一,数组
数组是由固定长度并且相同类型的元素组成的序列,一个数组可以由零个或多个元素组成。
数组的每个元素可以通过索引下标来访问,索引下标的范围是从0开始到数组长度减1的位置。内置的len函数会返回数组中元素的个数。
默认情况下,数组的每个元素都被初始化为元素类型对应的零值,对于整型来说就是0。
var arr [3]int // 声明一个长度为3的整型数组
fmt.Println(arr[0]) // 打印第一个元素
fmt.Println(arr[len(arr)-1]) // 打印最后一个元素
// 打印数组的下标和对应的元素
for i, v := range arr {
fmt.Printf("%d %d\n", i, v)
}
也可以使用数组字面值语法用一组值来初始化数组:
var q [3]int = [3]int{1, 2, 3}
var r [3]int = [3]int{1, 2} // r[2] == 0
一般数组的长度必须写在前面的方括号中,如果想根据初始元素的个数自动计算长度可以在中括号中写“…”,如下:
q := [...]int{1, 2, 3}
fmt.Printf("%T\n", q) // "[3]int"
数组的长度是数组类型的一个组成部分,因此[3]int和[4]int是两种不同的数组类型。数组的长度必须是常量表达式,因为数组的长度需要在编译阶段确定。
q := [3]int{1, 2, 3}
q = [4]int{1, 2, 3, 4} // 编译错误!不能将长度为4的数组赋值给长度为3的数组
上面的形式是直接提供顺序初始化值序列,但是也可以指定一个索引和对应值列表的方式初始化,就像下面这样:
arr := [...]string{0:"星期天", 1:"星期一", 2:"星期二"}
在这种形式的数组字面值形式中,初始化索引的顺序是无关紧要的,而且没用到的索引可以省略,和前面提到的规则一样,未指定初始值的元素将用零值初始化。例如,
r := [...]int{99: -1}
定义了一个含有100个元素的数组r,最后一个元素被初始化为-1,其它元素都是用0初始化。
我们可以直接通过==比较运算符来比较两个数组,只有当两个数组的所有元素都是相等的时候数组才是相等的。不相等比较运算符!=遵循同样的规则。
a := [2]int{1, 2}
b := [...]int{1, 2}
c := [2]int{1, 3}
fmt.Println(a == b, a == c, b == c) // "true false false"
d := [3]int{1, 2}
fmt.Println(a == d) // 编译错误!数组长度不同,不能比较
函数参数传递的机制导致传递大的数组类型将是低效的,并且对数组参数的任何的修改都是发生在复制的数组上,并不能直接修改调用时原始的数组变量。在这个方面,Go语言对待数组的方式和其它很多编程语言不同,其它编程语言可能会隐式地将数组作为引用或指针对象传入被调用的函数。
当然,我们可以显式地传入一个数组指针,那样的话函数通过指针对数组的任何修改都可以直接反馈到调用者。下面的函数用于给[32]byte类型的数组清零:
func zero(ptr *[32]byte) {
for i := range ptr {
ptr[i] = 0
}
}
其实数组字面值[32]byte{}就可以生成一个32字节的数组。而且每个数组的元素都是零值初始化,也就是0。可以将上面的zero函数写的更简洁一点:
func zero(ptr *[32]byte) {
*ptr = [32]byte{}
}
虽然通过指针来传递数组参数是高效的,而且也允许在函数内部修改数组的值,但是数组依然是僵化的类型,因为数组的类型包含了僵化的长度信息。上面的zero函数并不能接收指向[16]byte类型数组的指针,而且也没有任何添加或删除数组元素的方法。由于这些原因,我们一般使用slice来替代数组。
二,Slice
Slice(切片)代表变长的序列,序列中每个元素都有相同的类型。一个slice类型一般写作[]T,其中T代表slice中元素的类型;slice的语法和数组很像,只是没有固定长度而已。
