文章目录
1、数据类型
1.1、数值类型
数值类型分为以下几种:整数、浮点数、复数。
1.1.1、整型(整数类型)
Go语言提供了有符号和无符号的整数类型,其中包括 int8、int16、int32 和 int64 四种大小截然不同的有符号整数类型,分别对应 8、16、32、64 bit(二进制位)大小的有符号整数,与此对应的是 uint8、uint16、uint32 和 uint64 四种无符号整数类型。
用来表示 Unicode 字符的 rune 类型和 int32 类型是等价的,通常用于表示一个 Unicode 码点。这两个名称可以互换使用。同样,byte 和 uint8 也是等价类型,byte 类型一般用于强调数值是一个原始的数据而不是一个小的整数。最后,还有一种无符号的整数类型 uintptr,它没有指定具体的 bit 大小但是足以容纳指针。
尽管在某些特定的运行环境下 int、uint 和 uintptr 的大小可能相等,但是它们依然是不同的类型,比如 int 和 int32,虽然 int 类型的大小也可能是 32 bit,但是在需要把 int 类型当做 int32 类型使用的时候必须显示的对类型进行转换,反之亦然。
1.1.2、浮点型(小数类型)
Go语言提供了两种精度的浮点数 float32 和 float64。
一个 float32 类型的浮点数可以提供大约 6 个十进制数的精度,而 float64 则可以提供约 15 个十进制数的精度,通常应该优先使用 float64 类型,因为 float32 类型的累计计算误差很容易扩散,并且 float32 能精确表示的正整数并不是很大。例如:
var f float32 = 16777216 // 1 << 24
fmt.Println(f == f+1) // "true"!
浮点数在声明的时候可以只写整数部分或者小数部分,像下面这样:
const e = .71828 // 0.71828
const f = 1. // 1
很小或很大的数最好用科学计数法书写,通过 e 或 E 来指定指数部分:
const Avogadro = 6.02214129e23 // 阿伏伽德罗常数
const Planck = 6.62606957e-34 // 普朗克常数
用 Printf 函数打印浮点数时可以使用“%f”来控制保留几位小数,例如:
fmt.Printf("%f\n", math.Pi) //3.141593
fmt.Printf("%.2f\n", math.Pi) //3.14
1.1.3、复数
复数是由两个浮点数表示的,其中一个表示实部(real),一个表示虚部(imag)。Go语言中复数的类型有两种,分别是 complex128(64 位实数和虚数)和 complex64(32 位实数和虚数),其中 complex128 为复数的默认类型。
复数的值由三部分组成 RE + IMi,其中 RE 是实数部分,IM 是虚数部分,RE 和 IM 均为 float 类型,而最后的 i 是虚数单位。
声明复数的语法格式如下所示:
var name complex128 = complex(x, y)
其中 name 为复数的变量名,complex128 为复数的类型,“=”后面的 complex 为Go语言的内置函数用于为复数赋值,x、y 分别表示构成该复数的两个 float64 类型的数值,x 为实部,y 为虚部。
上面的声明语句也可以简写为下面的形式:
name := complex(x, y)
对于一个复数z := complex(x, y),可以通过Go语言的内置函数real(z)来获得该复数的实部,也就是 x;通过imag(z)获得该复数的虚部,也就是 y。例如:
var x complex128 = complex(1, 2) // 1+2i
var y complex128 = complex(3, 4) // 3+4i
fmt.Println(x*y) // "(-5+10i)"
fmt.Println(real(x*y)) // "-5"
fmt.Println(imag(x*y)) // "10"
复数也可以用==和!=进行相等比较,只有两个复数的实部和虚部都相等的时候它们才是相等的。
Go语言内置的 math/cmplx 包中提供了很多操作复数的公共方法,实际操作中建议大家使用复数默认的 complex128 类型,因为这些内置的包中都使用 complex128 类型作为参数。
1.2、bool类型(布尔类型)
一个布尔类型的值只有两种:true 或 false。if 和 for 语句的条件部分都是布尔类型的值,并且==和<等比较操作也会产生布尔型的值。
