1. 内存映射
说到内存,这是我们买电脑时的重要考虑因素之一,现在的笔记本8GB内存已经很普遍了。这里说的8GB,其实是物理内存,也称主存,大多数计算机用的是动态随机访问内存(DRAM)。Linux下只有内核才可以访问物理内存,进程想要访问物理内存必须必须通过内核。Linux内核为每个进程提供了一个独立的虚拟地址空间,这个地址空间是连续的,它的内部又分为内核空间和用户空间。不同字长(也就是单个CPU指令可以处理的数据的最大长度)的处理器,地址空间范围也不同,像32位系统和64位系统,下图展示了它们的虚拟地址空间:

进程在内核态只能访问内核空间内存,在用户态只能访问用户空间内存。虽然每个进程的地址空间都包含了内核空间,但是这些内核空间都关联了相同的物理内存,而且进程的这么大的地址空间都加起来,必然远大于物理内存。所以,并不是所有的虚拟内存都分配了物理内存,只有那些使用了的虚拟内存会分配物理地址,并且这些虚拟内存和物理内存,是通过内存映射来管理的。内存映射,说白了就是将虚拟内存地址映射到物理内存地址。为了完成映射,内核为每个进程都维护了一张页表,记录虚拟内存地址和物理内存地址的映射关系,如下图:

页表实际上存储在CPU的内存管理单元的MMU当中,这样,CPU可以直接通过硬件,找出要访问的内存。而当进程访问的虚拟地址在页表中找不到时,系统会产生一个缺页异常,进入内核空间分配物理内存、更新进程页表、再返回用户空间,恢复进程的运行。
前面提过,TLB会影响CPU的内存访问性能。为什么呢?TLB其实是MMU中页表的高速缓存,缓存的是最近使用的数据的页表项,这样可以减少重复的页表查找。由于进程的虚拟地址空间是独立的,而TLB的访问速度远快于MMU,所以减少了进程的上下文切换,可以减少TLB的刷新频率,就可以提高TLB缓存的使用率,进而提高CPU的访问内存的性能。不过要注意,MMU并不以字节为单位来管理内存,而是规定了内存映射的最小单位,也就是页,通常是4KB大小。这样每次内存映射,都需要关联4KB或者4KB整数倍的内存空间。页的大小只有4KB,导致整个页表会非常的大。比如,32位系统就需要100多万个页表项(4GB/4KB),才能实现整个地址空间的映射。为了解决这个问题,Linux提供了两种解决方法,也就是大页(HugePage)和多级页表。
Linux正是使用了4级页表来管理内存页,如下图所示,虚拟地址被分为5个部分,前4个表项用于选择页,最后一个索引表示页内偏移。

再看大页,就是比普通页更大的内存块,常见的有2MB和1GB。大页通常用在使用大量内存的进程上,如DPDK、Oracle等。通过这些机制,在页表的映射下,进程就可以通过虚拟地址访问物理内存了。
2. 虚拟内存
下图展示32位系统虚拟内存的空间分布情况:
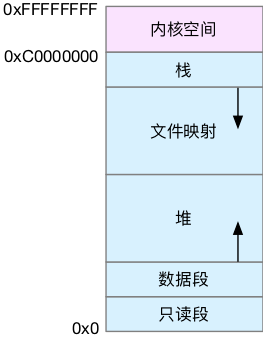
上图可以看出,用户空间内存其实分为几个段:
只读段:包括代码和常量等。
数据段:包括全局变量等。
堆:动态分配内存,从低地址开始向上增长。
文件映射:包括动态库、共享内存等,从高地址向下增长。
栈:包括局部变量、函数调用上下文等。栈的大小固定,一般8MB。
堆和文件映射段的内存是动态分配的,比如说,使用C标准库的malloc() 和 mmap() 就可以分别在他们内分配内存。
对于小块内存(小于128K),C标准库使用 brk() 来分配,通过移动堆顶的位置来分配内存。这些内存不会被释放,而是被缓存起来,可以重复利用。
对于大块内存(大于128K),直接使用内存映射 mmap() 分配,即在文件映射段找一块空闲内存分配出去。
这两种方式各有优缺点:
