在这里,我梳理了我在秒杀系统的摸索过程中所遇到的所有技术细节,涉及的东西太多,有的部分细节另外写成了博客。此外,我重写了项目README,讲解开发代码细节:README
系统结构
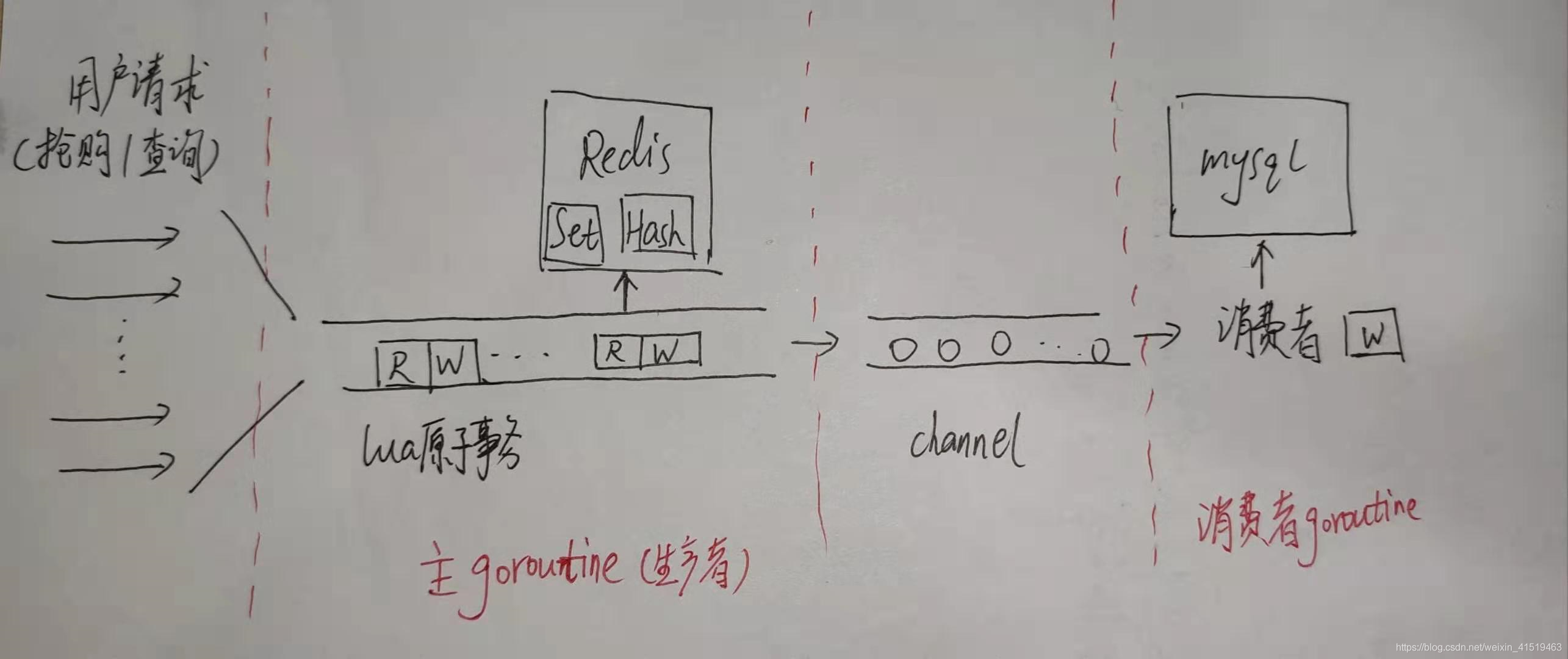
这里画的主要是两个高并发事务(用户抢优惠券、查询优惠券)的处理过程,因为其他三个事务(注册、登录、商家添加优惠券)都不是高并发事务,不需要用到Redis,只需要直接与mysql数据库交互,比较简单。
当大量的用户请求在短时间内先后到达时,每个请求都使用一个lua脚本来进行处理,一个lua脚本中包含了读redis和写redis两个部分,由于lua脚本是一个原子事务,因此相当于不同请求的处理是串行执行的,这样就可以避免先读后写等临界区问题。
图中可见,主goroutine的身份是生产者,借助Redis的高速性能读写特性处理高并发请求,每处理完一个请求后,Redis中优惠券数减一,为了将这个变化持久化到数据库中,就需要新开一个goroutine,他的身份是消费者,通过channel进行二者的通信,从而既保持了Redis和mysql中数据一致,又不会影响到高并发处理的效率。
Golang、Gin、Gorm
本项目用Golang语言实现,用的Web框架是Gin,用的ORM框架是Gorm,我把相关知识点都看了一遍,并总结成笔记发布在博客上:
- Golang语言:
- Gin框架:
- Gorm:
注意到本项目中使用gorm框架来实现ORM(Object Relational Mapping)。ORM的笔记我写在ORM简介,总的来说,ORM的作用就是使用对象,封装了数据库操作,从而可以不碰 SQL 语言。开发者只使用面向对象编程,与数据对象直接交互,不用关心底层数据库。
RESTful
项目涉及到RESTful规范的问题,比如给出的接口要求:接口文档,就符合了RESTful规范。这个规范确实是很优秀,在此之前我写Web的时候,很多都是很随意的,导致很不规范不易读,RESTful具体可以参考你真的了解RESTful API吗?,比如以下这些问题就正中靶心:
url命名规范
API 命名应该采用约定俗成的方式,保持简洁明了。在RESTful架构中,每个url代表一种资源,所以url中不能有动词,只能有名词,并且名词中也应该使用复数。实现者应使用相应的Http动词GET、POST、PUT、PATCH、DELETE、HEAD来操作这些资源即可
不规范的的url,冗余没有意义,形式不固定,不同的开发者还需要了解文档才能调用。
http://example.com/api/getallUsers //GET 获取所有用户
http://example.com/api/getuser/1 //GET 获取标识为1用户信息
http://example.com/api/user/delete/1 //GET/POST 删除标识为1用户信息
http://example.com/api/updateUser/1 //POST 更新标识为1用户信息
http://example.com/api/User/add //POST添加新的用户
规范后的RESTful风格的url,形式固定,可读性强,根据users名词和http动词就可以操作这些资源。

http://example.com/api/users //GET 获取所有用户信息
http://example.com/api/users/1 //GET 获取标识为1用户信息
http://example.com/api/users/1 //DELETE 删除标识为1用户信息
http://example.com/api/users/1 //Patch 更新标识为1用户部分信息,包含在div中
http://example.com/api/users //POST 添加新的用户
统一返回数据格式
example
