目录

集群模式的connect,就是在kafka集群中的每个节点上,按照下面对应的配置和说明进行操作,然后将kafka集群中各个节点上都启动对应的kafka-connect服务。然后通过REST API连接connect集群中某个节点即可,然后进行动态管理connect任务。
(1)配置linux中connect分配:
修改kafka安装路径下的bin/connect-distributed.sh文件,可以修改分配给connect的内存:
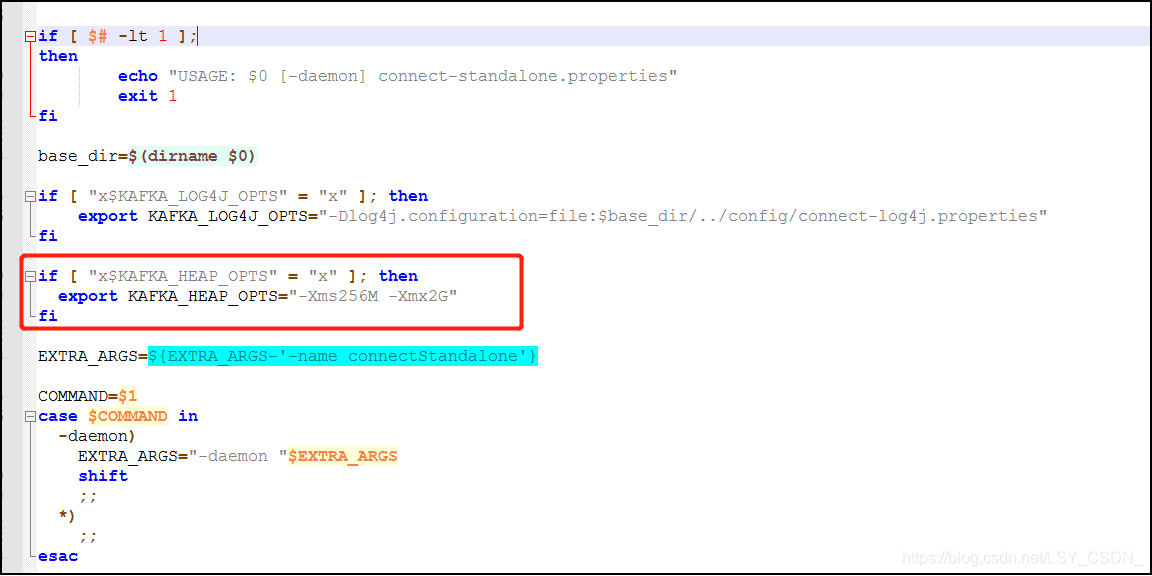
(2)配置connect-distributed参数:
A、broker访问地址:
参数:bootstrap.servers,值为集群kafka访问地址。
B、组ID唯一名称:
参数:group.id,值为connnect集群的唯一名称,名称一致的connect将组成一个集群。
C、offset存储的topic:
参数:offset.storage.topic,值为connect的offset在kafka中存储的topic名称。
D、offset存储的副本数:
参数:offset.storage.replication.factor,值为connect的offset在kafka中存储的topic对应的副本数。
E、offset存储的分区数:
参数:offset.storage.partitions,值为connect的offset在kafka中存储的topic对应的分区数。
F、config存储的topic:
参数:config.storage.topic,值为connect的config在kafka中存储的topic名称。
G、config存储的副本数:
参数:config.storage.replication.factor,值为connect的config在kafka中存储的topic的副本数。
H、status存储的topic:
参数:status.storage.topic,值为connect的status在kafka中存储的topic名称。
I、status存储的副本数:
参数:status.storage.replication.factor,值为connect的status在kafka中存储的topic的副本数。
J、status存储的分区数:
参数:status.storage.partitions,值为connect的status在kafka中存储的topic的分区数。
(3)手动在kafka中创建三种topic:
如果启动 Kafka Connect 时还没有创建 topic,那么 topic 将自动创建(使用默认的分区和副本),这可能不是最合适的(因为 Kafka 可不知道业务需要,只能根据默认参数创建)。
因此在启动kafka-connect之前,需要手动在kafka中创建好在connect-standalone.properties中配置的offset、config、status对应的topic以及设置好topic对应的分区数、副本数等参数。
(4)启动connect集群:
./connect-distributed.sh ../config/connect-distributed.properties
(5)动态管理connect:
注意分布式环境下不能像单机模式下的connect通过命令行修改配置,集群模式下的connect先启动,然后通过REST API来操作修改配置参数,将类似单机模式下的connect配置参数包含在一个json中,json中的参数格式如下,具体配置参数通单机模式下对应的参数配置相同,具体可以通过单机模式中提示的再confluent官网上查找对应数据系统类型的配置参数。然后通过kafka-connect的REST API进行操作,操作的配置信息将直接保存在kafka对应的topic中。操作kafka-connect的REST API详情见下面中的整理。可以通过java代码或restclient工具来完成对应的get post put等命令的执行。
例如:
curl -X POST -H "Content-Type: application/json" --data '{"name": "local-file-sink", "config": {"connector.class":"FileStreamSinkConnector", "tasks.max":"1", "file":"test.sink.txt", "topics":"connect-test" }}' http://localhost:8083/connectors(6)测试connect:
A、手动创建数据来源source:
通过手动执行connect的REST API创建对应的数据来源source。
B、手动创建数据目的sink:
通过手动执行connect的REST API创建对应的数据目的sink。
C、测试connect:
在数据来源的地方动态的添加数据,在kafka对应的topic中,以及对应的数据目的的地方可以看到新添加的数据。这样的结果就表示通过kafka-connect可以实时的同步数据了。
