1.运行界面输入 notepad
打开一个空的文档
2.linux下建立空文档
输入 : vi+任意不存在的文件名

3.删除指定范围行的内容
例如:删除第一行到倒数第三行
解释 :$ 表示最后一行 d 表示删除

4.光标在一行的移动
按0: 移动到行首
按$ : 移动到行尾
5.在一行的删除
按D : 此行光标后的内容全部删除
6.windows下查看本机 服务 窗口
7.linux下查看服务
chkconfig
8.查看历史输入内容
history
9.过滤查找历史输入的内容
history | grep + 想要查找的内容
10.查看端口
ss -nal

11.进入mysql
mysql -u +用户名 + -p

Hadoop学习:
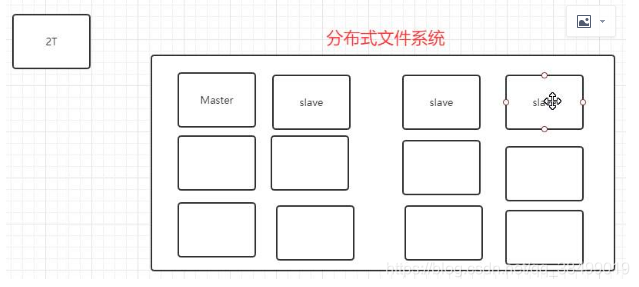
分布式存储:
Master:负责管理文件系统的文件结构 记录清单
slave: 奴隶 存储真正的数据 负责按照清单存储
block:块 1.x 64m 2.x 128m
eg:300M
replication: 副本机制 默认是三个副本
分布式计算:
移动数据:将数据移动到计算
移动计算:将计算移动到数据
HDFS:分布式文件系统
MapReduce:分布式计算框架
HDFS的角色
NameNode:主节点 负责管理文件系统的文件结构
DateNode :从节点 负责存储真是的数据
client : 客户端 负责读写数据
文件数据
1.元数据:描述数据的数据
2.数据本身:真实数据
HDFS常用的命令:
1.启动HDFS start-dfs.sh
2.启动NameNode hadoop-daemon.sh start|stop namenode
3.启动DataNode hadoop-daemon.sh start|stop datanode
4.停止HDFS stop-dfs.sh
