一:简介
Hadoop的搭建有三种方式,本文章安装的是单机版
- 单机版,适合开发调试;
- 伪分布式版,适合模拟集群学习;
- 完全分布式,生产使用的模式。
二:安装步骤
1. 修改主机名
sudo scutil --set HostName localhost
2. ssh免密登录
具体配置方法:
(1)ssh-keygen -t rsa (一路回车直到完成)
(2)cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
(3)chmod og-wx ~/.ssh/authorized_keys
然后重启终端,在命令行下输入>ssh localhost 如果不需要输密码即可进入,证明设置成功。如果仍需要输入密码,那可能是文件权限的问题,尝试执行 >chmod 755 ~/.ssh
3. 安装hadoop
这里安装的是目前最新版本3.1.1
brew install hadoop
4. 修改配置文件 /usr/local/Cellar/hadoop/3.1.1/libexec/etc/hadoop/core-site.xml
在修改配置文件时注意不要有中文字符,如中文空格之类的
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/Cellar/hadoop/3.1.1/libexec/tmp</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:8020</value>
</property>
</configuration>
5. 修改配置文件 /usr/local/Cellar/hadoop/3.1.1/libexec/etc/hadoop/hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/Cellar/hadoop/3.1.1/libexec/tmp/dfs/name</value>
</property>
<property>
<name>dfs.namenode.data.dir</name>
<value>file:/usr/local/Cellar/hadoop/3.1.1/libexec/tmp/dfs/data</value>
</property>
</configuration>
6. 配置hadoop的环境变量
vi ~/.bash_profile
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_141.jdk/Contents/Home
export HADOOP_HOME=/usr/local/Cellar/hadoop/3.1.1/libexec
export HADOOP_ROOT_LOGGER=DEBUG,console
export PATH=$PATH:${HADOOP_HOME}/bin
source ~/.bash_profile
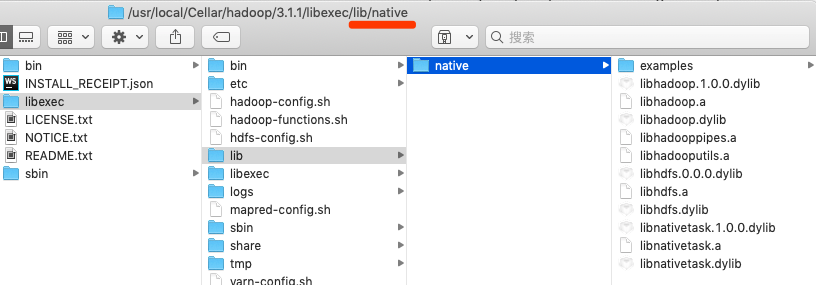
7. 拷贝lib/native库到/usr/local/Cellar/hadoop/3.1.1/libexec目录
注意:在mac环境中,通过brew install hadoop安装时在/usr/local/Cellar/hadoop/3.1.1/libexec目录下是没有/lib/native目录的,如果没有这目录在启动hadoop时会有警告的日志 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable。
解决办法有两种:
- 下载hadoop的源码自己通过maven编译出lib/native。自己编码麻烦,耗时长,不一定能编译成功。
- 在网上找一些别人编译好的,直接放到hadoop中即可。下载lib/native然后放到/usr/local/Cellar/hadoop/3.1.1/libexec目录下,然后再重启。
修改/usr/local/Cellar/hadoop/3.1.1/libexec/etc/hadoop/hadoop-env.sh
# 增加导出
export HADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib/native"