返回成功的响应json格式:
{
"code": 200,
"message": "success",
"data": {
"userName": "123456",
"age": 16,
"address": "beijing"
}
}
返回失败的响应json格式:
{
"code": 401,
"message": "error message",
"data": null
}
其他
比如还有http的状态码、资源的层级关系等等,可以参考RESTful 架构详解 RESTful API 最佳实践,内容非常多,网上也有很多资料,这里不细讲,只要知道RESTful是Web开发的一种风格、规范就可以了。
Authorization(JWT)
参考认证 (authentication) 和授权 (authorization) 的区别
- authentication 认证,用户名/用户ID和密码,以验证您的身份。
- authorization 授权,授权发生在系统成功验证您的身份后,最终会授予您访问资源的权限。简单来说,授权决定了您访问系统的能力以及达到的程度。验证成功后,系统验证您的身份后,即可授权您访问系统资源。
因为抢优惠券之前是需要进行确认用户授权的,主要是检查用户有没有登录、用户是不是顾客之类的,关于用户登录状态的保持,一般是cookie和session的组合实现的。具体的笔记我总结在cookie与session会话跟踪技术,go有相关的库可以实现session,算是比较方便。
但TA要求用 JWT 来做用户身份验证,保持登录状态。JWT 的笔记我总结在JSON Web令牌(JWT)。简单来说,jwt就是用户首次登录后,服务器给用户返回一个json格式的token,用户后面再访问服务器时就在请求的header中附上这个token,然后服务器检查这个token就能确认用户的身份,从而保持用户的登录状态。
在本项目中使用JWT的优点是减轻了服务器端的压力,不仅不需要存储session,还省去了查询redis或数据库获取用户信息的步骤,因为JWT中就可以附有用户信息。但是缺点是不安全,JST中明文存放认证信息(用户密码用MD5加密),容易受攻击。但由于本项目主要关注点是高并发,不需要太关注安全这方面。
Redis
普通的事务处理基本就是依托于几个框架进行CURD而已,本项目最重要的是高并发处理这一块,而本项目的高并发实现主要依赖于Redis,具体来说就是使用Redis加快数据访问的速度,从而响应更多的用户请求。
关于Redis的笔记我总结在Redis基础知识入门。
简单来说,Redis使用NoSQL 技术,它是基于内存的数据库,并且提供一定的持久化能力。
- Redis使用在非高并发的场合下,读操作先读Redis后读数据库,写操作到来时先写入数据库,再更新到Redis中。这样的话只是加快了读的速度,没有加快写的速度。
- Redis使用在高并发的场合下,读写操作都只在redis中执行,只有当高并发场合结束后才将redis上的数据持久化到数据库中。
在本项目中,用户注册、登录以及商家添加优惠券等请求都不需要用到高并发,而抢优惠券和查询优惠券这两个请求需要用到高并发。值得注意的是,我们这里面并不是等高并发场合结束后才持久化到数据库中,我们借用goroutine和channel异步处理持久化,就是说,redis的更新和mysql的更新是先后异步进行的,redis更新完后把消息推给channel,然后就马上去处理其他请求,而mysql则开始异步更新。
Redis支持五种数据类型:string(字符串),hash(哈希),list(列表),set(集合)及zset(sorted set:有序集合),相关命令参考Redis命令参考简体中文版。在这个项目里,我用到了redis的Set和Hash结构:
- String:一个 key 对应一个 value,string是Redis 最基本的数据类型。
