1. Mysql的性能指标
mysql性能的参考指标是TPS、QPS和等待响应时间。
TPS=(事务提交数量+事务回滚数量)/服务器启动的时间
QPS=(查询的数量)/服务器启动的时间
等待响应时间=返回结果的时间-执行开始的时间

Mysql5.1.x版本后带入了很多实用的测试工具,能够自动测试高并发下,多用户的多查询性能数据,例如MySqlSlap。
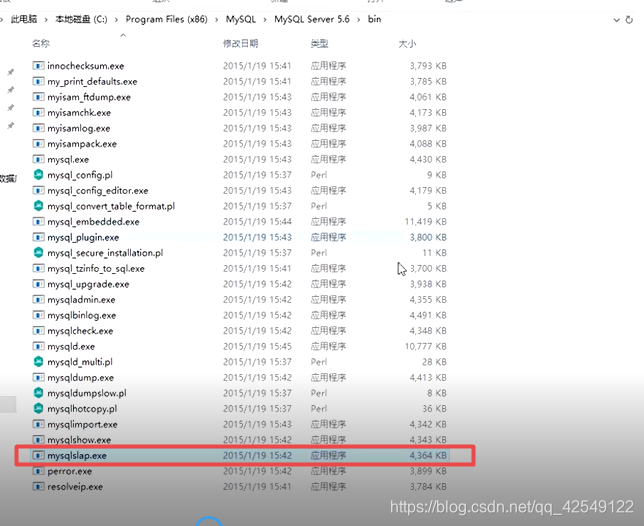
在命令窗口下,输入一些操作参数,即可按参数值进行测试,测试自动创建数据,并模仿高并发环境下的多用户查询。在测试返回结果后,会自动删除测试时创建的查询数据。

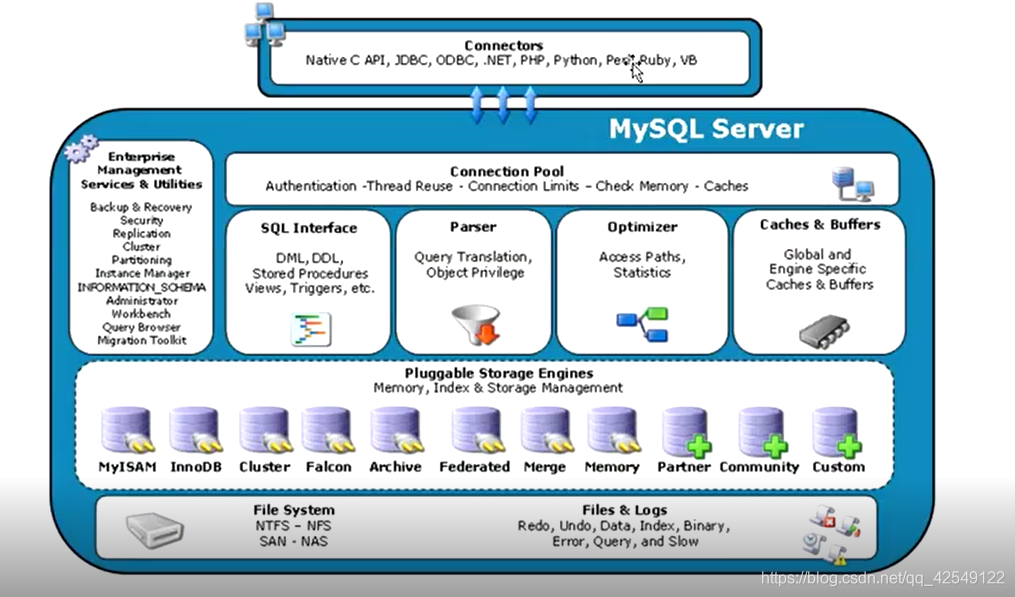
2.MySql的架构逻辑
MySql的架构
- 连接层
- 服务层
- 引擎层
- 储存层
- 连接层:
(1)
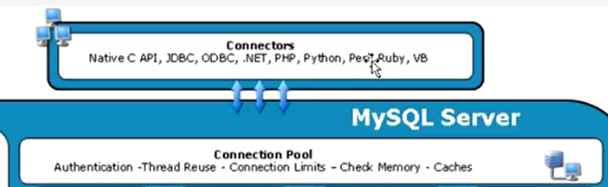