相关文章:mac下编译hadoop3.0.*版本的native lib
8. 格式化HDFS
注意:格式化一次就可以了
cd /usr/local/Cellar/hadoop/3.1.1/bin
./hdfs namenode -format
9. 启动Hadoop
cd /usr/local/Cellar/hadoop/3.1.1/sbin
# 使用start-dfs.sh或者start-all.sh来启动hadoop
# 停止 sbin/stop-dfs.sh
./start-dfs.sh
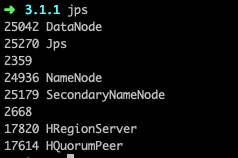
10. 查看Hadoop是否启动成功
# 查看启动的服务,如果有下面的服务则启动hadoop成功
jps
DataNode
NameNode
SecondaryNameNode
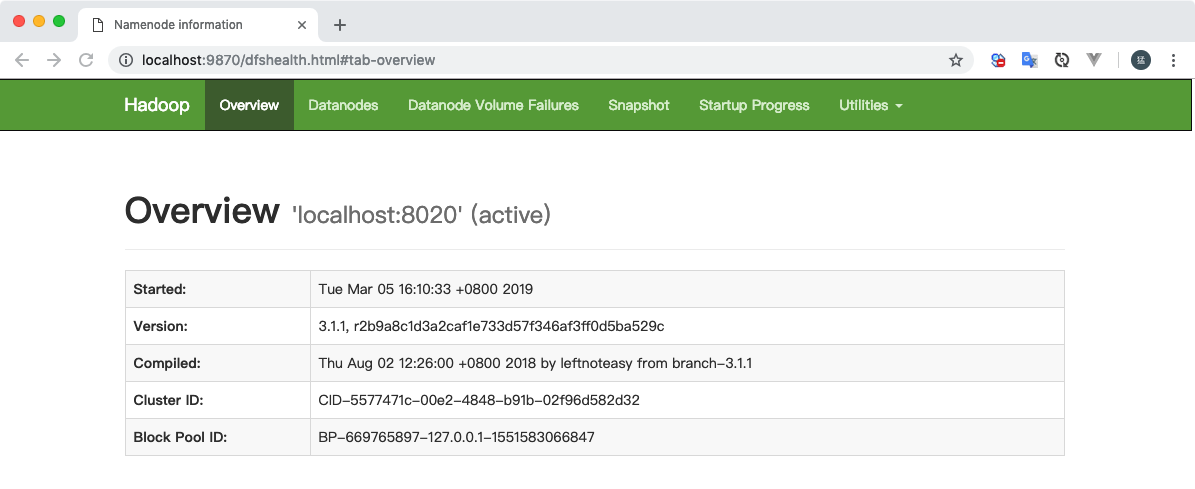
NameNode: http://localhost:9870/
三:启动yarn
1. 修改配置文件/usr/local/Cellar/hadoop/3.1.1/libexec/etc/hadoop/mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
2. 修改配置文件/usr/local/Cellar/hadoop/3.1.1/libexec/etc/hadoop/yarn-site.xml
<?xml version="1.0"?>
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
3. 启动yarn
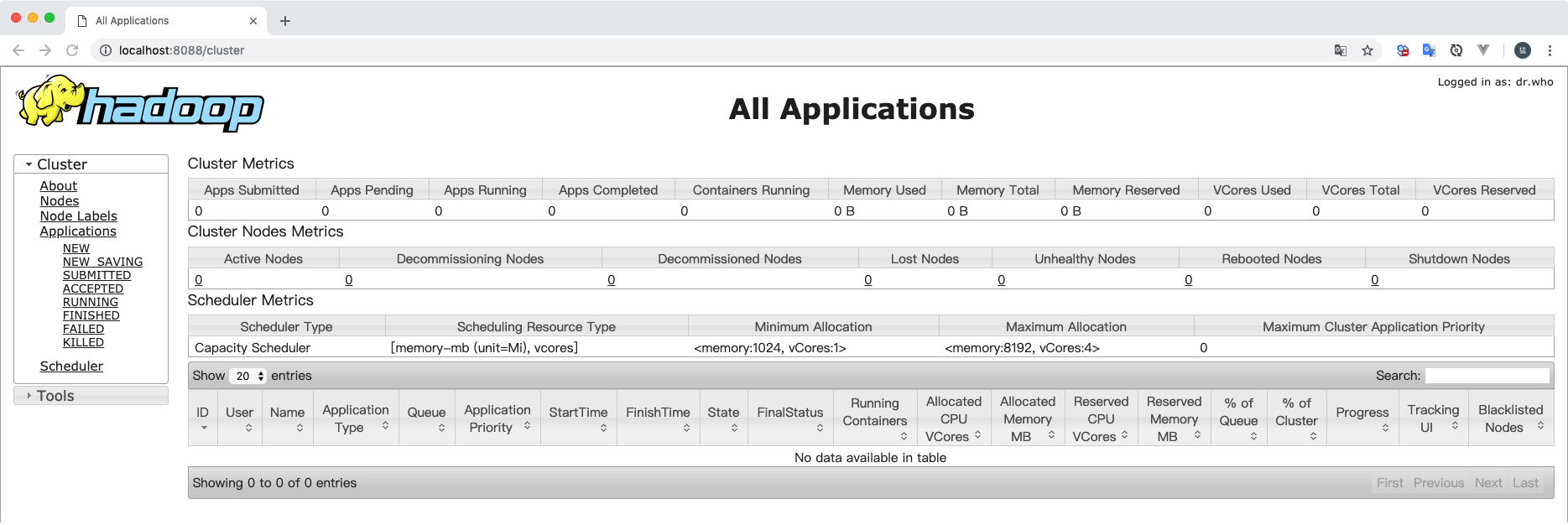
# 启动ResourceManager 和 NodeManager,启动成功后可以访问http://localhost:8088/cluster
# 停止 sbin/stop-yarn.sh
# 可以通过start-all.sh 来同时启动start-dfs.sh和start-yarn.sh
sbin/start-yarn.sh
四:运行Hadoop自带的MapReduce程序(wordcount)
wordcount: 用于统计单词的出现次数
# 在HDFS中创建层级目录
bin/hadoop fs -mkdir -p /wordcount/input
# 将hadoop中的LICENSE.txt文件上传到层级目录中
bin/hdfs dfs -put README.txt /wordcount/input
# 查看某个层级目录下面的内容
bin/hdfs dfs -ls /wordcount/input
# 运行hadoop自带的示例程序hadoop-mapreduce-examples-3.1.1.jar 该jar中有多个示例,wordcount是其中一个示例,用于统计每个单词出现的次数,
# /wordcount/input/LICENSE.txt 表示要统计的文件
# /wordcount/output 存放统计结果存放的目录,注意/wordcount/output目录不能存在
bin/hadoop jar /usr/local/Cellar/hadoop/3.1.1/libexec/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.1.jar wordcount /wordcount/input/README.txt /wordcount/output
# 查看目录内容,运行完wordcount程序,输出目录下会有一个文件叫part-r-00000,这个就是统计的结果
bin/hdfs dfs -ls /wordcount/output
# 查看统计结果
bin/hadoop fs -cat /wordcount/output/part-r-00000
# 将hdfs指定的目录内容拉到自己机器上
bin/hadoop fs -get /wordcount/output /Users/mengday/Desktop/wordcount

统计结果part-r-00000 部分截图
五:hadoop 安装启动问题
1. There are 0 datanode(s) running and no node(s) are excluded in this operation.
