C语言深度学习之基本数据类型
关于定义命名变量问题
- 命名时最好根据变量用途联想定义变量名。
- 标识符名在标准中允许更长,但是编译器一般只识别前63个字符,超过63个字符之后的字符可能无法识别,所以两个变量名如果都超过63个字符,且前63个字符一样,编译器可能会报错。
- 在命名变量时允许使用小写字母,大写字母,数字和下划线。并且名称的第一个字符只能是字符或者下划线,不能为数字。
- 操作系统和C库经常使用以一个或两个下划线字符开始的标识符(如, -kcab),因此最好避免在自己的程序中使用这种名称。标准标签都以一个或两个下划线字符开始,如库标识符。这样的标识符都是保留的。这意味着,虽然使用它们没有语法错误,但是会导致名称冲突。
- C语言的名称区分大小写,即把一个字母的大写和小写视为两个不同的字符。因此, stars和Stars、STARS都不同。
关于赋值需要理解的地方
C语言是通过赋值运算符而不是赋值语句完成赋值操作。根据C标准, C语言并没有所谓的“赋值语句”。
return语句
在c语言中return语句为一种跳转语句。
提高程序可读性的技巧
- 选择有意义的函数名和写注释。注意,使用这两种技巧时应相得益彰,避免重复啰嗦。如果变量名是width,就不必写注释说明该变量表示宽度,但是如果变量名是video_routine-4,就要解释一下该变量名的含义。
- 在函数中用空行分隔概念上的多个部分。例如,用空行把声明部分和程序的其他部分区分开来。C语言并未规定一定要使用空行,但是多使用空行能提高程序的可读性。
- 每条语句各占一行,尽管C语言比较自由,没有要求必须代码写在不同行或者非要在一行,但是很明显一行语句占一行空间会更加好看舒适。
编译器问题
报错的位置比真正的错误位置滞后一行。例如,编译器在编译下一行时才会发现上一行缺少分号。因此,如果编译器报错某行缺少分号,请检查上一行。
语义错误和语法错误
- 如果不遵循C语言的规则就会犯语法错误,类似于英语中的语法错误;而语义错误是因为编程者没有正确理解需求而导致语句错误,无法得到想要的结果。这种情况程序可以正常运行,因为编译器不清楚你的意图,也没有语法错误。就需要自行寻找错误。
- 定位语义错误的一种方法是:在程序中的关键点插入额外的printf ()语句,以监视制定变量值的变化。通过查看值的变化可以了解程序的执行情况。对程序的执行满意后,便可删除额外的print ()语句,然后重新编译。当然调试器才是主要调试工具。
关键字是C语言的词汇
所以在进行变量命名时,需要注意不要和关键字或者保留标识符重合。
变量输出问题
在printf语句中使用%f来处理浮点值,%.2f中的.2用于精确控制输出,指定输出的浮点数只保留小数点后两位小数。
%m.nf意义:
1、f表示输出的数据是浮点数;
2、n表示输出的数据保留小数点后n为小数,第n+1位四舍五入,若不足n位则补0;
3、m表示输出数据在终端设备上占有m个字符,并右对齐,如果实际的位数小于m时,左边用空格补足,如果实际位数大于7时,向右扩展输出。
比如:
printf("%4f\n",123.4);
printf("%2f\n",123.4);
printf("%.4f\n",123.4);
输出结果为:
123.4
123.4
123.4000
注意:
1、当m值为0时,代表不限制输出宽度。原则上m>n,如果m<n,则为非法。
2、当显示为%-.2f时,表示左对齐。
3、%2f是把float的所有位数输出2位,包括小数点,如果不足2位,补0,如果超过2位,按照实际输出。
字节,字,位的含义及关系
- 位:在计算机中,数据的最小单位是位,位是指一位二进制数,英文名称是bit。
- 字节:8个二进制位构成1个字节(B),1个字节可以储存1个英文字母或半个汉字。字节是存储空间的基本计量单位,计算机杨的内存和磁盘的容量都是以字节表示的。
- 字:不同计算机系统中字长的整数倍.