数据库的连接是支持多种语言的,常见的是JDBC驱动连接
(2)
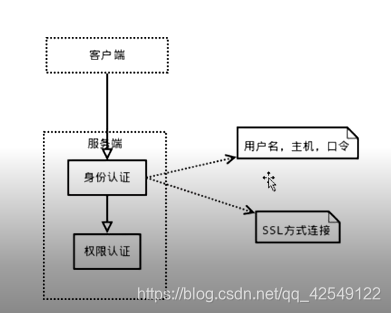
连接得过程中,会验证用户得用户名和密码极其试别其权限等操作。
(3)
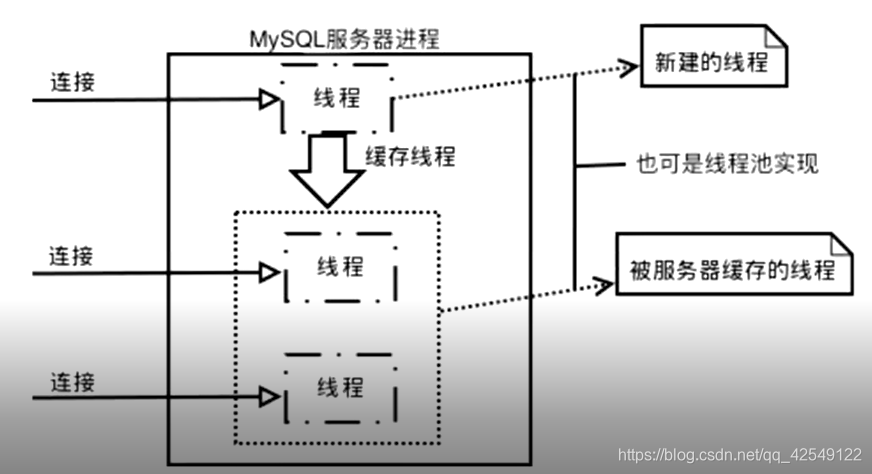
MySql是为多用户服务设计的,每个用户客户端连接成功后,都会之分配一个线程,每个线程是相对独立的,多个用户线程查询是没有问题的,但是如果不加约束对数据库进行数据的修改,那么势必会造成数据的同步问题。
- 服务层:
这一层的功能主要是Sql语句的解析,优化,缓存的查询。
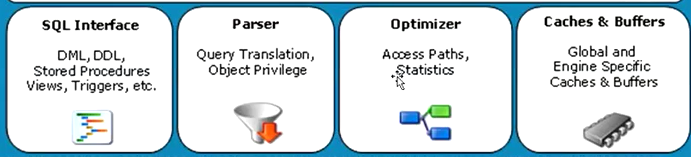
Sql Interface:Sql语句的接口层
Parser:解析器,将你写的命令转换到数据库自己所认识的
Optimizer:优化器
