一、基本概念
1.1.静态web资源(如html 页面):指web页面中供人们浏览的数据始终是不变。
静态web资源开发技术:Html
1.2.动态web资源:指web页面中供人们浏览的数据是由程序产生的,不同时间点访问web页面看到的内容各不相同。
动态web资源开发技术:JSP/Servlet、ASP、PHP等。在Java中,动态web资源开发技术统Javaweb。
1.3.web应用程序:指供浏览器访问的程序,也称为web应用。例如有a.html 、b.html……等多个web等多个web资源放在一个目录中,同时用于对外提供服务,此时这些资源就组成了一个web应用程序。
映射虚似目录:Web应用开发好后,若想供外界访问,需要把web应用所在目录交给web服务器管理,这个过程称之为虚似目录的映射
1.4.WEB服务器:是指驻留于因特网上,可以向发出请求的浏览器提供文档的程序。当Web浏览器(客户端)连到服务器上并请求文件时,服务器将处理该请求并将文件反馈到该浏览器上,附带的信息会告诉浏览器如何查看该文件(即文件类型)。最受欢迎的开源web服务器是Tomcat服务器,很大的原因是因为它是免费的,并且性能稳定。
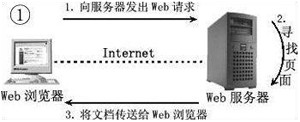
服务器是一种被动程序:只有当Internet上运行在其他计算机中的浏览器发出请求时,服务器才会响应。
二、开源web服务器Tomcat
2.1虚拟目录的映射方式
Web应用开发好后,若想供外界访问,需要把web应用所在目录交给web服务器管理,这个过程称之为虚似目录的映射
-
一、在server.xml中的host元素中进行配置context标签。
<Host name="localhost" appBase="webapps" unpackWARs="true" autoDeploy="true" xmlValidation="false" xmlNamespaceAware="false"> <Context path="/JavaWebApp" docBase="F:\JavaWebDemoProject" /> </Host>其中,Context表示上下文,代表的就是一个JavaWeb应用(可以理解为存放多个.html的文件夹),Context元素有两个属性:
Ⅰ.path:用来配置虚似目录,必须以"/"开头。
Ⅱ.docBase:配置此虚似目录对应着硬盘上的Web应用所在目录。
-
二、让Tomcat服务器自动映射。
tomcat服务器会自动管理webapps目录下的所有web应用,并把它映射成虚似目录。
2.2配置虚拟主机
打开conf文件夹下的server.xml这个配置文件,可看到Tomcat服务器自带的一个名称为localhost的虚拟主机
<Host name="localhost" appBase="webapps"
unpackWARs="true" autoDeploy="true">
<!-- SingleSignOn valve, share authentication between web applications
Documentation at: /docs/config/valve.html -->
<!--
<Valve className="org.apache.catalina.authenticator.SingleSignOn" />
-->
<!-- Access log processes all example.
Documentation at: /docs/config/valve.html
Note: The pattern used is equivalent to using pattern="common" -->
<Valve className="org.apache.catalina.valves.AccessLogValve" directory="logs"
prefix="localhost_access_log" suffix=".txt"
pattern="%h %l %u %t "%r" %s %b" />
</Host>
