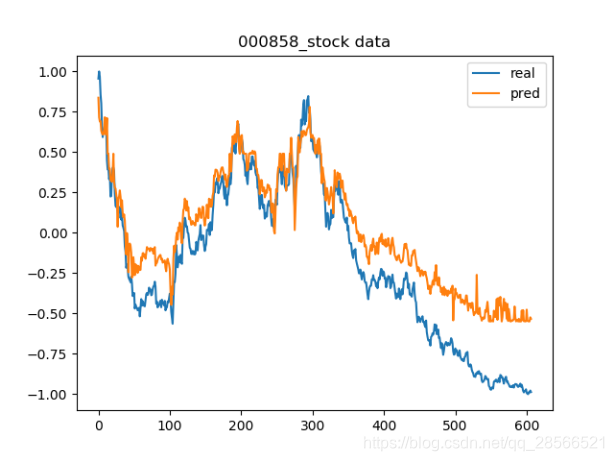
通过上述实验可知,模型误差最终为0.1以内,且没有出现过拟合的现象。在测试集上的表现也比较良好,说明该模型是有一定投资参考价值的。
代码
下载股票数据代码
import tushare as ts
import os
stocklist = [str(i) for i in range(600599, 602000)]
if not os.path.exists('stocks1'):
os.mkdir("stocks1")
for stock in stocklist:
df = ts.get_hist_data(stock)
if df is not None:
print(df.__len__())
# if df.__len__() == 607:
df.to_csv('./stocks1/'+stock + '.csv', columns=['open', 'high', 'low', 'close', 'volume'])
核心代码
import tensorflow as tf
import numpy as np
import pandas as pd
import copy
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt
import os
def read_process_data(csv='600000.csv', isca=True, look_back=10):
data = pd.read_csv('stocks/'+csv)
data = data.drop(['date'], 1)
data.astype('float32')
data = data.values
if isca:
scaler = MinMaxScaler(feature_range=(-1, 1))
scaler.fit(data)
data = scaler.transform(data)
dataX, dataY = [], []
for i in range(len(data) - look_back):
a = data[i:(i + look_back), 1:]
dataX.append(a)
dataY.append(data[i:(i + look_back), 0][-1])
# dataX.shape = (n,look_back,4)
dataX = np.array(dataX)
dataY = np.array(dataY)
dataY.reshape(-1, 1)
return data
def hidden_layer(layer_input, output_depth, scope):
input_depth = layer_input.shape[-1]
with tf.name_scope('hidden'+str(scope)):
w = tf.get_variable(initializer=tf.random_uniform_initializer(minval=-0.1, maxval=0.1),
shape=(input_depth, output_depth),
dtype=tf.float32,
name='weights'+str(scope))
b = tf.get_variable(initializer=tf.zeros_initializer(),
shape=(output_depth),
dtype=tf.float32,
name='bias'+str(scope))
net = tf.matmul(layer_input, w) + b
tf.summary.histogram('w'+str(scope), w)
tf.summary.histogram('b'+str(scope), b)
return net
def dnn(x, output_depths, fncs):
net = x
i = 1
for output_depth, fnc in zip(output_depths, fncs):
net = hidden_layer(net, output_depth, scope=i)
net = fnc(net)
i += 1
net = hidden_layer(net, 1, scope=0)
return net
def train_moel(data, neurons, fncs, batch_size=16, epochs=1):
with tf.name_scope('input_data'):
X = tf.placeholder(dtype=tf.float32, shape=[None, (data.shape[-1]-1)], name='X')
Y = tf.placeholder(dtype=tf.float32, shape=[1, 1], name='Y')
out = dnn(X, neurons, fncs)
out = tf.identity(out, name='out')
with tf.name_scope('loss'):
loss = tf.reduce_mean(tf.squared_difference(out, Y), name='loss')
tf.summary.scalar('loss', loss)
with tf.name_scope('opt'):
opt = tf.train.AdamOptimizer(name='opt').minimize(loss)
sess = tf.Session()
merged = tf.summary.merge_all()
writer = tf.summary.FileWriter("logs/", sess.graph)
sess.run(tf.global_variables_initializer())
look_back = 10
losses =[]
saver = tf.train.Saver()
sess.graph.finalize()
for e in range(epochs):
for i in range(0, len(data)-look_back):
sess.run(opt,
feed_dict={X: data[i:(i+look_back), 1:],
Y: np.array(data[i:(i+look_back), 0][-1])
.reshape(1, 1)})
rs = sess.run(merged,
feed_dict={X: data[i:(i+look_back), 1:],