Caches&Buffers:缓存器, 默认开启的是缓存执行优化后的SQL语句,也可以开启数据的缓存。
Sql的处理流程
如果是查询语句来看
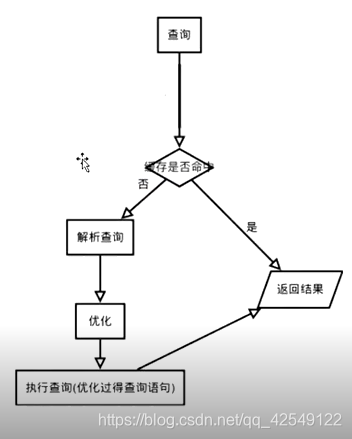
首先看缓存中是否存在相同的Sql语句,相同则命中,直接从缓存里返回结果。如果没有命中,则首先解析查询语句(解析器会按照自己识别的顺序创建一颗解析树,解析Sql语句中的语法和语义),然后进行优化(例如,重写查询,选择适合需要的索引等等),然后执行查询。
缓存
利用show VARIABLES LIKE ‘%query_cache_type%’ 查询缓存开启的状态
SET GLOBAL query_cache_type=1 为开启 =0为关闭
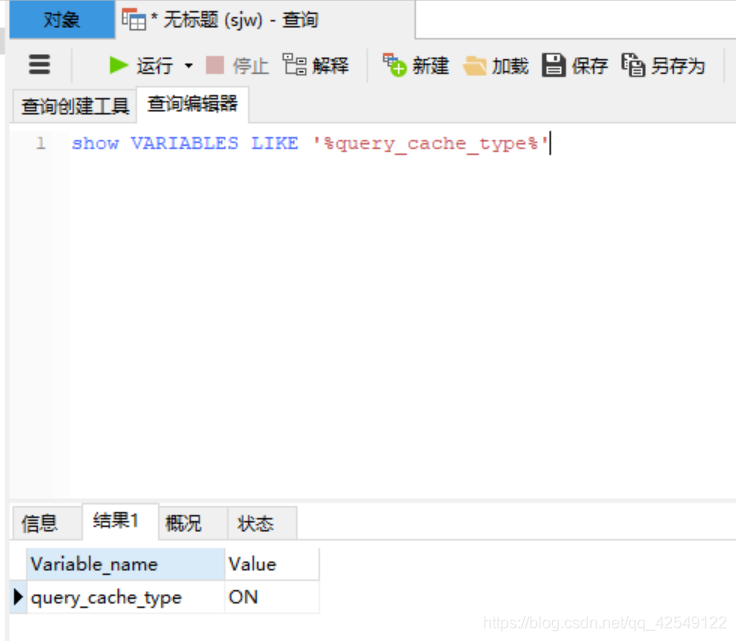
show VARIABLES LIKE '%query_cache_size%'查询缓存size的大小