通常我们将开发好的JavaWeb应用放到webapps文件夹下,然后使用"http://localhost:8080/JavaWebAppName"的方式去访问了,其实访问的就是name是"localhost"的那台虚拟主机(Host),这台虚拟主机管理webapps文件夹下的所有web应用。
例如:http://localhost:8080/JavaWebDemoProject/1.jsp,这个URL地址访问的就是名称是localhost的那台虚拟主机下的JavaWebDemoProject这个应用里面的1.jsp这个web资源。
我们可以使用如下的方式配置一个虚拟主机,例如:
<Host name="www.suvue.cn" appBase="F:\JavaWebApps">
</Host>
配置的主机(网站)要想通过域名被外部访问,必须在DNS服务器或windows系统中注册访问网站时使用的域名。
打开"C:\Windows\System32\drivers\etc"目录下的hosts文件,将新网站的域名和IP地址绑定在一起,这样我们就可以在浏览器中使用www.suvue.cn这个域名去访问name是suvue那个虚拟主机里面管理的那些web应用了
127.0.0.1 www.suvue.cn
2.3浏览器与服务器交互的过程
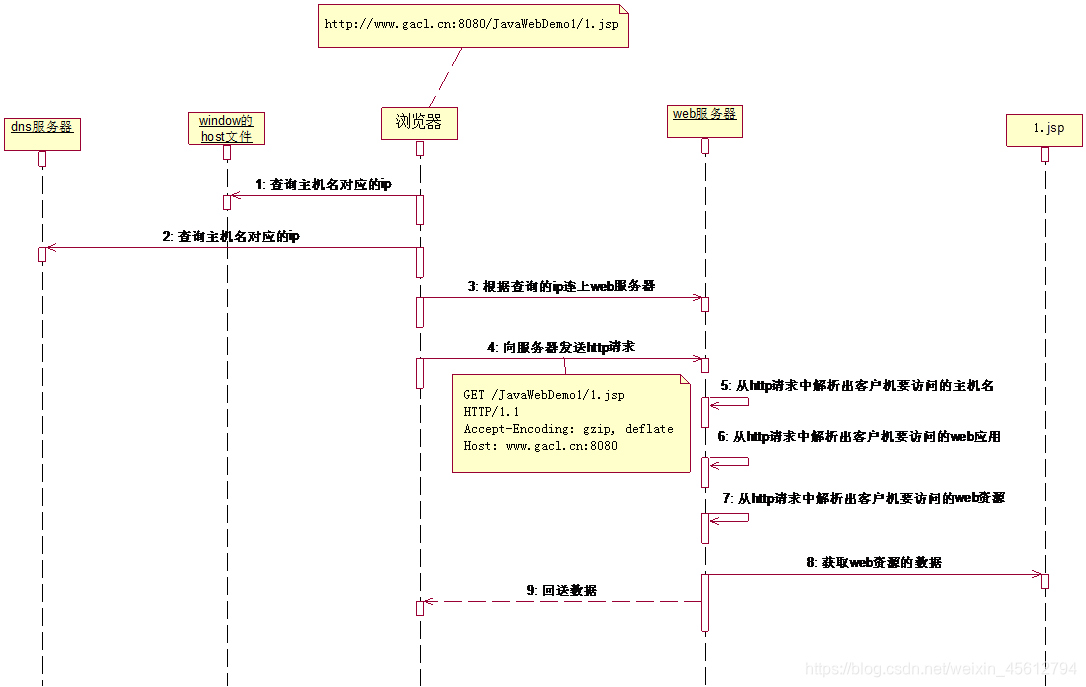
当我们在浏览器的地址栏中,输入URL地址"http://www.gacl.cn:8080/JavaWebDemo1/1.jsp"去访问服务器上的1.jsp这个web资源的过程中浏览器和服务器做了以下几个操作:
- 浏览器根据主机名"www.gacl.cn"去操作系统的Hosts文件中查找主机名对应的IP地址。
- 浏览器如果在操作系统的Hosts文件中没有找到对应的IP地址,就去互联网上的DNS服务器上查找"www.gacl.cn"这台主机对应的IP地址。
- 浏览器查找到"www.gacl.cn"这台主机对应的IP地址后,就使用IP地址连接到Web服务器。
- 浏览器连接到web服务器后,就使用http协议向服务器发送请求,浏览器以Stream(流)的形式传输数据,告诉Web服务器要访问哪个Web应用下的Web资源。
- 浏览器做完上面4步工作后,就开始等待,等待Web服务器把自己想要访问的1.jsp这个Web资源传输给它。
- 服务器接收并解析接收到的数据,将浏览器想要的资源再以Stream(流)的形式传输给浏览器。
借用网上大神画的时序图加以说明:
2.4tomcat的体系结构
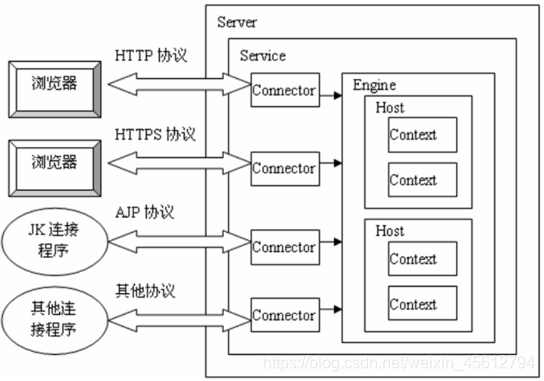
Tomcat的启动基于一个server.xml文件,首先会启动一个Server,Server就会启动Service,Service会启动多个"Connector(连接器)",每一个连接器都在等待客户机的连接,当有用户访问服务器上面的web资源时,首先是连接到Connector(连接器),但是Connector(连接器)不处理用户的请求,而是将请求转交给一个Engine(引擎)去处理,Engine(引擎)被激活后会解析用户想要访问的Host,然后将请求交给相应的Host,Host收到请求后就会解析用户想要访问哪一个Web应用,一个web应用对应一个Context。
<?xml version="1.0" encoding="UTF-8"?>
<Server port="8005" shutdown="SHUTDOWN">
<Listener className="org.apache.catalina.startup.VersionLoggerListener" />
<Listener className="org.apache.catalina.core.AprLifecycleListener" SSLEngine="on" />
<Listener className="org.apache.catalina.core.JreMemoryLeakPreventionListener" />
<Listener className="org.apache.catalina.mbeans.GlobalResourcesLifecycleListener" />
