- 正则表达式:

- 在stdin中搜索匹配特定模式的文本行:
echo -e "this is a word\nnext line" | grep word
- 文件中搜索匹配特定模式的文本行
grep "d" 1.txt
- grep命令默认使用基础正则表达式。
grep -E "[a-d]+" 1.txt
- 选项-o可以只输出匹配到的文本:
echo this is a line. | egrep -o "[a-z]+\."
- 选项-v可以打印出不匹配字符d的所有行:
grep -v d 1.txt
- 选项-c能够统计出匹配字符d的文本行数,只是匹配行的数量,不是匹配的次数:
grep -c d 1.txt
- 选项-b可以打印出匹配出现在行中的偏移。配合选项-o可以打印出匹配所在字符或字节偏移。
echo fff ee aa zs | grep -b -o "ee"
- 需要在多级目录对文本d进行递归搜索
grep "d" . -R -n
命令中的.指定了当前目录。
- 使用-e可以匹配多个模式:
echo this is a line of text | grep -o -e "ts" -e "a"
- grep可以在搜索过程中使用通配符指定(include)或排除(exclude)某些文件。
使用–include选项在目录中递归搜索所有的.c和.cpp文件:
grep "main()" . -r --include *.{c,cpp}
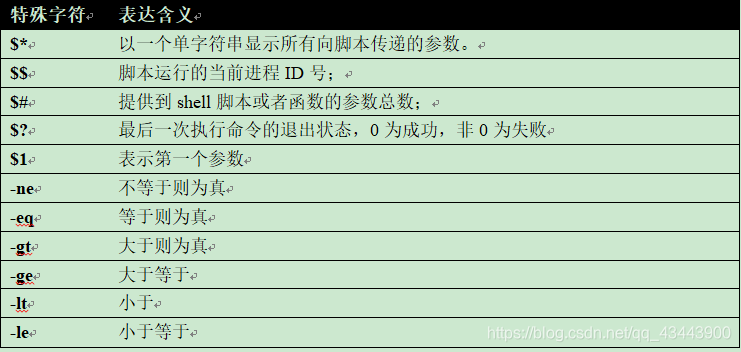
13. 有时候并不打算查看匹配的字符串,而是想知道能否成功匹配。这可以通过设置grep的静默选项(-q)来实现。0成功非0失败。
- 选项-A可以打印匹配结果5之后的3行(包括5):
seq 10 | grep 5 -A 3
- 选项-B可以打印匹配结果之前的行。
- 选项-A和-B可以结合使用,或者也可以使用-C,匹配之前及之后的n行:
seq 10 | grep 5 -C 3
- cut命令可以按列,而不是按行来切分文件。该命令可用于处理使用固定宽度字段的文件、CSV文件或是空格分隔的文件。
cut -f 2,3 1.sh
- 打印2-3字符
cut -c 2-3 1.sh
- 打印前2个字符
cut -c -2 1.sh
- sed可以使用2替换3,匹配模式。
sed 's/2/3/' 2.txt
- 选项-i会使得sed用修改后的数据替换原始数据(不显示在屏幕):
sed -i 's/h/ww/' 2.txt
- 之前的例子只替换了每行中模式首次匹配的内容。g标记可以使sed执行全局替换。
sed 's/w/33/g' 2.txt
- #g标记可以替换第N次出现的匹配:
echo thisthisthisthis | sed 's/this/THIS/2g'
- sed命令会将s之后的字符视为命令分隔符。这允许我们更改默认的分隔符/:
echo thisthisthisthis | sed 's|this|THIS|3g'
- sed命令可以使用正则表达式作为模式,另外还包含了大量可用于文本处理的选项。
- 使用指定的数字替换文件中所有1位数的数字,\b表示单词边界:
sed -i 's/\b[0-9]\{1\}\b/NUMBER/g' 2.txt
- 指定匹配给定模式的字符串。我们还可以使用#来指代出现在括号中的部分正则表达式所匹配到的内容:
echo this is digit 7 in a number | sed 's/digit \([0-9]\)/\1/'
这条命令将dight7替换为7。(pattern)\用于匹配子串,在本例中匹配的子串是7。子模式被放入使用反斜线转义过的()中。对于匹配到的第一个子串,对应的标记是\1,第二个是\2
28. 可以利用管道组合多个sed命令,多个模式之间可以用分号分隔
echo abc | sed 's/a/A/;s/c/C/'
- 如果要在sed表达式中使用变量,双引号可以使用。
sed "s/$tezt/HELLO/"
- awk命令可以处理数据流。它支持关联数组、递归函数、条件语句等功能。
- 输出文件行数:
awk 'BEGIN {i=0 } { i++ } END { print i }' 1.sh
-
awk命令的工作方式如下:
a) awk命令首先执行BEGIN{}语句块中的语句
b) 接着从文件或stdin中读取一行,如果能够匹配pattern,则执行随后的commands语句块。重复这个过程,直到文件全部被读取完毕。
c) 当读至输入流末尾时,执行END{ commands }语句块。
BEGIN语句块在awk开始从输入流中读取行之前被执行。

34. print $NF,打印一行中最后一个字段
- 使用NR统计文件的行数:
awk 'END{ print NR }' 1.sh
这里只用到了END语句块。每读入一行,awk都会更新NR
37. 将外部变量值传递给awk
awk -v v=$var '{print v}'
或者:
echo | awk '{ print v1,v2 }' v1=$var1 v2=$var2 u
- awk有很多内建的字符串处理函数。
length(string):返回字符串string的长度。
index(string, search_string):返回search_string在字符串string中出现的位置。
split(string, array, delimiter):以delimiter作为分隔符,分割字符串string,
将生成的字符串存入数组array。 substr(string, start-position, end-position) :返回字符串 string 中 以start-position和end-position作为起止位置的子串。
sub(regex, replacement_str, string):将正则表达式regex匹配到的第一处内容替换成replacment_str。
gsub(regex, replacement_str, string):和sub()类似。不过该数会替换正则表达式regex匹配到的所有内容。
match(regex, string):检查正则表达式regex是否能够在字符串string中找到匹配。如果能够找到,返回非0值;否则,返回0。match()有两个相关的特殊变量,分别是RSTART
和RLENGTH。变量RSTART包含了匹配内容的起始位置,而变量RLENGTH包含了匹配内容的长度。 - egrep命令将文本文件转换成单词流,每行一个单词。模式\b[[:alpha:]]+\b能够匹配每个单词并去除空白字符和标点符号。选项-o打印出匹配到的单词,一行一个。
- 移除\n和\t:
tr -d ‘\n\t’
- 移除多余的空格:
tr -s ‘’
或者:
sed ‘s/[ ]\+/ /g’
- 移除注释:
sed ‘s:/\*.*\*/::g’
.*用来匹配/与/之间所有的文本
43. 按列合并:
paste 1.txt 2.txt
- 默认分隔符是制表符,也可以用-d指定分隔符:
paste 1.txt 2.txt -d ","
- 以逆序打印行:
tac 1.sh