如果你要通过缓存查询数据,用来提高查询速度,那么你首先需要启动缓存,然后需要设置缓存的size不为0(根据缓存量的大小设置size)
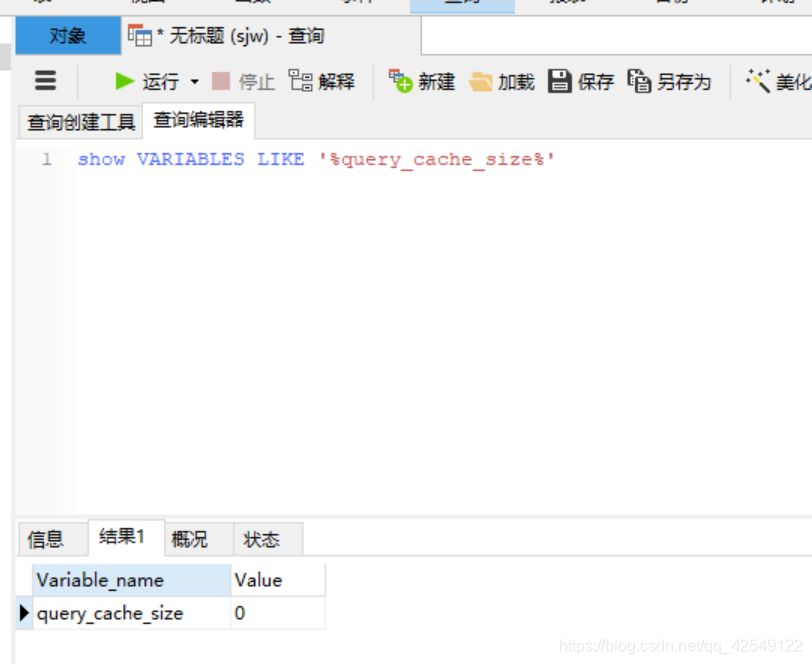
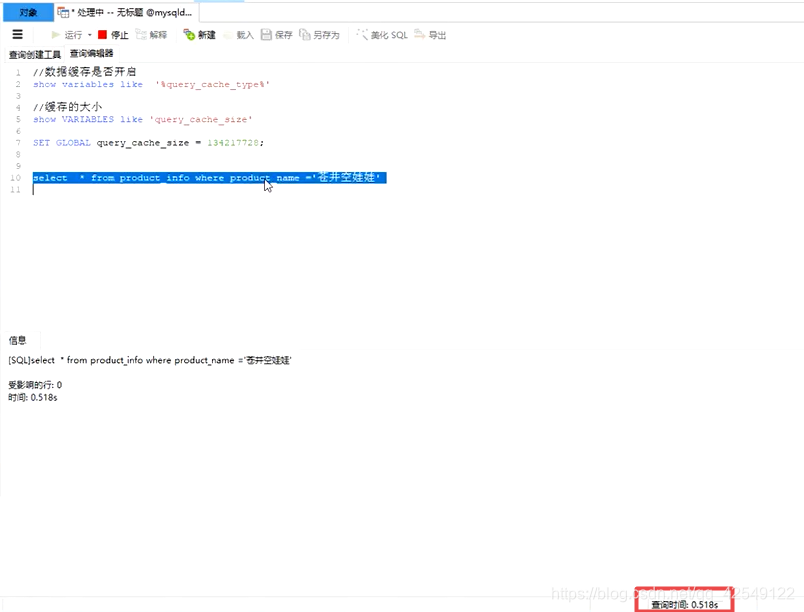
示例:第一次查询(未缓存过)为0.5s左右
第二次查询 0.002s
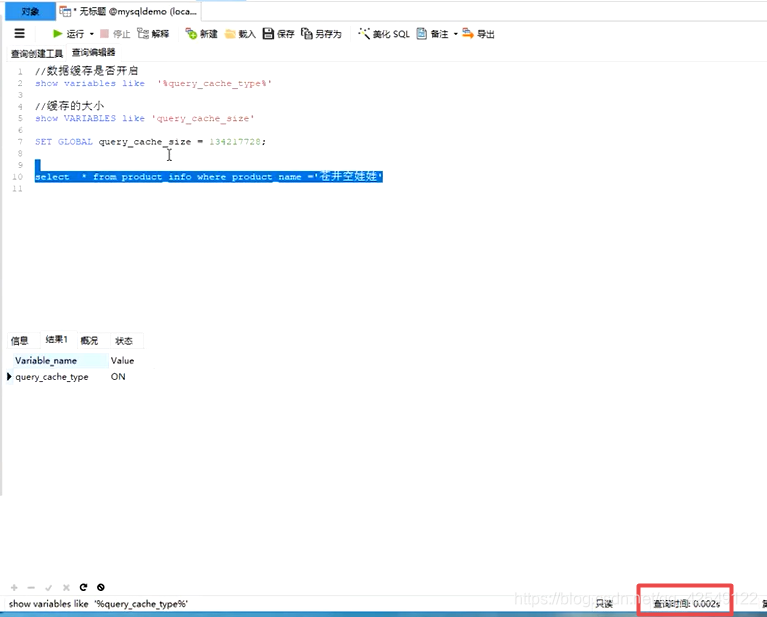
不建议MySql开启缓存,因为容易产生脏数据的错误等,在实际开发中,更适合做缓存的是Redis
优化
它会优化一些SQL语句中一些不可能的事情,或者SQL语句中不合理的地方。
例如:首先我们看下要作为示例表的结构
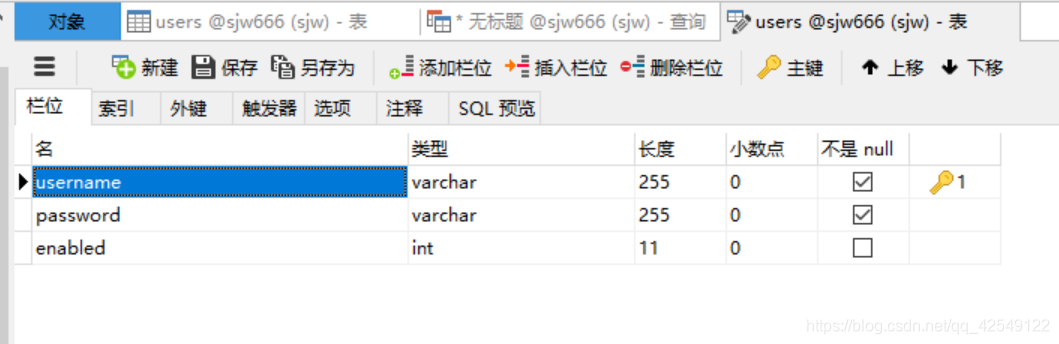
执行一个解析查询语句,发现这个SQL语句是正确的
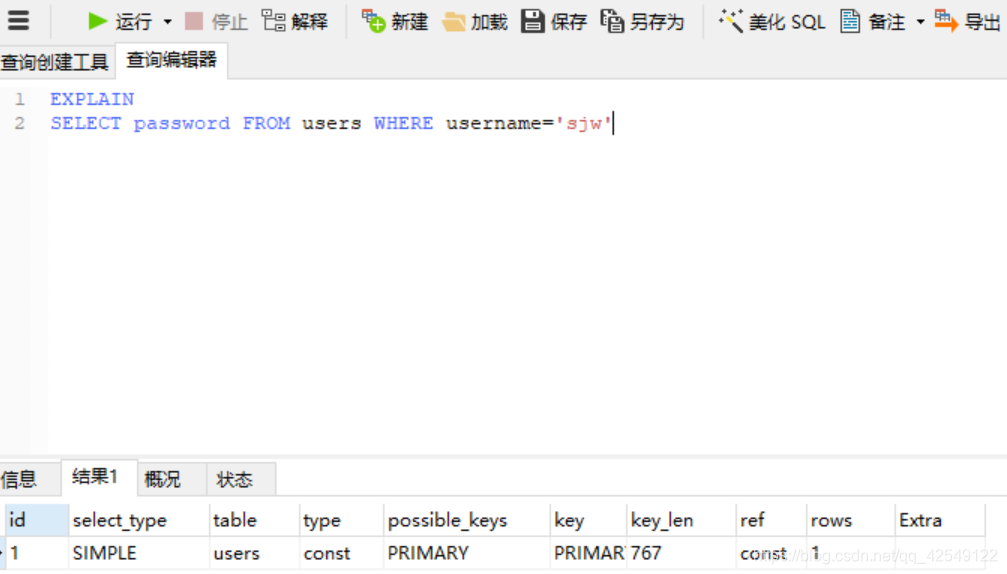