<Listener className="org.apache.catalina.core.ThreadLocalLeakPreventionListener" />
<GlobalNamingResources>
<Resource name="UserDatabase" auth="Container"
type="org.apache.catalina.UserDatabase"
description="User database that can be updated and saved"
factory="org.apache.catalina.users.MemoryUserDatabaseFactory"
pathname="conf/tomcat-users.xml" />
</GlobalNamingResources>
<Service name="Catalina">
<Connector port="8080" protocol="HTTP/1.1"
connectionTimeout="20000"
redirectPort="8443" />
<Connector port="8009" protocol="AJP/1.3" redirectPort="8443" />
<Engine name="Catalina" defaultHost="localhost">
<Realm className="org.apache.catalina.realm.LockOutRealm">
<Realm className="org.apache.catalina.realm.UserDatabaseRealm"
resourceName="UserDatabase"/>
</Realm>
<Host name="localhost" appBase="webapps"
unpackWARs="true" autoDeploy="true">
<Valve className="org.apache.catalina.valves.AccessLogValve" directory="logs"
prefix="localhost_access_log" suffix=".txt"
pattern="%h %l %u %t "%r" %s %b" />
</Host>
</Engine>
</Service>
</Server>
三、互联网上的加密原理
Tomcat服务器启动时候会启动多个Connector(连接器),而Tomcat服务器的连接器又分为加密连接器和非加密连机器。默认的8080端口是不加密的,要是想以一种加密的方式来访问Tomcat服务器,那么就要在Tomcat里面配置一个加密的Connector(连接器)。首先应该知道互联网上的加密原理。
3.1对称加密
定义:同一个密钥可以同时对信息进行加密和解密,这种加密方法称为对称加密,也称为单密钥加密。
特点:加密速度快。适用于对大量数据进行加密的场景。
缺点:因为加密和解密都使用同一个密钥,如何把密钥安全地传递到解密者手上就成了必须要解决的问题。
常用的对称加密有:DES、IDEA、RC2、RC4、SKIPJACK、RC5、AES算法等
3.2非对称加密
定义:需要公开密钥和私有密钥两把密钥,它们是成对存在的。如果用公开密钥对数据进行加密,只有用对应的私有密钥才能解密;如果用私有密钥对数据进行加密,那么只有用对应的公开密钥才能解密。因为加密和解密使用的是两个不同的密钥,所以这种算法叫作非对称加密算法。
非对称加密算法实现基本过程是:甲方生成一对密钥并将其中的一把作为公用密钥向其它方公开;乙方得到该公用密钥后,使用该密钥对机密信息加密后再发送给甲方;甲方再用自己保存的另一把专用密钥对加密后的信息进行解密。另一方面,乙方可以使用甲方的公钥对机密信息进行签名后再发送给甲方;甲方再用自己的私匙对数据进行验签。