Y: np.array(data[i:(i+look_back), 0][-1])
.reshape(1, 1)})
writer.add_summary(rs, i)
if np.mod(i, 50) == 0:
losses.append(sess.run(loss,
feed_dict={X: data[i:(i + look_back), 1:],
Y: np.array(data[i:(i + look_back), 0][-1])
.reshape(1, 1)}))
print('loss:'+str(losses[-1]))
y_num = sess.run(out, feed_dict={X: data[:, 1:]})
saver.save(sess, 'ckpt/stock.ckpt', global_step=epochs)
sess.close()
return y_num, losses
def restore_test_model(data):
graph = tf.Graph()
with graph.as_default():
model_file = tf.train.latest_checkpoint('ckpt/')
saver = tf.train.import_meta_graph(str(model_file) + '.meta')
with tf.Session() as sess:
sess.graph.finalize()
saver.restore(sess, model_file)
graph = tf.get_default_graph()
out = graph.get_tensor_by_name("out:0")
X = graph.get_tensor_by_name("input_data/X:0")
y_num = sess.run(out, feed_dict={X: data[:, 1:]})
return y_num
def restore_train_model(data, epochs=1):
graph = tf.Graph()
with graph.as_default():
model_file = tf.train.latest_checkpoint('ckpt/')
saver = tf.train.import_meta_graph(str(model_file) + '.meta')
with tf.Session() as sess:
sess.graph.finalize()
saver.restore(sess, model_file)
graph = tf.get_default_graph()
loss = graph.get_tensor_by_name("loss/loss:0")
X = graph.get_tensor_by_name("input_data/X:0")
Y = graph.get_tensor_by_name("input_data/Y:0")
out = graph.get_tensor_by_name("out:0")
opt = graph.get_operation_by_name('opt/opt')
look_back = 10
losses = []
for i in range(epochs):
for i in range(0, len(data) - look_back):
sess.run(opt,
feed_dict={X: data[i:(i + look_back), 1:],
Y: np.array(data[i:(i + look_back), 0][-1])
.reshape(1, 1)})
lossnum = sess.run(loss,
feed_dict={X: data[i:(i + look_back), 1:],
Y: np.array(data[i:(i + look_back), 0][-1])
.reshape(1, 1)})
if np.mod(i, 50) == 0:
losses.append(lossnum)
print(lossnum)
saver.save(sess, 'ckpt/stock.ckpt', global_step=epochs+1)
y_num = sess.run(out, feed_dict={X: data[:, 1:]})
return y_num, losses
def main():
data = read_process_data()
neurons = [1024, 512, 256, 128]
fncs = [tf.nn.relu, tf.nn.relu, tf.nn.relu, tf.nn.relu]
y_pred, losses = train_moel(data, neurons, fncs)
testN()
pass
def trainN():
stocklist = [i for i in os.listdir('stocks') if i.endswith('csv') and i.startswith('6')]
for i in stocklist:
test_data = read_process_data(csv=i)
y_pred, losses = restore_train_model(test_data)
plt.plot(test_data[0:, 0], label='real')
plt.plot(y_pred, label='pred')
plt.title(i+'_stock data')
plt.legend()
plt.savefig("pred-"+str(i)+".png")
plt.clf()
plt.plot(losses, label='loss')
plt.title(i + 'loss')
plt.legend()
plt.savefig("loss-" + str(i)+".png")
plt.clf()
def testN():
test_data = read_process_data('000538.csv')
y_test_pred = restore_test_model(test_data)
plt.plot(test_data[0:, 0], label='real')
plt.plot(y_test_pred, label='pred')
plt.title('000538_stock data')
plt.legend()
plt.savefig("test-000538.png")
plt.clf()
if __name__ == '__main__':
main()