我们在运行一个没有语法错误,但是不可能实现的(主键的字段不可能为空)会被优化成不可能,不予查询。
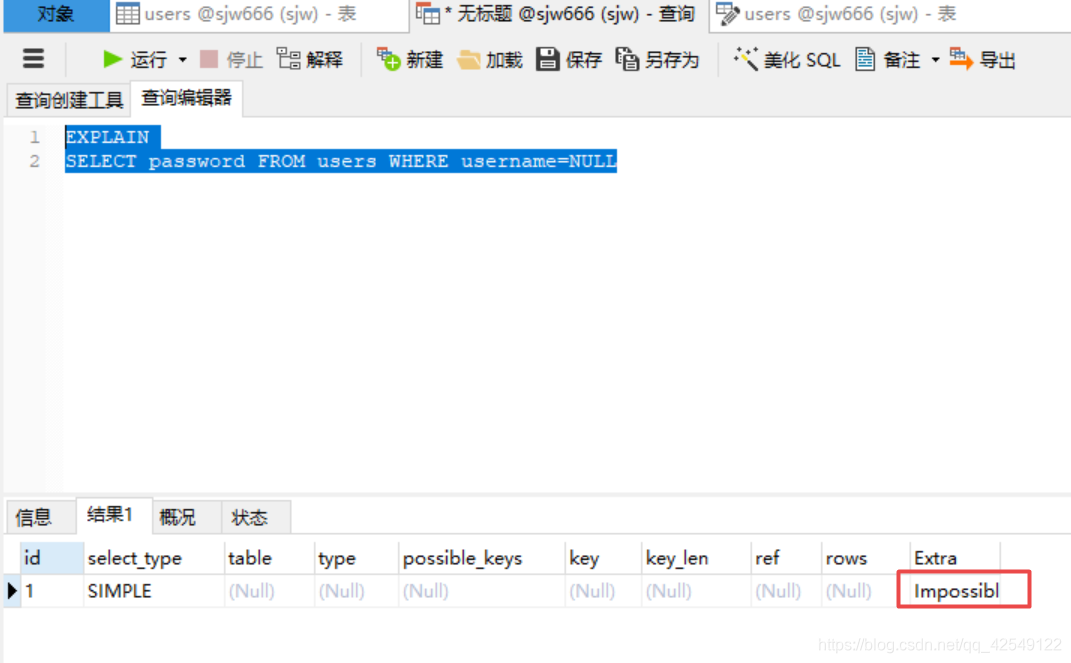
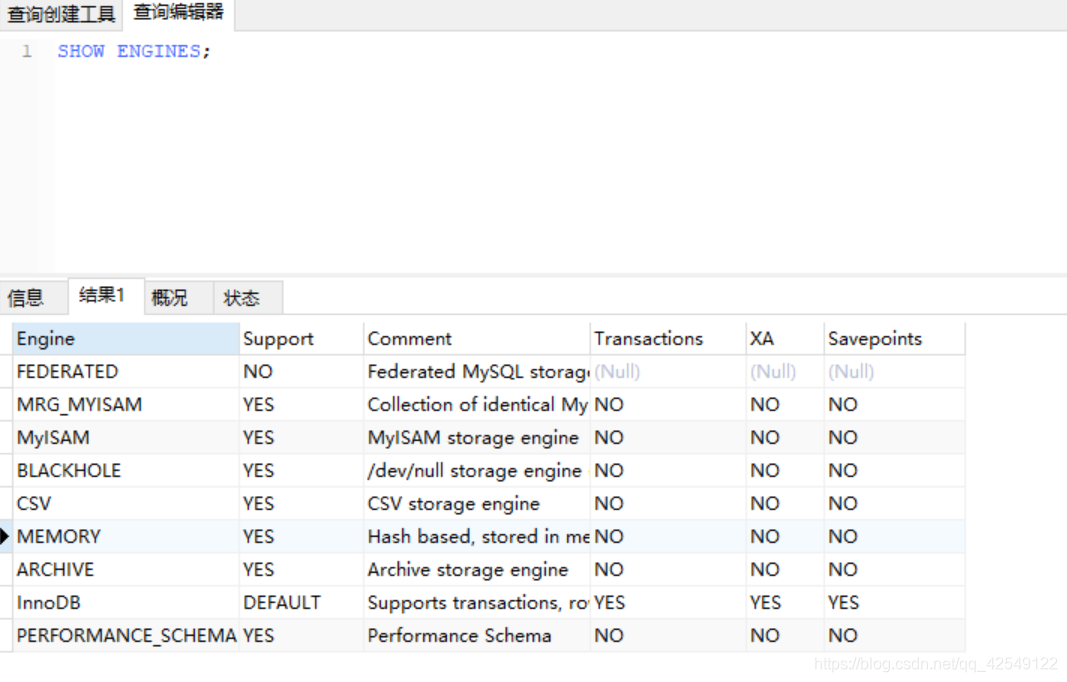
- 引擎层:

常用的是MyISAM和InnoDB,可以用SHOW ENGINES;查询出当前数据库支持了多少引擎
(1) MyISAM引擎
MyISAM表是如何储存的?
首先创建一个MyISAM引擎的表
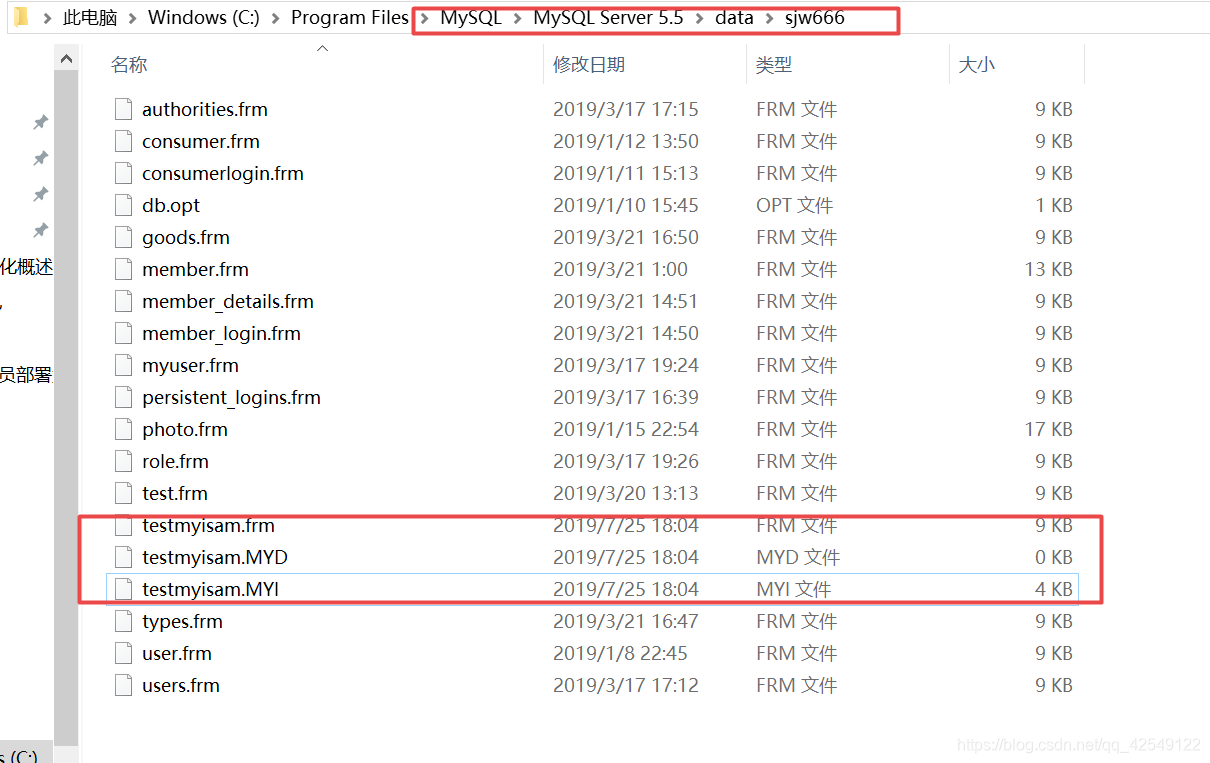
进入MySQL数据储存目录,我们发现MyISAM的储存,一张表是由三个格式组成的,frm MYD MYI。frm(数据库表结构文件,任何引擎都具备的) MYD(数据库文件) MYI(索引文件)
所以MyISAM引擎的文件也叫非聚集索引文件
MyISAM引擎的特性?