非对称性加密依然没有解决数据传输的安全性问题,比如马云想向马化腾发送数据,马化腾生成一对密钥(公钥和私钥),然后将公钥发给马云,拿到公钥后,马云将机密信息用公钥加密后发给马化腾,然而在马化腾的公钥发送给马云的过程中,很有可能会被第三方王健林截获,王健林截获到马化腾的公钥后,也使用马化腾的公钥加密数据,然后发给马化腾,马化腾接收到数据后就犯傻了,因为根本不知道接收到的数据到底是发马云的还是王健林发的,这是其中一个问题,另一个问题就是,王健林截获到马化腾发的公钥后,王健林可以自己生成一对密钥(公钥和私钥),然后发给马云,拿马云到公钥后就以为是马化腾发给他的了,然后就使用公钥加密数据发给马化腾,发送给马化腾的过程中被王健林截获下来,由于马云是用王健林发给他的公钥加密数据的,而王健林有私钥,因此就可以解密马云加密过后的内容了,而马化腾接收到马云发给他的数据后反而解不开了,因为数据是用王健林的公钥加密的,马化腾没有王健林的私钥,所以就根本无法解密,有点偷梁换柱的感觉。所以,非对称性加密存在一个问题:马云想向马化腾发数据,马云如何确定拿到的公钥一定是马化腾发的呢?那么如何解决这个问题呢?只能靠一个第三方机构(CA机构,即证书授权中心(Certificate Authority ),或称证书授权机构)来担保。马云想向马化腾发数据,马化腾首先将公钥发给CA机构,CA机构拿到马化腾的公钥后跑到马化腾的家里问:这是你发的公钥吗?确马化腾确认过后说是:没错,是我发的!那么此时CA机构就会为马化腾的公钥做担保,生成一份数字证书给马化腾,数字证书包含了CA的担保认证签名和马化腾的公钥,马化腾拿到CA的这份数字证书后,就发给马云,马云拿到数字证书后,看到上面有CA的签名,就可以确定当前拿到的公钥是马化腾发的,那么就可以放心大胆地使用公钥加密数据,然后发给马化腾了。
四、HTTP协议
概念:HTTP是hypertext transfer protocol(超文本传输协议)的简写,它是TCP/IP协议的一个应用层协议,用于定义WEB浏览器与WEB服务器之间交换数据的过程。客户端连上web服务器后,若想获得web服务器中的某个web资源,需遵守一定的通讯格式,HTTP协议用于定义客户端与web服务器通迅的格式。
Http1.0和Http1.1的区别:在HTTP1.0协议中,客户端与web服务器建立连接后,**一个连接只能获得一个web资源;**在HTTP1.1协议,允许客户端与web服务器建立连接后,在一个连接上获取多个web资源。
4.1Http请求
一个完整的HTTP请求包括如下内容:一个请求行、若干消息头、以及实体内容
请求行:
-
请求行中请求方式有:POST、GET、HEAD、OPTIONS、DELETE、TRACE、PUT,比较常用的是GET和POST。默认情况下浏览器向服务器发送的都是get请求,用户如想把请求方式改为post,可通过更改表单的提交方式实现。
POST和GET都只是用于向服务器请求某个WEB资源的方式而已,这两种方式的主要区别在于数据传递的方式不同。 -
GET方式是在请求的URL地址后以?的形式拼接传递给服务器的数据,多个数据之间以&进行分隔;
GET方式的特点:在URL地址后附带的参数是有限制的,其数据容量通常不能超过1K。 -
POST方式可以将发送给服务器的数据保存在请求体(requestBody)。
-
Post方式的特点:传送的数据量无限制。
消息头:
accept:浏览器通过这个头告诉服务器,它所支持的数据类型
Accept-Charset: 浏览器通过这个头告诉服务器,它支持哪种字符集
Accept-Encoding:浏览器通过这个头告诉服务器,支持的压缩格式
Accept-Language:浏览器通过这个头告诉服务器,它的语言环境
Host:浏览器通过这个头告诉服务器,想访问哪台主机
If-Modified-Since: 浏览器通过这个头告诉服务器,缓存数据的时间
Referer:浏览器通过这个头告诉服务器,客户机是哪个页面来的 防盗链
Connection:浏览器通过这个头告诉服务器,请求完后是断开链接还是何持链接
4.2Http响应
一个HTTP响应代表服务器向客户端回送的数据,它包括: 一个状态行、若干消息头、以及实体内容 。
状态行:
固定格式:HTTP版本号 状态码 原因叙述 例如:HTTP/1.1 200 OK
状态码用于表示服务器对请求的处理结果,它是一个三位的十进制数。响应状态码分为5类,如下所示:
| 状态码 | 含义 |
|---|---|
| 100~199 | 表示成功接收请求,要求客户端继续提交下一次请求才能完成整个处理过程 |
