js的堆栈问题
堆栈,都是一种用于数据存储的数据结构,主要问题是内存的分配和使用。
堆(heap):
是堆内存的简称,可以从字面理解为混沌、杂乱无章,方便存储和开辟内存空间。
栈(stack):
是栈内存的简称,是线性结构,先进后出。
堆栈内存分配特性
- 堆是动态分配内存的,内存大小不一,也不会自动释放(常见问题就是内存溢出),js中的数组、对象、函数都存放在堆内存中。
- 栈是自动分配相对固定大小的内存空间,并由系统自动释放。
堆栈案例
基本数据类型:基本数据类型值是保存在栈内存中的简单数据段,访问方式是按值访问。
js中的基本类型:字符串(String)、数字(Number)、布尔(Boolean)、对空(Null)、未定义(Undefined)、Symbol
var a = 1; // 申明变量
| 栈内存 | 栈内存 |
|---|---|
| a | 1 |
a = 2; // 修改变量
| 栈内存 | 栈内存 |
|---|---|
| a | 2 |
基本类型变量的复制: 从一个变量向一个变量复制的时候,会在栈中创建一个新值,然后把值复制到为新变量分配的位置上。
var b = a; // 复制基本类型
| 栈内存 | 栈内存 |
|---|---|
| a | 1 |
| b | 1 |
b = 2;
| 栈内存 | 栈内存 |
|---|---|
| a | 1 |
| b | 2 |
引用数据类型: 引用数据类型值指保存在堆内存中的对象,也就是,变量中保存的实际上只是一个指针,这个指针指向内存中的另一个位置,该位置保存着对象。访问方式是按引用访问。
js中的引用数据类型:对象(Object)、数组(Array)、函数(Function)
var a = new Object(); // 引用

a.name= 'xz'; // 修改变量a
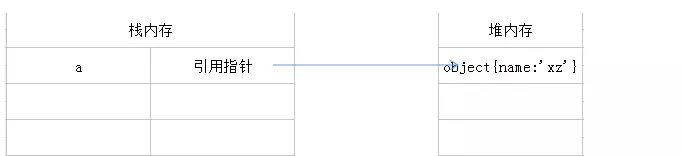
引用类型变量的复制: 复制的是存储在栈中的指针,将指针复制到栈中为新变量分配的空间中,而这个指针副本和原指针指向存储在堆中的同一个对象;复制操作结束后,两个变量实际上将引用同一个对象。因此,在使用时,改变其中的一个变量的值,将影响另一个变量。
var b = a; // 引用类型的复制
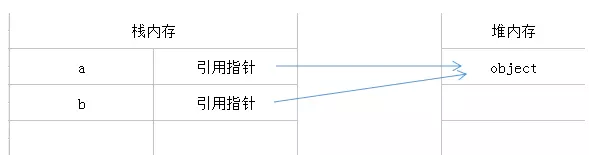
由于引用指针指向同一堆内存地址,所以修改a,也就是修改了堆内存中的object,也会影响到b。
a.age = '芳龄18';
console.log(b.age) // 芳龄18
js的深拷贝和浅拷贝
- 基本数据类型:String,Boolean,Number,Undefined,Null;
- 引用数据类型:Object(Array,Date,RegExp,Function);
- 基本数据类型和引用数据类型的区别:
保存位置不同:基本数据类型保存在栈内存中,引用数据类型保存在堆内存中,然后在栈内存中保存了一个对堆内存中实际对象的引用,即数据在堆内存中的地址,JS对引用数据类型的操作都是操作对象的引用而不是实际的对象,如果obj1拷贝了obj2,那么这两个引用数据类型就指向了同一个堆内存对象,具体操作是obj1将栈内存的引用地址复制了一份给obj2,因而它们共同指向了一个堆内存对象;
扫描二维码关注公众号,回复: 8590561 查看本文章
- 为什么基本数据类型保存在栈中,而引用数据类型保存在堆中?
1 ) 堆比栈大,栈比堆速度快;
2)基本数据类型比较稳定,而且相对来说占用的内存小;
3)引用数据类型大小是动态的,而且是无限的,引用值的大小会改变,不能把它放在栈中,否则会降低变量查找的速度,因此放在变量栈空间的值是该对象存储在堆中的地址,地址的大小是固定的,所以把它存储在栈中对变量性能无任何负面影响;
4)堆内存是无序存储,可以根据引用直接获取; - 深拷贝和浅拷贝简单解释:
浅拷贝和深拷贝都只针对于引用数据类型,浅拷贝只复制指向某个对象的指针,而不复制对象本身,新旧对象还是共享同一块内存;但深拷贝会另外创造一个一模一样的对象,新对象跟原对象不共享内存,修改新对象不会改到原对象;
区别 浅拷贝只复制对象的第一层属性、深拷贝可以对对象的属性进行递归复制; - 案例
JSON.parse(JSON.stringify(obj1));