有的时候在启动hadoop的时候使用jps查看如果没有启动datanode
原因
当我们使用hadoop namenode -format格式化namenode时,会在namenode数据文件夹(这个文件夹为自己配置文件中dfs.name.dir的路径)中保存一个current/VERSION文件,记录clusterID,datanode中保存的current/VERSION文件中的clustreID的值是上一次格式化保存的clusterID,这样,datanode和namenode之间的ID不一致。
解决方法
- 第一种:如果dfs文件夹中没有重要的数据,那么删除dfs文件夹(dfs目录在core-site.xml中hadoop.tmp.dir配置),再重新格式化和启动hadoop即可。此种方式会将数据清空!
hadoop namenode -format
sbin/start-dfs.sh
- 第二种:如果dfs文件中有重要的数据,那么在dfs/name目录下找到一个current/VERSION文件,记录clusterID并复制。然后dfs/data目录下找到一个current/VERSION文件,将其中clustreID的值替换成刚刚复制的clusterID的值即可;
2. 执行命令如果报错:mkdir: Cannot create directory /user. Name node is in safe mode. 可通过执行下面命令执行。
# 离开安全模式
bin/hadoop dfsadmin -safemode leave
3. 运行wordcount示例程序一直循环打印日志
2019-07-10 15:25:53,289 DEBUG ipc.Client: IPC Client (389993238) connection to /0.0.0.0:8032 from mengday got value #80
2019-07-10 15:25:53,289 DEBUG ipc.ProtobufRpcEngine: Call: getApplicationReport took 1ms
2019-07-10 15:25:53,290 DEBUG security.UserGroupInformation: PrivilegedAction as:mengday (auth:SIMPLE) from:org.apache.hadoop.mapreduce.Job.updateStatus(Job.java:328)
这个问题在网上找了很多,最终按照如下配置的,重启了之后还是一直死循环,第二天来到公司start-all.sh之后竟然可以了
mapred-site.xml
<configuration>
<!--
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
-->
<property>
<name>mapreduce.job.tracker</name>
<value>hdfs://127.0.0.1:8001</value>
<final>true</final>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>200</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>200</value>
</property>
</configuration>
yarn-site.xml 中增加yarn.resourcemanager.address、yarn.app.mapreduce.am.resource.mb、yarn.scheduler.minimum-allocation-mb配置
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>127.0.0.1:8032</value>
</property>
<property>
<name>yarn.app.mapreduce.am.resource.mb</name>
<value>200</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>50</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