| 200~299 | 表示成功接收请求并已完成整个处理过程。常用的有200 |
| 300~399 | 为完成请求,客户需进一步细化请求。例如,请求资源已经移动到一个新的地址。常用302(请求重定向的时候),307和304 |
| 400~499 | 客户端请求错误,常用404 |
| 500~599 | 服务器端出现错误,常用500 |
常用响应头:
Location: 服务器通过这个头,来告诉浏览器跳到哪里,实现请求重定向
Server:服务器通过这个头,告诉浏览器服务器的型号
Content-Encoding:服务器通过这个头,告诉浏览器,数据的压缩格式
Content-Length: 服务器通过这个头,告诉浏览器回送数据的长度
Content-Language: 服务器通过这个头,告诉浏览器语言环境
Content-Type:服务器通过这个头,告诉浏览器回送数据的类型
Refresh:服务器通过这个头,告诉浏览器定时刷新
Content-Disposition: 服务器通过这个头,告诉浏览器用下载的方式接收数据
Transfer-Encoding:服务器通过这个头,告诉浏览器数据是以分块方式回送的
Expires: -1 控制浏览器不要缓存
Cache-Control: no-cache
Pragma: no-cache
五、Servlet
5.1简介
Servlet是sun公司提供的一门用于开发动态web资源的技术。我们只需编写一个Java类,让它实现servlet接口,之后把它部署到web服务器中,就完成了一个Servlet类的简单编写。按照约定俗称的习惯,通常我们也把实现了servlet接口的java程序,称之为Servlet。
5.2Servlet的运行过程
Servlet程序是由WEB服务器调用,web服务器收到客户端的Http访问请求后:
①Web服务器检查是否已经装载并创建了该Servlet的实例对象。是的话直接执行第④步,否则执行第②步。
②装载并创建该Servlet的一个实例对象。
③调用Servlet实例对象的init()方法。
④创建一个用于封装HTTP请求消息的HttpServletRequest对象和一个代表HTTP响应消息的HttpServletResponse对象,然后调用Servlet的service()方法并将请求和响应对象作为参数传递进去。
⑤WEB应用程序被停止或重新启动之前,Servlet引擎将卸载Servlet,并在卸载之前调用Servlet的destroy()方法。
借用下面这幅图加深对Servlet的理解
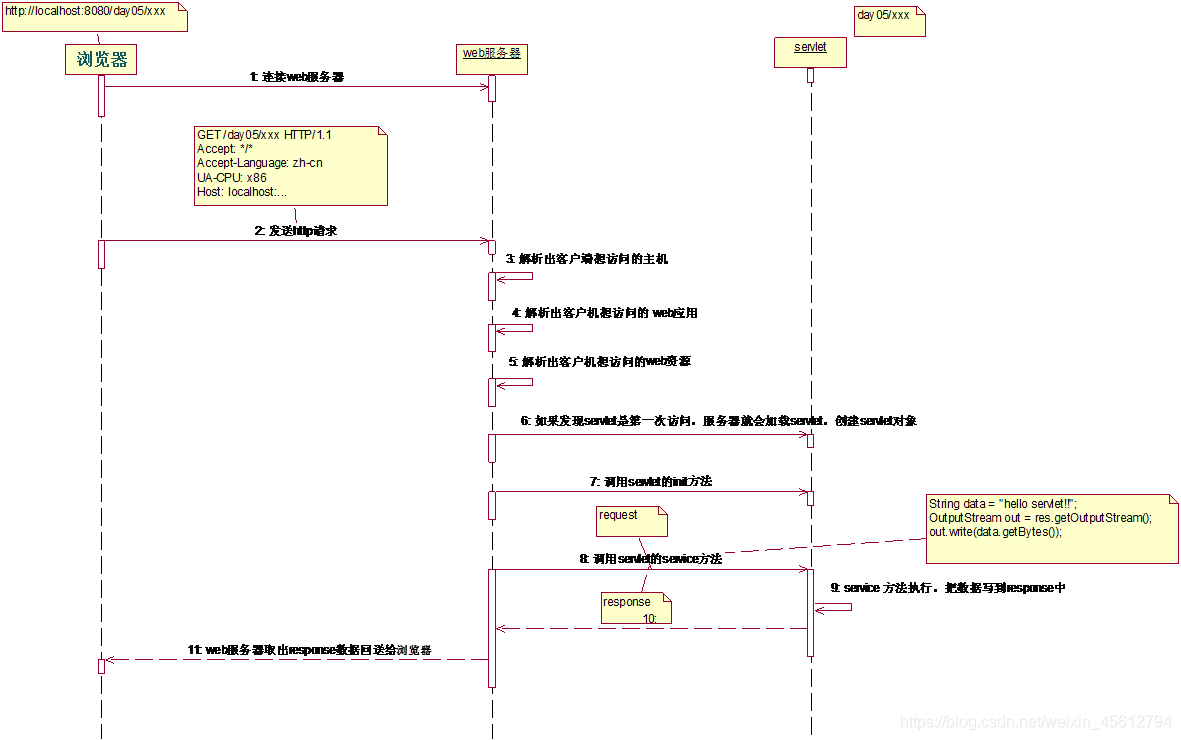
只有在第一次访问Servlet的时候,才会初始化Servlet实例。
5.3Servlet与普通Java类的区别
Servlet是一个供其他Java程序(Servlet引擎)调用的Java类,它的运行完全由Servlet引擎来控制和调度。不能独立运行。
在Servlet的整个生命周期内,Servlet的init方法只被调用一次,只会创建一个Servlet实例对象;而每次请求都会导致Servlet引擎调用一次servlet的service方法,此时Servlet引擎会创建一个新的HttpServletRequest请求对象和一个新的HttpServletResponse响应对象,作为参数传递给service()方法,service方法再根据请求方式分别调用doXXX方法,Servlet实例对象一旦创建,它就会驻留在内存中,直至web容器退出,servlet实例对象才会销毁。存在期间一直为每个请求服务。
如果在元素中配置了一个元素,那么WEB应用程序在启动时,就会装载并创建Servlet的实例对象、以及调用Servlet实例对象的init()方法。
举例:
invoker
org.apache.catalina.servlets.InvokerServlet
1
用途:为web应用写一个InitServlet,这个servlet配置为启动时装载,为整个web应用创建必要的数据库表和数据。
5.4Servlet的线程安全问题
当多个客户端并发访问同一个Servlet时,web服务器会为每一个客户端的访问请求创建一个线程,并在这个线程上调用Servlet的service方法,因此service方法内如果访问了同一个资源的话,就有可能引发线程安全问题。