- 字长:电脑技术中对CPU在单位时间内(同一时间)能一次处理的二进制数的位数叫字长。
浮点数注意事项
- 浮点数与数学中实数的概念差不多。2.75、 3.16E7、7.00和2e-8都是浮点数。注意,在一个值后面加
上一个小数点,该值就成为一个浮点值。所以, 7是整数, 7.00是浮点数。显然,书写浮点数有多种形式。
简要概述e记数法: 3.16E7表示3.16×107 (3.16乘以10的7次方)。其中,107=10000000, 7被称为10的指数。这里关键要理解浮点数和整数的储存方案不同。计算机把浮点数分成小数部分和指数部分来表示,而
且分开储存这两部分。因此,虽然7.00和7在数值上相同,但是它们的储存方式不同。在十进制下,可以
把7.0写成0.7E1。这里, 0.7是小数部分, 1是指数部分。当然,计算机在内部使用二进制和2的幂进行储存,而不是10的幂。 - 整数没有小数部分,而浮点数有小数部分。
- 浮点数可以表示的数比整数范围大。
- 对于一些算数运算(如两个很大的数相加减),浮点度损失的精度更高。
- 因为在任何区间内(如, 1.0到2.0之间)都存在无穷多个实数,所以计算机的浮点数不能表示区间内所有的值。浮点数通常只是实际值的近似值。例如, 7.0可能被储存为浮点值6.9999,指后会讨论更多精度方面的内容。
- 过去,浮点运算比整数运算慢。不过,现在许多CPU都包含浮点处理器,缩小了速度上的差距。
显示八进制和十六进制
在C程序中,既可以使用和显示不同进制的数。不同的进制要使用不同的转换说明。0x或0X来表示十六进制数,0前缀表示八进制数。以十进制显示数字,使用%d;以八进制显示数字,使用%o;以十六进制显示数字,使用%x。另外,要显示各进制数的前缀0、Ox和0x,必须分别使用%#0、%#x、%#X。
整数类型所占位数
现在,个人计算机上最常见的设置是, long long占64位, long占32位, short占16位, int
占16位或32位(依计算机的自然字长而定),原则上,这4种类型代表4种不同的大小,但是在实际使用
中,有些类型之间通常有重叠。
选择依据:
- 如果一个数超出了int类型的取值范围,且在long类型的取值范围内时,使用long类型。然而,对于那些long占用的空间比int大的系统,使用long类型会减慢运算速度。因此,如非必要,请不要使用long类型。
- 如果在long类型和int类型占用空间相同的机器上编写代码,当确实需要32位的整数时,应使用long类型而不是int类型,以便把程序移植到16位机后仍然可以正常工作。类似地,如果确实需要64位的整数,应使用long long类型。