数组和slice之间有着紧密的联系,slice提供了访问数组子序列(或者全部)元素的功能,而且slice的底层确实引用一个数组对象。一个slice由三个部分构成:指针、长度和容量。指针指向第一个slice元素对应的底层数组元素的地址,要注意的是slice的第一个元素并不一定就是数组的第一个元素。长度对应slice中元素的数目;长度不能超过容量,容量一般是从slice的开始位置到底层数据的结尾位置。内置的len和cap函数分别返回slice的长度和容量。
多个slice之间可以共享底层的数据,并且引用的数组部分区间可能重叠。下图显示了表示一年中每个月份名字的字符串数组,还有重叠引用了该数组的两个slice。数组这样定义
months := [...]string{1: "January", /* ... */, 12: "December"}
因此一月份是months[1],十二月份是months[12]。通常,数组的第一个元素从索引0开始,但是月份一般是从1开始的,因此我们声明数组时直接跳过第0个元素,第0个元素会被自动初始化为空字符串。
slice的切片操作s[i:j],其中0 ≤ i≤ j≤ cap(s),用于创建一个新的slice,引用s的从第i个元素开始到第j-1个元素的子序列。新的slice将只有j-i个元素。如果i位置的索引被省略的话将使用0代替,如果j位置的索引被省略的话将使用len(s)代替。因此,months[1:13]切片操作将引用全部有效的月份,和months[1:]操作等价;months[:]切片操作则是引用整个数组。让我们分别定义表示第二季度和北方夏天月份的slice,它们有重叠部分:
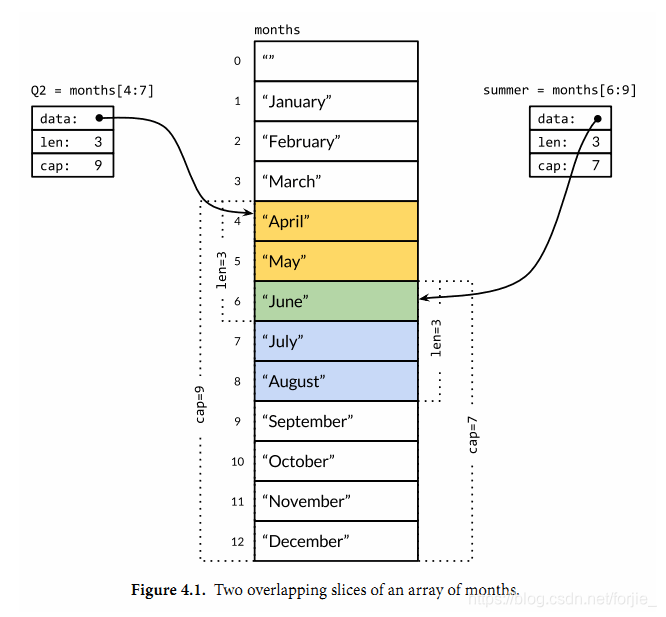
Q2 := months[4:7]
summer := months[6:9]
fmt.Println(Q2) // ["April" "May" "June"]
fmt.Println(summer) // ["June" "July" "August"]
如果切片操作超出cap(s)的上限将导致一个panic异常,但是超出len(s)则是意味着扩展了slice,因为新slice的长度会变大:
fmt.Println(summer[:20]) // panic异常:超出范围
endlessSummer := summer[:5] // 长度没有超过容量,可以扩展
fmt.Println(endlessSummer) // "[June July August September October]"
另外,字符串的切片操作和[]byte字节类型切片的切片操作是类似的。都写作x[m:n],并且都是返回一个原始字节系列的子序列,底层都是共享之前的底层数组,因此这种操作都是常量时间复杂度。x[m:n]切片操作对于字符串则生成一个新字符串,如果x是[]byte的话则生成一个新的[]byte。
因为slice值包含指向第一个slice元素的指针,因此向函数传递slice将允许在函数内部修改底层数组的元素。换句话说,复制一个slice只是对底层的数组创建了一个新的slice别名。下面的reverse函数在原内存空间将[]int类型的slice反转,而且它可以用于任意长度的slice。
// 将一个任意长度的slice里的元素翻转
func reverse(s []int) {
for i, j := 0, len(s)-1; i < j; i, j = i+1, j-1 {
s[i], s[j] = s[j], s[i]
}
}
要注意的是slice类型的变量s和数组类型的变量a的初始化语法的差异。slice和数组的字面值语法很类似,它们都是用花括弧包含一系列的初始化元素,但是对于slice并没有指明序列的长度。这会隐式地创建一个合适大小的数组,然后slice的指针指向底层的数组。就像数组字面值一样,slice的字面值也可以按顺序指定初始化值序列,或者是通过索引和元素值指定,或者的两种风格的混合语法初始化。
和数组不同的是,slice之间不能比较,因此我们不能使用==操作符来判断两个slice是否含有全部相等元素。不过标准库提供了高度优化的bytes.Equal函数来判断两个字节型slice是否相等([]byte),但是对于其他类型的slice,我们必须自己展开每个元素进行比较:
func equal(x, y []string) bool {
if len(x) != len(y) {
return false
}
for i := range x {