一元操作符!对应逻辑非操作,因此!true的值为 false,更复杂一些的写法是(!true == false) == true,实际开发中我们应尽量采用比较简洁的布尔表达式,就像用 x 来表示x==true。
Go语言对于值之间的比较有非常严格的限制,只有两个相同类型的值才可以进行比较,如果值的类型是接口(interface),那么它们也必须都实现了相同的接口。如果其中一个值是常量,那么另外一个值可以不是常量,但是类型必须和该常量类型相同。如果以上条件都不满足,则必须将其中一个值的类型转换为和另外一个值的类型相同之后才可以进行比较。
布尔值可以和 &&(AND)和 ||(OR)操作符结合,并且有短路行为,如果运算符左边的值已经可以确定整个布尔表达式的值,那么运算符右边的值将不再被求值,因此下面的表达式总是安全的:
s != "" && s[0] == 'x' // 其中 s[0] 操作如果应用于空字符串将会导致 panic 异常。
1.3、字符串类型
字符串是一种值类型,且值不可变,即创建某个文本后将无法再次修改这个文本的内容,更深入地讲,字符串是字节的定长数组。
1.3.1、定义字符串
可以使用双引号""来定义字符串,字符串中可以使用转义字符来实现换行、缩进等效果,常用的转义字符包括:\n:换行符、\r:回车符、\t:tab 键、\u 或 \U:Unicode 字符、\:反斜杠自身。
例如:
var str = "C语言中文网\nGo语言教程"
字符串的内容(纯字节)可以通过标准索引法来获取,在方括号[]内写入索引,索引从 0 开始计数:
- 字符串 str 的第 1 个字节:str[0]
- 第 i 个字节:str[i - 1]
- 最后 1 个字节:str[len(str)-1]
需要注意的是,这种转换方案只对纯 ASCII 码的字符串有效。
注意:获取字符串中某个字节的地址属于非法行为,例如 &str[i]。
1.3.2、字符串拼接符“+”
两个字符串 s1 和 s2 可以通过 s := s1 + s2 拼接在一起。将 s2 追加到 s1 尾部并生成一个新的字符串 s。
可以通过下面的方式来对代码中多行的字符串进行拼接:
str := "Beginning of the string " + "second part of the string"
提示:因为编译器会在行尾自动补全分号,所以拼接字符串用的加号“+”必须放在第一行末尾。
也可以使用“+=”来对字符串进行拼接:
s := "hel" + "lo,"
s += "world!"
fmt.Println(s) //输出 “hello, world!”
1.3.3、字符串实现基于 UTF-8 编码
Go语言中字符串的内部实现使用 UTF-8 编码,通过 rune 类型,可以方便地对每个 UTF-8 字符进行访问。当然,Go语言也支持按照传统的 ASCII 码方式逐字符进行访问。
1.3.4、定义多行字符串
在Go语言中,使用双引号书写字符串的方式是字符串常见表达方式之一,被称为字符串字面量(string literal),这种双引号字面量不能跨行,如果想要在源码中嵌入一个多行字符串时,就必须使用`反引号,代码如下:
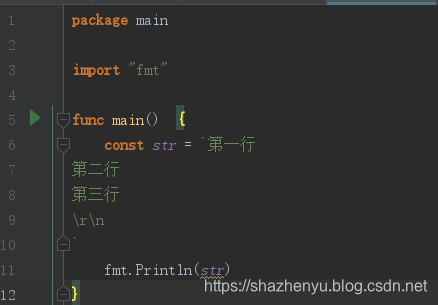
代码运行结果:
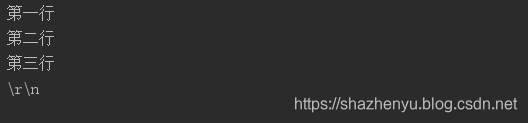
在 `间的所有代码均不会被编译器识别,而只是作为字符串的一部分。
1.4、字符类型(byte和rune)
1.4.1、概念
字符串中的每一个元素叫做“字符”,在遍历或者单个获取字符串元素时可以获得字符。
字符有以下两种:
- 一种是 uint8 类型,或者叫 byte 型,代表了 ASCII 码的一个字符。
- 另一种是 rune 类型,代表一个 UTF-8 字符,当需要处理中文、日文或者其他复合字符时,则需要用到 rune 类型。rune 类型等价于 int32 类型。
下面的写法是等效的:
var ch byte = 65 或 var ch byte = '\x41' // \x 总是紧跟着长度为 2 的 16 进制数
另外一种可能的写法是 \后面紧跟着长度为 3 的八进制数,例如 \377。
Go语言同样支持 Unicode(UTF-8),因此字符同样称为 Unicode 代码点或者 runes,并在内存中使用 int 来表示。在文档中,一般使用格式 U+hhhh 来表示,其中 h 表示一个 16 进制数。
在书写 Unicode 字符时,需要在 16 进制数之前加上前缀\u或者\U。因为 Unicode 至少占用 2 个字节,所以我们使用 int16 或者 int 类型来表示。如果需要使用到 4 字节,则使用\u前缀,如果需要使用到 8 个字节,则使用\U前缀。