- Hash:
参考Redis Hash
- Set:比如一个Set的实例:
A = {'a', 'b', 'c'},A是集合的key,‘a’, 'b’和‘c’是集合的member。参考Set
Lua+Redis
这个项目的高并发的核心是lua和redis。lua脚本把用户请求的处理过程都包装起来,作为一个原子操作。lua脚本是用C语言写的,体积小、运行速度快,作为一个原子事务来执行。
使用Lua脚本的好处
- 减少网络开销:可以将多个请求通过脚本的形式一次发送,减少网络时延和请求次数。比如说在抢购事务中要访问两次Redis,第一次读Redis看是否还有优惠券可以抢,第二次抢购成功写Redis使优惠券数量减一,原本是两个请求,使用lua后将他们整合起来一起发送,就变成只有一次请求了。
- 原子性的操作:Redis会将整个脚本作为一个整体执行,中间不会被其他命令插入。因此在编写脚本的过程中无需担心会出现竞态条件(两个线程竞争同一资源时,如果对资源的访问顺序敏感,就称存在竞态条件)。
- 代码复用:客户端发送的脚本会一直存在redis中,这样,其他客户端可以复用这一脚本来完成相同的逻辑。
- 体积小,加载快,运行快。
本项目使用Lua的原因
本项目中使用Lua脚本,最重要的原因是为了他的原子性。redis本身是单线程应用,就是说读或者写都是各自独立的,是串行的,每次只能执行一个操作,而除读写之外的其他操作是可以并行的。在这个项目里,用户抢优惠券的请求是先读取redis查看优惠券信息,然后再抢优惠券(就是写redis让优惠券数量减一)。就是先读后写。
正常情况下是没什么问题的,但是在高并发的访问情况下,就可能会出现临界区的问题(也叫竞态条件)。比如说,假设当前Redis中优惠券的数量为1,此时两个用户A和B几乎同时发来两个抢购请求,A先读Redis,得知还有一张优惠券,因此允许抢购,此时原本应该是A继续写Redis,抢走优惠券使优惠券数量变0的。但是意外出现了,此时B插入其中,B抢占了Redis的访问权限,B读Redis发现此时还有一张优惠券,于是他也被允许抢购。那么问题就出现了,无论后面是A还是B先拿回Redis的写权限,都会出现超卖的问题,因为优惠券实际只有一张,却有两个用户抢购成功了。
为了避免抢购事务中redis的读写分离导致超卖的问题,就需要用到lua脚本,把用户抢优惠券这个过程的读操作和写操作捆绑起来,作为一个整体的原子操作,就是说一个用户读redis后要马上写redis,都处理完了,才允许其他用户再来读。这样的话,就相当于是串行处理用户抢优惠券的请求了,所以说这里高并发的实现其实主要是用redis来加快速度,然后lua来保证不会出现临界区问题的错误。
Go的CSP并发模型
关于Go的CSP并发模型的详细笔记我总结在Go的CSP并发模型(goroutine + channel)。
在本项目中,用CSP并发模型的主要目的是协调抢购过程中的两个任务,一个是读写redis的任务,一个是更新mysql数据库的任务。在本项目中,我们并不是在抢购完毕后才更新数据库,而是在抢购的同时进行数据库的更新。但是如果串行执行这两个任务,则更新数据库这一步会极大的拖慢整个处理速度,使得redis失去意义。因此需要让两个任务并发执行,具体的说,就是在主goroutine中读写redis,这一步可以处理高并发的抢购请求;同时新开一个从goroutine更新mysql,这一步可以将redis的数据持久化到数据库中,保持数据一致性。
两个任务通过有缓存的channel进行通信,具体来说就是每当主goroutine中有一个用户抢购成功后,主goroutine将这个信息传到channel中,然后继续处理其他抢购请求(有缓存的channel中只要还有空间,就不需要阻塞)。从goroutine一直监听channel,当发现有信息到来时,就根据信息内容执行mysql数据库的更新,这个信息具体来说就是使优惠券的数量减一。