- 并发性与锁级别-表级锁
- 支持全文检索
- 支持数据压缩
支持数据压缩是MyISAM的显著特点,那么如何进行文件的压缩呢?
在MYSQL文件的bin目录下有myisampack,用其敲压缩命令来压缩
MyISAM引擎适用的场景
(1) 非事务型应用(数据仓库,报表,日志文件)
因为MyISAM引擎是不支持事务运行的
(2)只读类应用
MyISAM的读取速度是比InnoDB快的
(3)空间类的应用(空间函数,坐标,GIS应用)
经纬度的转换等InnoDB是不支持的
(2)InnoDB引擎
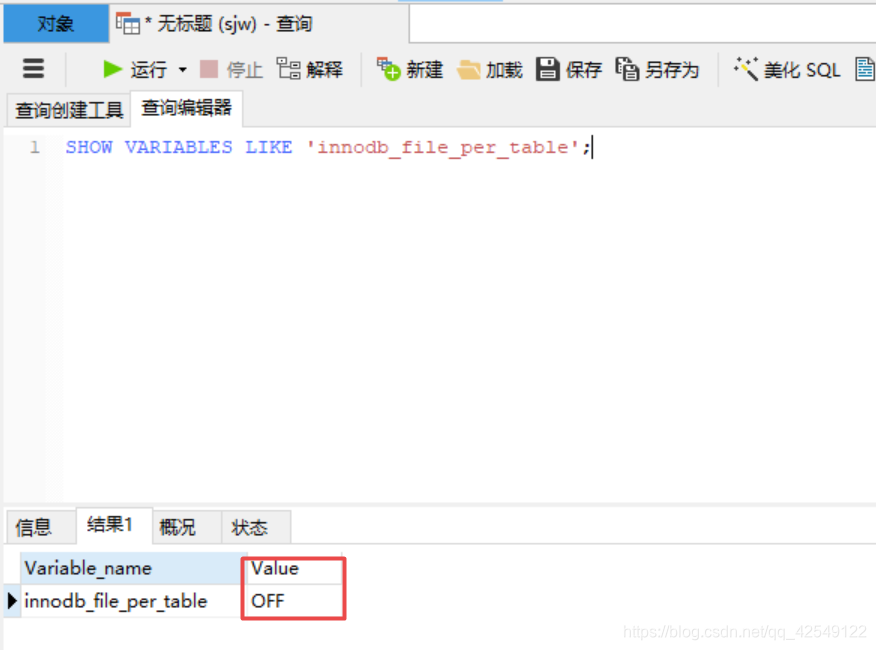
InnoDB引擎是MySql5.5版本以后默认的引擎,他的储存格式分为两种,一种是系统表空间,一种是独立表空间。