var ch int = '\u0041'
var ch2 int = '\u03B2'
var ch3 int = '\U00101234'
fmt.Printf("%d - %d - %d\n", ch, ch2, ch3) // integer: 65 - 946 - 1053236
fmt.Printf("%c - %c - %c\n", ch, ch2, ch3) // character: A - β - r
fmt.Printf("%X - %X - %X\n", ch, ch2, ch3) // UTF-8 bytes: 41 - 3B2 - 101234
fmt.Printf("%U - %U - %U", ch, ch2, ch3) // UTF-8 code point: U+0041 - U+03B2 - U+101234
1.4.2、UTF-8 和 Unicode 的区别
Unicode 与 ASCII 类似,都是一种字符集。
字符集为每个字符分配一个唯一的 ID,我们使用到的所有字符在 Unicode 字符集中都有一个唯一的 ID,例如上面例子中的 a 在 Unicode 与 ASCII 中的编码都是 97。汉字“你”在 Unicode 中的编码为 20320,在不同国家的字符集中,字符所对应的 ID 也会不同。而无论任何情况下,Unicode 中的字符的 ID 都是不会变化的。
UTF-8 是编码规则,将 Unicode 中字符的 ID 以某种方式进行编码,UTF-8 的是一种变长编码规则,从 1 到 4 个字节不等。编码规则如下:
- 0xxxxxx 表示文字符号 0~127,兼容 ASCII 字符集。
- 从 128 到 0x10ffff 表示其他字符。
根据这个规则,拉丁文语系的字符编码一般情况下每个字符占用一个字节,而中文每个字符占用 3 个字节。
广义的 Unicode 指的是一个标准,它定义了字符集及编码规则,即 Unicode 字符集和 UTF-8、UTF-16 编码等。
2、类型转换
2.1、类型转换的概念
类型 B 的值 = 类型 B(类型 A 的值)
在必要以及可行的情况下,一个类型的值可以被转换成另一种类型的值。由于Go语言不存在隐式类型转换,因此所有的类型转换都必须显式的声明:
a := 5.0
b := int(a)
浮点数在转换为整型时,会将小数部分去掉,只保留整数部分。
2.2、字符串和数值类型的相互转换
开发时往往需要对一些常用的数据类型进行转换,如 string、int、int64、float 等数据类型之间的转换,Go语言中的 strconv 包为我们提供了字符串和基本数据类型之间的转换功能。strconv 包中常用的函数包括 Atoi()、Itia()、parse 系列函数、format 系列函数、append 系列函数等。
2.2.1、string 与 int 类型之间的转换
字符串和整型之间的转换是我们平时编程中使用的最多的,下面就来介绍一下具体的操作。
- Itoa():整型转字符串
Itoa() 函数用于将 int 类型数据转换为对应的字符串类型,函数签名如下func Itoa(i int) string,如:
func main() {
num := 100
str := strconv.Itoa(num)
fmt.Printf("type:%T value:%#v\n", str, str) // type:string value:"100"
}
- Atoi():字符串转整型
Atoi() 函数用于将字符串类型的整数转换为 int 类型,函数签名func Atoi(s string) (i int, err error)。通过函数签名可以看出 Atoi() 函数有两个返回值,i 为转换成功的整型,err 在转换成功是为空转换失败时为相应的错误信息,如:
func main() {
str1 := "110"
str2 := "s100"
num1, err := strconv.Atoi(str1)
if err != nil {
fmt.Printf("%v 转换失败!", str1)
} else {
fmt.Printf("type:%T value:%#v\n", num1, num1)
}
num2, err := strconv.Atoi(str2)
if err != nil {
fmt.Printf("%v 转换失败!", str2)
} else {
fmt.Printf("type:%T value:%#v\n", num2, num2)
}
}
结果:
type:int value:110
s100 转换失败!