brk(),可以减少缺页异常的发生,提高内存访问效率。不过,由于这些内存没有归还系统,在内存工作繁忙时,频繁的分配和释放会导致内存碎片。
mmap(),在释放时会直接归还系统,所以每次mmap() 都会发生缺页异常。在内存工作繁忙时,频繁的内存分配会导致大量的缺页异常,使内核的管理负担增大,这也是 malloc 只对大内存使用 mmap的原因。
了解了两种调用方式,还要注意,当两种调用发生后,其实并没有马上分配内存,都只在首次访问时才分配,也就是通过缺页异常进入内核,再由内核来分配。整体来说,Linux使用伙伴系统来管理内存分配。伙伴系统也以页为单位管理内存,并通过相邻页的合并,减少内存碎片化( 比如 brk 造成的内存碎片 )。
在实际系统的运行过程中,还存在大量比页还小的对象,如果为他们也分配单独的页,那就太浪费内存。所以,在用户空间,malloc通过brk() 方式分配的内存,在释放时并不立即归还系统,而是缓存起来准备再利用。在内核空间,Linux则通过slab分配器来管理小内存。你可以把slab看成构建在伙伴系统之上的一个缓存,主要作用是分配并释放内核中小对象。对内存来说,如果只分配不释放,就会造成内存泄漏,甚至耗尽系统内存,所以最终还是要调用free 或 unmap 释放掉不用的内存。
当然系统是不会任由某个进程耗尽所有内存,当发现内存紧张时,系统会通过一系列机制来回收内存。比如通过以下三种方式:
- 回收缓存,比如使用LRU算法,回收最近最少使用的内存页。
- 回收不常访问的内存,把不常用的内存通过交换分区写到磁盘中。
- 杀死进程,内存紧张时系统会通过OOM(Out of Memory),直接杀掉占用大量内存的进程。
其中第二种方式,回收内存时,会用到交换分区,即swap。swap其实就是把一块磁盘空间当内存来使用,把暂时用不到的数据存到磁盘中(换出),当进程访问到这些内存时,再从磁盘读取这些数据到内存中(换入)。不过,通常只会在内存不足的时候,才会发生swap交换,并且由于磁盘读写速度远比内存慢,swap会导致严重的内存性能问题。
第三种方式,其实是内核的一种保护机制。它监控进程的内存使用情况,并且使用oom_score为每个进程的内存使用情况评分。即,进程消耗内存越大,oom_score越大,或者进程占用CPU越多,oom_score越小。也就是,oom_score越大的进程,因为消耗内存越大,越容易被OOM机制杀死。当然,为了实际工作的需要,可以通过/proc文件系统,手动设置进程的oom_adj,从而调整进程的oom_score。oom_adj的范围是 [-17, 15],数值越大,表示进程越容易被OOM杀死,-17表示禁止OOM。比如,用下面命令就可以把sshd进程的oom_adj调小到 -16,这样就不容易被OOM杀死:
echo -16 > /proc/$(pidof sshd)/oom_adj
3. 查看内存使用
先查看整个系统的内存使用情况:
# 注意不同版本的free输出可能会有所不同
$ free
total used free shared buff/cache available
Mem: 8169348 263524 6875352 668 1030472 7611064
Swap: 0 0 0free输出包含了物理内存和swap分区的使用情况。
used:已使用内存,包括共享内存。
shared:共享内存。
buff/cache:缓存和缓冲区大小。
available:新进程可用内存大小,包括未使用内存和可回收的缓存。
再看看每个进程的内存使用情况:
# 按下M切换到内存排序
$ top
...