if x[i] != y[i] {
return false
}
}
return true
}
slice唯一合法的比较操作是和nil比较,例如:
if summer == nil { /* ... */ }
一个零值的slice等于nil。一个nil值的slice并没有底层数组。一个nil值的slice的长度和容量都是0,但是也有非nil值的slice的长度和容量也是0的,例如[]int{}或make([]int, 3)[3:]。与任意类型的nil值一样,我们可以用[]int(nil)类型转换表达式来生成一个对应类型slice的nil值。
var s []int // len(s) == 0, s == nil
s = nil // len(s) == 0, s == nil
s = []int(nil) // len(s) == 0, s == nil
s = []int{} // len(s) == 0, s != nil
如果你需要测试一个slice是否是空的,使用len(s) == 0来判断,而不应该用s == nil来判断。除了和nil相等比较外,一个nil值的slice的行为和其它任意0长度的slice一样;例如reverse(nil)也是安全的。除了文档已经明确说明的地方,所有的Go语言函数应该以相同的方式对待nil值的slice和0长度的slice。
内置的make函数创建一个指定元素类型、长度和容量的slice。容量部分可以省略,在这种情况下,容量将等于长度。
make([]T, len) // 容量等于长度
make([]T, len, cap) // 相当于 make([]T, cap)[:len]
在底层,make创建了一个匿名的数组变量,然后返回一个slice;只有通过返回的slice才能引用底层匿名的数组变量。在第一种语句中,slice是整个数组的view。在第二个语句中,slice只引用了底层数组的前len个元素,但是容量将包含整个的数组。额外的元素是留给未来的增长用的。
内置的append函数用于向slice追加元素:
var runes []rune
for _, r := range "Hello, 世界" {
runes = append(runes, r)
}
fmt.Printf("%q\n", runes) // "['H' 'e' 'l' 'l' 'o' ',' ' ' '世' '界']"
在循环中使用append函数构建一个由九个rune字符构成的slice,当然对应这个特殊的问题我们可以通过Go语言内置的[]rune(“Hello, 世界”)转换操作完成。
通常我们并不知道append调用是否导致了内存的重新分配,因此我们也不能确认新的slice和原始的slice是否引用的是相同的底层数组空间。同样,我们不能确认在原先的slice上的操作是否会影响到新的slice。因此,通常是将append返回的结果直接赋值给输入的slice变量:
runes = append(runes, r)
内置的append函数则可以追加多个元素,甚至追加一个slice。
var x []int
x = append(x, 1)
x = append(x, 2, 3)
x = append(x, 4, 5, 6)
x = append(x, x...) // append the slice x
fmt.Println(x) // "[1 2 3 4 5 6 1 2 3 4 5 6]"
内置的copy函数可以方便地将一个slice复制到另一个相同类型的slice。copy函数的第一个参数是要复制的目标slice,第二个参数是源slice,目标和源的位置顺序和dst = src赋值语句是一致的。两个slice可以共享同一个底层数组,甚至有重叠也没有问题。copy函数将返回成功复制的元素的个数(我们这里没有用到),等于两个slice中较小那一个的长度,所以我们不用担心覆盖会超出目标slice的范围。
dst := []int{1,2,3,4,5}
src := []int{6,7,8,9,10,11}
fmt.Println(copy(dst,src)) // 5
fmt.Println(dst) // [6 7 8 9 10]
fmt.Println(src) // [6 7 8 9 10 11]
有什么问题欢迎评论区留言,一起探讨!