解决方案:
- 给Servlet对象同步锁。实现方式是在doxxx方法体内加synchronized关键字。这种方式是可以实现的,但是并发量大的时候,系统等待时间长,很影响用户体验。(不推荐)
- 让Servlet去实现一个SingleThreadModel接口。这是Sun公司提供的解决方案,对于实现了SingleThreadModel接口的Servlet,Servlet引擎仍然支持对该Servlet的多线程并发访问,其采用的方式是产生多个Servlet实例对象,并发的每个线程分别调用一个独立的Servlet实例对象,加大了服务器的压力,因此在Servlet API 2.4中,已经将SingleThreadModel标记为Deprecated(过时的)。
- 线程安全问题造成的主要原因,是因为多个线程之间存在共享变量,因此较为妥善的做法,就是尽量减少共享变量的使用,改用为局部变量,我们知道局部变量是线程独享的,因此也就不存在线程安全问题了。(推荐)
5.5ServletConfig对象
在Servlet的配置文件web.xml中,可以使用一个或多个标签为servlet配置一些初始化参数。配置好这些参数后,web容器在创建servlet实例对象时,会自动将这些初始化参数封装到ServletConfig对象中,在调用servlet的init方法时,将ServletConfig对象传递给servlet。进而,我们通过ServletConfig对象就可以得到当前servlet的初始化参数信息。
5.6ServletContext对象
WEB容器在启动时,它会为每个WEB应用程序都创建一个对应的ServletContext对象,它代表当前web应用。ServletConfig对象中维护了ServletContext对象的引用,开发人员在编写servlet时,可以通过ServletConfig.getServletContext方法获得ServletContext对象。
由于一个WEB应用中的所有Servlet共享同一个ServletContext对象,因此Servlet对象之间可以通ServletContext对象来实现通讯。ServletContext对象通常也被称之为context域对象。
利用ServletContext可以实现请求转发、读取资源文件等功能。
六、response对象
Web服务器收到客户端的http请求后,会针对每一次请求分别创建一个代表请求的request对象和代表响应的response对象。
request和response对象即然代表请求和响应,那我们要获取客户机提交过来的数据,只需要找request对象就行了。要向客户机输出数据,只需要找response对象就行了。
6.1常用API
| 用途 | 方法名 |
|---|---|
| 向客户端发送数据 | getOutPutStream()、getWriter() |
| 向客户端发送响应头 | addDateHeader()、addHeader()、addIntHeader()、containsHeader() setDateHeader()、setIntHeader()、setHeader() |
| 向客户端发送响应状态码 | setStatus() |
此外还有一些常用的方法:
- response.setCharacterEncoding(charset)//设置字符以什么样的编码输出到浏览器()
-response.getWriter();//获取PrintWriter输出流,这句代码必须放在setCharacterEncoding("UTF-8")之后
-response.setHeader("content-type", "text/html;charset=UTF-8");//通过设置响应头控制浏览器以UTF-8的编码显示数据,如果不加这句话,那么浏览器显示的将是乱码
-response.sendRedirect(String location)//即调用response对象的sendRedirect方法实现请求重定向。sendRedirect内部的实现原理:使用response设置302状态码和设置location响应头实现重定向