KiB Mem : 8169348 total, 6871440 free, 267096 used, 1030812 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 7607492 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
430 root 19 -1 122360 35588 23748 S 0.0 0.4 0:32.17 systemd-journal
1075 root 20 0 771860 22744 11368 S 0.0 0.3 0:38.89 snapd
1048 root 20 0 170904 17292 9488 S 0.0 0.2 0:00.24 networkd-dispat
1 root 20 0 78020 9156 6644 S 0.0 0.1 0:22.92 systemd
12376 azure 20 0 76632 7456 6420 S 0.0 0.1 0:00.01 systemd
12374 root 20 0 107984 7312 6304 S 0.0 0.1 0:00.00 sshd
...看看跟内存相关的几列数据:
VIRT:进程虚拟内存的大小,只要进程申请过的,即便是没有分配物理内存,也计算在内。
RES:常驻内存大小,也就是实际使用的物理内存大小,不包括 swap 和 共享内存。
SHR:共享内存大小,但不完全是共享内存,比如加载的动态库、程序的代码段等。
%MEM:使用的物理内存占系统总内存的百分比。
4. 解读内存中的 Buffer 和 Cache
# 注意不同版本的free输出可能会有所不同
$ free
total used free shared buff/cache available
Mem: 8169348 263524 6875352 668 1030472 7611064
Swap: 0 0 0free输出中buff/cache之和代表的是缓存,字面上理解,Buffer是缓冲区,Cache是缓存,两者都是数据在内存中的临时存储。下文中,Buffer 和 Cache都会用英文表示,缓存则通指内存中的临时存储。
首先来查看一下man文档:
buffers
Memory used by kernel buffers (Buffers in /proc/meminfo)
cache Memory used by the page cache and slabs (Cached and Slab in /proc/meminfo)
buff/cache
Sum of buffers and cachebuffers 是内核缓冲区用到的内存,对应的是/proc/meminfo中 Buffers 的值。
cache 是内核页缓存和slab用到的内存,对应的是/proc/meminfo中的 Cached 和 Slab的值之和。
这里只是说明了这些数值的来源是/proc/meminfo,并没说清楚具体含义。
接下来查看man proc 搜索meminfo:
Buffers %lu
Relatively temporary storage for raw disk blocks that shouldn't get
tremendously large (20MB or so).
Cached %lu
In-memory cache for files read from the disk (the page cache).
Doesn'tinclude SwapCached.
...
Slab %lu
In-kernel data structures cache.
SReclaimable %lu (since Linux 2.6.19)
Part of Slab, that might be reclaimed, such as caches.
SUnreclaim %lu (since Linux 2.6.19)
Part of Slab, that cannot be reclaimed on memory pressure.Buffers 对原始磁盘块的临时存储,即缓存磁盘的数据,通常不会特别大(20MB左右)。这样,内核就可以把分散的写集中起来,统一优化磁盘的写入,比如多次小的写入合并成单次大的写入。
Cached 从磁盘读取文件的页缓存,即用来缓存从文件读取的数据,这样,下次需要访问这些文件数据时,就可以直接从内存快速获取,不需要从缓慢的磁盘获取。
SReclaimable 是Slab的一部分,表示可回收部分。
SUnreclaim 是Slab的一部分,表示不可回收部分。
这里虽然弄清楚了他们的含义,但是真的就理解了吗?这里提两个问题:
第一个,Buffers 的文档中没有提到是磁盘读数据还是写数据的缓存,网络搜索中说是对写入磁盘数据的缓存,那会不会缓存磁盘读数据呢?
第二个,Cached的文档中说是文件读数据的缓存,那么会不会有写数据的缓存呢?
针对这两个问题,下面使用两个案例说明。
首先,为了减少已有系统缓存的影响,执行下面命令清除系统缓存:
# 清理文件页、目录项、Inodes等各种缓存
$ echo 3 > /proc/sys/vm/drop_caches场景一、磁盘写和文件写
写文件:
# 每隔1秒输出1组数据
$ vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 7743608 1112 92168 0 0 0 0 52 152 0 1 100 0 0
0 0 0 7743608 1112 92168 0 0 0 0 36 92 0 0 100 0 0使用工具vmstat,输出结果中,重点关注几列:buff、cache、bi、bo。其中,bi、bo分别表示块设备的读取和写入,单位是块/秒,因为Linux中块就是1KB,所以这里等价于 KB/s。
正常情况,空闲系统中这几个值应该都保持不变。在执行以下命令,通过读取随机设备,生成500MB的文件:
$ dd if=/dev/urandom of=/tmp/file bs=1M count=500然后再观察,vmstat输出结果中buff 和 cache 变化情况:
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 7499460 1344 230484 0 0 0 0 29 145 0 0 100 0 0
1 0 0 7338088 1752 390512 0 0 488 0 39 558 0 47 53 0 0
1 0 0 7158872 1752 568800 0 0 0 4 30 376 1 50 49 0 0
1 0 0 6980308 1752 747860 0 0 0 0 24 360 0 50 50 0 0
0 0 0 6977448 1752 752072 0 0 0 0 29 138 0 0 100 0 0
0 0 0 6977440 1760 752080 0 0 0 152 42 212 0 1 99 1 0
...