- 如果在int设置为32位的系统中要使用16位的值,应使用short类型以节省存储空间。通常,只有当程序使用相对于系统可用内存较大的整型数组时,才需要重点考虑节省空间的问题。使用short类型的另一个原因是,计算机中某些组件使用的硬件寄存器是16位。
- 八进制和十六进制常量被视为int类型。如果值太大,编译器会尝试使用unsigned int。如果还不够大,编译器会依次使用long, unsigned long. long long和unsigned long long类型。
- 有些情况下,需要编译器以long类型储存一个小数字。例如,编程时要显式使用IBM PC上的内存地址时。另外,一些C标准函数也要求使用long类型的值。要把一个较小的常量作为long类型对待,可以在值的末尾加上l(小写的l)或L后缀。使用L后缀更好,因为l看上去和数字1很像。因此,在int为16位、long为32位的系统中,会把7作为16位储存,把7L作为32位储存。
- 1或1后缀也可用于八进制和十六进制整数,如020L和0x101. 类似地,在支持long long类型的系统中,也可以使用11或LL后缀来表示1ong long类型的值,如3LL。另外, u或U后缀表示unsigned long long,如5u11. 10LLU,6LLU或9Ull。
整数溢出
当整数变量赋值大于所能够表示的范围,则会出现溢出的情况。具体可以定义两个整数变量int i,unsigned int j。在超过最大数值时,j将会从0重新开始;i将会从-2147483648重新开始。注意:当出现整数溢出的情况时,系统不会通知用户,所以自己得小心。
在C语言中,把一字节定义为char类型所占位数,因此无论是16位还是32位系统,都可以使用char型。
字符常量及初始化
如果要把一个字符常量赋值为A,只需定义为char str=‘A’;==注意:==在C语言中,用单引号括起来的单个字符成为字符常量。
C语言将字符常量视为int类型而非char型
现有如下代码char grade=‘B’;本来B对应的数值为66,应该储存在32位的存储单元中,但是现在可以存储在8位的存储单元里。利用字符常量这种特性,可以定义一个字符常量,‘FATE’,即把四个独立的八位ASCII码储存在一个32位存储单元。如果把之赋值给grade,则只有最后一位有效,即grade=‘E’。
常用转义字符
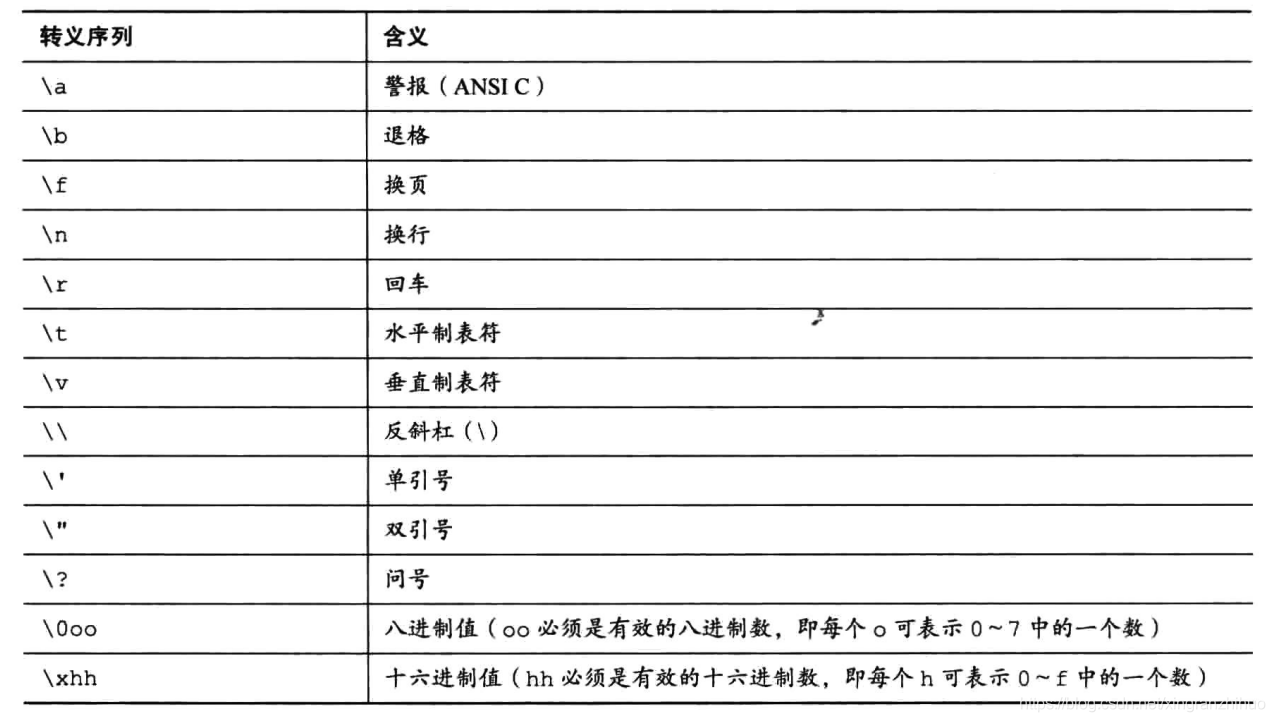
char型有无符号
根据C90标准, C语言允许在关键字char前面使用signed或unsigned。这样,无论编译器默认char是什么类型, signed char表示有符号类型,而unsigned char表示无符号类型。这在用char类型处理小整数时很有用。如果只用char处理字符,那么char前面无需使用任何修饰符。