2.2.2、Parse 系列函数
Parse 系列函数用于将字符串转换为指定类型的值,其中包括 ParseBool()、ParseFloat()、ParseInt()、ParseUint()。
2.2.2.1、ParseBool()
ParseBool() 函数用于将字符串转换为 bool 类型的值,它只能接受 1、0、t、f、T、F、true、false、True、False、TRUE、FALSE,其它的值均返回错误,函数签名:func ParseBool(str string) (value bool, err error)。
示例如下:
func main() {
str1 := "110"
boo1, err := strconv.ParseBool(str1)
if err != nil {
fmt.Printf("str1: %v\n", err)
} else {
fmt.Println(boo1)
}
str2 := "t"
boo2, err := strconv.ParseBool(str2)
if err != nil {
fmt.Printf("str2: %v\n", err)
} else {
fmt.Println(boo2)
}
}
结果如下:
str1: strconv.ParseBool: parsing "110": invalid syntax
true
2.2.2.2、ParseInt()
ParseInt() 函数用于返回字符串表示的整数值(可以包含正负号),函数签名:func ParseInt(s string, base int, bitSize int) (i int64, err error)。参数说明:
- base 指定进制,取值范围是 2 到 36。如果 base 为 0,则会从字符串前置判断,“0x”是 16 进制,“0”是 8 进制,否则是 10 进制。
- bitSize 指定结果必须能无溢出赋值的整数类型,0、8、16、32、64 分别代表 int、int8、int16、int32、int64。
- 返回的 err 是 *NumErr 类型的,如果语法有误,err.Error = ErrSyntax,如果结果超出类型范围 err.Error = ErrRange。
示例代码如下:
func main() {
str := "-11"
num, err := strconv.ParseInt(str, 10, 0)
if err != nil {
fmt.Println(err)
} else {
fmt.Println(num)
}
}
运行结果如下:
-11
2.2.2.3、ParseUnit()
ParseUint() 函数的功能类似于 ParseInt() 函数,但 ParseUint() 函数不接受正负号,用于无符号整型,函数签名:func ParseUint(s string, base int, bitSize int) (n uint64, err error)。示例代码如下:
func main() {
str := "11"
num, err := strconv.ParseUint(str, 10, 0)
if err != nil {
fmt.Println(err)
} else {
fmt.Println(num)
}
}
运行结果如下:
11
2.2.2.4、ParseFloat()
ParseFloat() 函数用于将一个表示浮点数的字符串转换为 float 类型,函数签名: func ParseFloat(s string, bitSize int) (f float64, err error)。参数说明:
- 如果 s 合乎语法规则,函数会返回最为接近 s 表示值的一个浮点数(使用 IEEE754 规范舍入)。
- bitSize 指定了返回值的类型,32 表示 float32,64 表示 float64;
- 返回值 err 是 *NumErr 类型的,如果语法有误 err.Error=ErrSyntax,如果返回值超出表示范围,返回值 f 为 ±Inf,err.Error= ErrRange。
示例代码如下:
func main() {
str := "3.1415926"
num, err := strconv.ParseFloat(str, 64)
if err != nil {
fmt.Println(err)
} else {
fmt.Println(num)
}
}
运行结果如下:
3.1415926
Parse 系列函数都有两个返回值,第一个返回值是转换后的值,第二个返回值为转化失败的错误信息。
2.2.3、Format 系列函数
Format 系列函数实现了将给定类型数据格式化为字符串类型的功能,其中包括 FormatBool()、FormatInt()、FormatUint()、FormatFloat()。
2.2.3.1、FormatBool()
FormatBool() 函数可以一个 bool 类型的值转换为对应的字符串类型,函数签名:func FormatBool(b bool) string。示例代码如下:
func main() {
num := true
str := strconv.FormatBool(num)
fmt.Printf("type:%T,value:%v\n ", str, str)
}
运行结果如下:
type:string,value:true
2.2.3.2、FormatInt()
FormatInt() 函数用于将整型数据转换成指定进制并以字符串的形式返回,函数签名: func FormatInt(i int64, base int) string。其中,参数 i 必须是 int64 类型,参数 base 必须在 2 到 36 之间,返回结果中会使用小写字母“a”到“z”表示大于 10 的数字。示例代码如下:
func main() {