6.2开发注意事项
-
在开发过程中,如果希望服务器输出什么浏览器就能看到什么,那么在服务器端都要以字符串的形式进行输出
-
当设置content-disposition响应头控制浏览器以下载的形式打开文件,中文文件名要使用URLEncoder.encode方法进行编码,否则会出现文件名乱码
-
编写文件下载功能时,推荐使用OutputStream流,避免使用PrintWriter流,因为OutputStream流是字节流,可以处理任意类型的数据,而PrintWriter流是字符流,只能处理字符数据,如果用字符流处理字节数据,会导致数据丢失。
-
web项目中URL的推荐写法:建议最好以"/"开头,也就是使用绝对路径的方式。可以用如下的方式来记忆"/":如果"/“是给服务器用的,则代表当前的web工程;如果”/"是给浏览器用的,则代表webapps目录。
-
使用**request.getContextPath()**代替"/项目名称",这会使项目更灵活!
-
getOutputStream和getWriter这两个方法互相排斥,调用了其中的任何一个方法后,就不能再调用另一方法。
七、request对象
HttpServletRequest对象代表客户端的请求,当客户端通过HTTP协议访问服务器时,HTTP请求头中的所有信息都封装在这个对象中,通过这个对象提供的方法,可以获得客户端请求的所有信息。
7.1常用API
获取客户端请求信息
| 方法名 | 描述 |
|---|---|
| getRequestURL() | 方法返回客户端发出请求时的完整URL |
| getRequestURI() | 方法返回请求行中的资源名部分 |
| getQueryString() | 方法返回请求行中的参数部分 |
| getPathInfo() | 方法返回请求URL中的额外路径信息,额外路径信息是请求URL中的位于Servlet的路径之后和查询参数之前的内容,它以“/”开头 |
| getRemoteAddr() | 方法返回发出请求的客户机的IP地址 |
| getRemoteHost() | 方法返回发出请求的客户机的完整主机名 |
| getRemotePort() | 方法返回客户机所使用的网络端口号 |
| getLocalAddr() | 方法返回WEB服务器的IP地址 |
| getLocalName() | 方法返回WEB服务器的主机名 |
获取客户机请求头
| 方法名 | 描述 |
|---|---|
| getHeader() | 根据请求头的名字获取对应的请求头的值 |
| getHeaders() | 根据请求头的名字获取对应的请求头的枚举 |
| getHeaderNames() | 获取所有的请求头 |
接收表单参数(POST表单提交)
| 方法名 | 描述 |
|---|---|
| getParameter() | 根据参数名获取参数的值 |
| getParameterNames() | 一次性获取所有参数名,再遍历通过getParameter()取值 |
7.2开发注意事项
-
post方式提交中文数据乱码产生的原因和解决方案:之所以会产生乱码,是因为服务器和客户端沟通的编码不一致造成的,因此解决的办法是:在客户端和服务器之间设置一个统一的编码,之后就按照此编码进行数据的传输和接收。服务器可以直接使用从ServletRequest接口继承而来的"setCharacterEncoding(charset)"方法进行统一的编码设置。如:request.setCharacterEncoding(“UTF-8”)设置服务器以UTF-8的编码接收数据后,此时就不会产生中文乱码问题了。
-
get方式提交中文数据乱码产生的原因和解决方案:对于以get方式传输的数据,request即使设置了以指定的编码接收数据也是无效的(至于为什么无效我也没有弄明白),默认的还是使用ISO8859-1这个字符编码来接收数据,客户端以UTF-8的编码传输数据到服务器端,而服务器端的request对象使用的是ISO8859-1这个字符编码来接收数据,服务器和客户端沟通的编码不一致因此才会产生中文乱码的。解决办法:在接收到数据后,先获取request对象以ISO8859-1字符编码接收到的原始数据的字节数组,然后通过字节数组以指定的编码构建字符串,解决乱码问题。