0 1 0 6977216 1768 752104 0 0 4 122880 33 234 0 1 51 49 0
0 1 0 6977440 1768 752108 0 0 0 10240 38 196 0 0 50 50 0可以发现,buff基本不变,cache在不停增长,bi只有一次488 KB/s,bo有一次4KB/s,但过一段时间后,才出现大量块设备写,122880KB/s。当dd命令执行结束,cache 停止增长,bo 还会持续一段时间,而且多次bo的结果加起来,才是500MB数据。这个结果和上面的cache定义有区别,上面说的文件读的缓存,这里却是文件写的缓存。
磁盘写:
还是先看看下面磁盘写的案例,再统一分析。下面命令对环境要求高,需要多块磁盘,并且磁盘分区/dev/sdb1还要处于未使用状态。如果你的系统只有一块磁盘,千万不要尝试,否则会造成磁盘分去损坏。
# 首先清理缓存
$ echo 3 > /proc/sys/vm/drop_caches
# 然后运行dd命令向磁盘分区/dev/sdb1写入2G数据
$ dd if=/dev/urandom of=/dev/sdb1 bs=1M count=2048procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 0 7584780 153592 97436 0 0 684 0 31 423 1 48 50 2 0
1 0 0 7418580 315384 101668 0 0 0 0 32 144 0 50 50 0 0
1 0 0 7253664 475844 106208 0 0 0 0 20 137 0 50 50 0 0
1 0 0 7093352 631800 110520 0 0 0 0 23 223 0 50 50 0 0
1 1 0 6930056 790520 114980 0 0 0 12804 23 168 0 50 42 9 0
1 0 0 6757204 949240 119396 0 0 0 183804 24 191 0 53 26 21 0
1 1 0 6591516 1107960 123840 0 0 0 77316 22 232 0 52 16 33 0这里发现,磁盘写和文件写的现象还是不同的。写磁盘时,buff 和 cache都在增长,但是buff 增长更快,这说明写磁盘用到大量buffer,这和上面案例之前的解说一致
对比文件写和磁盘写的案例,写文件会用到cache 缓存数据,写磁盘会用到buffer 缓存数据。虽然文档提到cache 只用于读文件,但实际中,写文件也会用到cache 缓存。
场景二、磁盘读 和 文件读案例
读文件:
# 首先清理缓存
$ echo 3 > /proc/sys/vm/drop_caches
# 运行dd命令读取文件数据
$ dd if=/tmp/file of=/dev/null
观察内存和I/O:
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 1 0 7724164 2380 110844 0 0 16576 0 62 360 2 2 76 21 0
0 1 0 7691544 2380 143472 0 0 32640 0 46 439 1 3 50 46 0
0 1 0 7658736 2380 176204 0 0 32640 0 54 407 1 4 50 46 0
0 1 0 7626052 2380 208908 0 0 32640 40 44 422 2 2 50 46 0观察结果发现,buff不变,而cache逐步增长,与上面解说一致,cache是文件读的页缓存。
读磁盘:
# 首先清理缓存
$ echo 3 > /proc/sys/vm/drop_caches
# 运行dd命令读取文件
$ dd if=/dev/sda1 of=/dev/null bs=1M count=1024
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 7225880 2716 608184 0 0 0 0 48 159 0 0 100 0 0
0 1 0 7199420 28644 608228 0 0 25928 0 60 252 0 1 65 35 0
0 1 0 7167092 60900 608312 0 0 32256 0 54 269 0 1 50 49 0
0 1 0 7134416 93572 608376 0 0 32672 0 53 253 0 0 51 49 0
0 1 0 7101484 126320 608480 0 0 32748 0 80 414 0 1 50 49 0观察结果发现,cache基本不变,而buff增长较快。说明读磁盘,数据缓存在buffer 中。
综合上述两个场景的实验结果:
buffer是对磁盘数据的缓存,cache是对文件数据的缓存,他们机会用在读请求中,也会用在写请求中。
以上是工作之余的学习总结,因CSDN网站的变态要求,这里不能提供内容来源,敬请谅解。