当变量innodb_file_per_table值为ON是独立表空间,OFF是系统表空间,5.6以后默认的是ON
我们也可以通过SQL语句进行修改,SET GLOBAL innodb_file_per_table=ON;
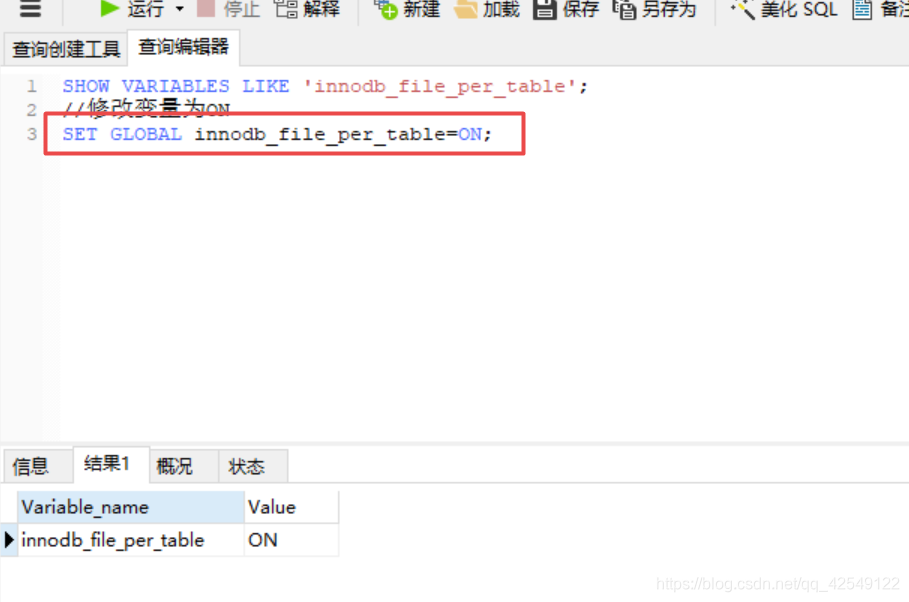
独立表空间的储存是分为两张表的,和idb。ifm储存表结构,idb储存数据和索引。
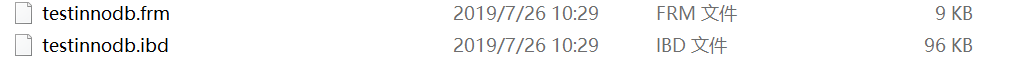
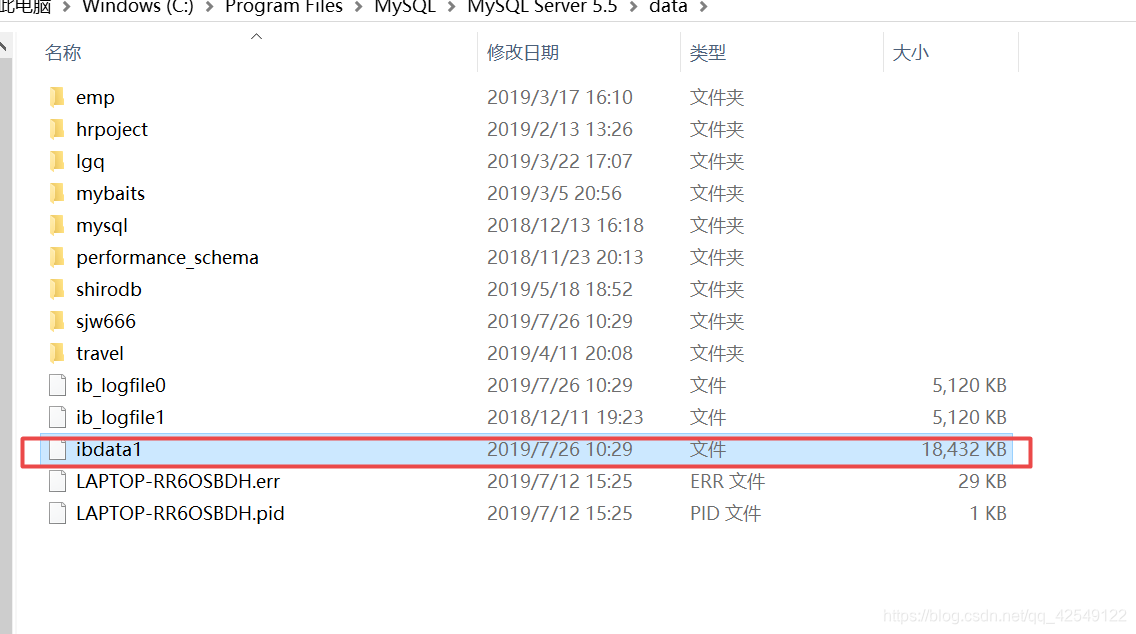
系统表空间只存在一张frm,它的数据和索引都是储存在系统的一个文件里(ibadateX)

独立表空间有什么优势呢?