String name = request.getParameter("name"); name =new String(name.getBytes("ISO8859-1"), "UTF-8"); -
request对象作为一个域对象(Map容器)使用时,主要是通过以下的四个方法来操作:
方法名 描述 setAttribute(String name,Object o) 将数据作为request对象的一个属性存放到request对象中,例如:request.setAttribute(“data”, data); getAttribute(String name) 获取request对象的name属性的属性值,例如:request.getAttribute(“data”) removeAttribute(String name) 移除request对象的name属性,例如:request.removeAttribute(“data”) getAttributeNames() 获取request对象的所有属性名,返回的是一个,例如:Enumeration attrNames = request.getAttributeNames(); -
请求重定向和请求转发的区别
一个web资源收到客户端请求后,通知服务器去调用另外一个web资源进行处理,称之为请求转发/307。
一个web资源收到客户端请求后,通知浏览器去访问另外一个web资源进行处理,称之为请求重定向/302。
八、会话管理技术
概念:会话可简单理解为:用户开一个浏览器,点击多个超链接,访问服务器多个web资源,然后关闭浏览器,整个过程称之为一个会话。
有状态会话:一个同学到教室上课,下次再来教室,我们会知道这个同学曾经来过,这称之为有状态会话。
8.1保存会话的两种技术
| 名称 | 简介 |
|---|---|
| Cookie | Cookie是客户端技术,程序把每个用户的数据以cookie的形式写给用户各自的浏览器。当用户使用浏览器再去访问服务器中的web资源时,就会带着各自的数据去。这样,web资源处理的就是用户各自的数据了。 |
| Session | Session是服务器端技术,利用这个技术,服务器在运行时可以为每一个用户的浏览器创建一个独享的session对象,由于session为用户浏览器独享,所以用户在访问服务器的web资源时,可以把各自的数据放在各自的session中,当用户再去访问服务器中的其它web资源时,其它web资源再从用户各自的session中取出数据为用户服务。 |
8.2cookie使用注意事项
-
一个Cookie只能标识一种信息,它至少含有一个标识该信息的名称(NAME)和设置值(VALUE)。
-
一个WEB站点可以给一个WEB浏览器发送多个Cookie,一个WEB浏览器也可以存储多个WEB站点提供的Cookie。
-
浏览器一般只允许存放300个Cookie,每个站点最多存放20个Cookie,每个Cookie的大小限制为4KB。
-
如果创建了一个cookie,并将他发送到浏览器,默认情况下它是一个会话级别的cookie(即存储在浏览器的内存中),用户退出浏览器之后即被删除。若希望浏览器将该cookie存储在磁盘上,则需要使用maxAge,并给出一个以秒为单位的时间。将最大时效设为0则是命令浏览器删除该cookie
8.3session实现原理
服务器创建session出来后,会把session的id号,以cookie的形式回写给客户机,这样,只要客户机的浏览器不关,再去访问服务器时,都会带着session的id号去,服务器发现客户机浏览器带session id过来了,就会使用内存中与之对应的session为之服务。
8.4session对象的创建
在程序中第一次调用request.getSession()方法时就会创建一个新的Session,可以用isNew()方法来判断Session是不是新创建的。
8.5session对象的销毁
session对象默认30分钟没有使用,则服务器会自动销毁session。在web.xml文件中可以手工配置session的失效时间。