var num int64 = 100
str := strconv.FormatInt(num, 16)
fmt.Printf("type:%T,value:%v\n ", str, str)
}
运行结果如下:
type:string,value:64
2.2.3.3、FormatUint()
FormatUint() 函数与 FormatInt() 函数的功能类似,但是参数 i 必须是无符号的 uint64 类型,函数签名: func FormatUint(i uint64, base int) string。示例代码如下:
func main() {
var num uint64 = 110
str := strconv.FormatUint(num, 16)
fmt.Printf("type:%T,value:%v\n ", str, str)
}
运行结果如下:
type:string,value:6e
2.2.3.4、FormatFloat()
FormatFloat() 函数用于将浮点数转换为字符串类型,函数签名:func FormatFloat(f float64, fmt byte, prec, bitSize int) string。参数说明:
- bitSize 表示参数 f 的来源类型(32 表示 float32、64 表示 float64),会据此进行舍入。
- fmt 表示格式,可以设置为“f”表示 -ddd.dddd、“b”表示 -ddddp±ddd,指数为二进制、“e”表示 -d.dddde±dd 十进制指数、“E”表示 -d.ddddE±dd 十进制指数、“g”表示指数很大时用“e”格式,否则“f”格式、“G”表示指数很大时用“E”格式,否则“f”格式。
- prec 控制精度(排除指数部分):当参数 fmt 为“f”、“e”、“E”时,它表示小数点后的数字个数;当参数 fmt 为“g”、“G”时,它控制总的数字个数。如果 prec 为 -1,则代表使用最少数量的、但又必需的数字来表示 f。
示例代码如下:
func main() {
var num float64 = 3.1415926
str := strconv.FormatFloat(num, 'E', -1, 64)
fmt.Printf("type:%T,value:%v\n ", str, str)
}
运行结果如下:
type:string,value:3.1415926E+00
2.2.4、Append 系列函数
Append 系列函数用于将指定类型转换成字符串后追加到一个切片中,其中包含 AppendBool()、AppendFloat()、AppendInt()、AppendUint()。
Append 系列函数和 Format 系列函数的使用方法类似,只不过是将转换后的结果追加到一个切片中。
示例代码如下:
package main
import (
"fmt"
"strconv"
)
func main() {
// 声明一个slice
b10 := []byte("int (base 10):")
// 将转换为10进制的string,追加到slice中
b10 = strconv.AppendInt(b10, -42, 10)
fmt.Println(string(b10))
b16 := []byte("int (base 16):")
b16 = strconv.AppendInt(b16, -42, 16)
fmt.Println(string(b16))
}
运行结果如下:
int (base 10):-42
int (base 16):-2a
3、运算符的优先级
运算符是用来在程序运行时执行数学或逻辑运算的,在Go语言中,一个表达式可以包含多个运算符,当表达式中存在多个运算符时,就会遇到优先级的问题,此时应该先处理哪个运算符呢?这个就由Go语言运算符的优先级来决定的。
比如对于下面的表达式:
var a, b, c int = 16, 4, 2
d := a + b*c
对于表达式a + b * c,如果按照数学规则推导,应该先计算乘法,再计算加法;b * c的结果为 8,a + 8的结果为 24,所以 d 最终的值也是 24。实际上Go语言也是这样处理的,先计算乘法再计算加法,和数据中的规则一样,读者可以亲自验证一下。
先计算乘法后计算加法,说明乘法运算符的优先级比加法运算符的优先级高。所谓优先级,就是当多个运算符出现在同一个表达式中时,先执行哪个运算符。
Go语言有几十种运算符,被分成十几个级别,有的运算符优先级不同,有的运算符优先级相同,请看下表。
| 优先级 | 分类 | 运算符 | 结合性 |
|---|---|---|---|
| 1 | 逗号运算符 | , | 从左到右 |
| 2 | 赋值运算符 | =、+=、-=、*=、/=、 %=、 >=、 <<=、&=、^=、|= | 从右到左 |
| 3 | 逻辑或 | || | 从左到右 |
| 4 | 逻辑与 | && | 从左到右 |
| 5 | 按位或 | | | 从左到右 |
| 6 | 按位异或 | ^ | 从左到右 |
| 7 | 按位与 | & | 从左到右 |
| 8 | 相等/不等 | ==、!= | 从左到右 |
| 9 | 关系运算符 | <、<=、>、>= | 从左到右 |
| 1 | 位移运算符 | <<、>> | 从左到右 |
| 1 | 加法/减法 | +、- | 从左到右 |
| 1 | 乘法/除法/取余 | *(乘号)、/、% | 从左到右 |
| 1 | 单目运算符 | !、*(指针)、& 、++、–、+(正号)、-(负号) | 从右到左 |
| 1 | 后缀运算符 | ( )、[ ]、-> | 从左到右 |
注意:优先级值越大,表示优先级越高。
一下子记住所有运算符的优先级并不容易,还好Go语言中大部分运算符的优先级和数学中是一样的,大家在以后的编程过程中也会逐渐熟悉起来。如果实在搞不清,可以加括号。