1.可以收缩
系统表空间是不可以进行收缩的,但是独立表空间是可以收缩的,收缩类似于磁盘的整理,假设一张表储存了2000万条数据,占内存为1000k,你删除了这2000万条数据,表的占内存还是1000k,但是你收缩一下,它可能就是1k,收缩的功能类似于磁盘的整理
SQL命令:OPTIMIZE TABLE tablename;
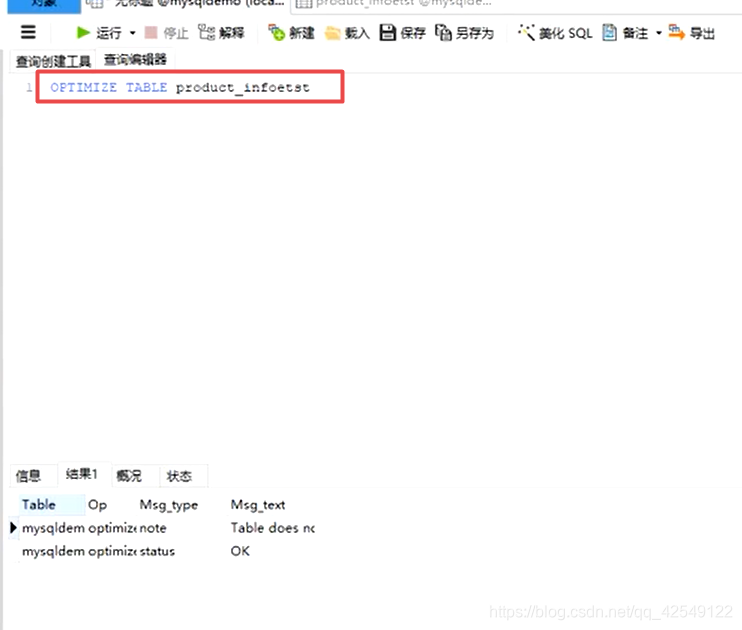
系统表空间因为所有表的数据和索引都储存在一张系统表呢,所以会产生IO瓶颈
每个独立表都会自己独立的储存表空间,所以,独立表空间可以同时向多个文件刷新数据
InnoDB引擎的特性
- 是一个事务储存引擎
- 完全支持事务的ACID特性
- Redo log和Undo log
- InnoDB支持行级锁(并发程度更高)
适用场景:适合大多数OLTP(联机应用)应用。
(3)CSV引擎
CSV引擎的储存,常常是三个文件 CSM(文件的元数据如:表状态和数据量) CSV(文件储存的数据) frm(数据表结构)

CSV引擎特征
- 以CSV格式储存
- 所有列不能为空
- 不支持索引(不适合大表储存,不适合在线处理)
- 可以对数据文件直接编辑(保留文本内容,需要 flush tables 并且需要在新加的数据后面敲换行符)
(4)Archive引擎
Archive的储存是两个文件,ARZ(保存数据),frm(保存表结构)。

Archive引擎的特征
- 以Zlib对数据表进行压缩,磁盘I/O更少,将数据储存在ARZ文件
- 只支持Insert和select操作,没有删除操作,不能删除插入成功的数据
- 只允许在自增列建索引
使用场景:日志的储存,和数据采集
(5)Memory引擎
Memory引擎的文件只有frm,其所有数据都存储于内存中,除表定义信息有对应的实体文件存储于磁盘上外,只要mysqld服务不存在,则表中的数据全部丢失。

临时表和Memory都是存入内存中,它俩的区别在于临时表是会话级别的。

Memory引擎的特征
- 也称为HEAP储存引擎,数据保存在内存中
- 支持HASH索引和BTree索引
- 所有字段都是固定长度 varchar(10)=char(10),所以,varchar和char储存的限定长度是一样的,并且即便里面没有存到最大长度也以最大长度计算所占空间
- 不支持BLOG和Test等大字段,如果建表里面包含大字段是不会成功的
- 使用表级锁
- 最大储存大小由 max_heap_table_size参数决定
(6).Ferderated引擎
Ferderated的特征
- 本地不储存数据,所以数据都储存在远程服务器上
- 本地只保留表结构,和与远程服务器连接的信息
Ferderated默认是不支持的,如果需要打开,在MySQL文档的配置文件my.ini加入federated=1
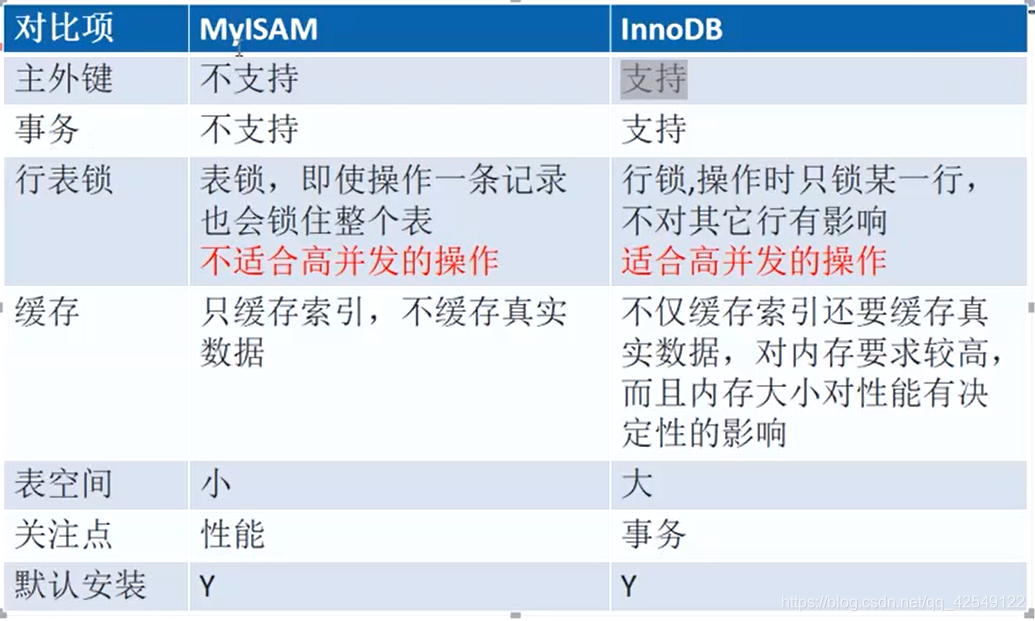
3.InnoDB和MyISAM引擎的对比