目录
view 视图
1、视图是查询结果的一个封装,视图中的所有数据都来自它查询的表,视图本身不存储任何数据。
2、视图能过封装复杂的查询结果,视图语法:create [or replace] view 视图名 as 查询语句 [with read only];
or replace:表示如果视图已经存在,则替换
with read only:表示视图是否只读,默认视图是可以修改的,如添加/更新/删除数据。
select * from emp;--查询员工表
create or replace view emp_view as select empno,ename,job from emp;--创建一个视图,此时它是可以修改的数据的
create or replace view emp_view_2 as select empno,ename,job from emp with read only;--创建一个视图,视图只读,无法修改数据
--查询视图,增删改查视图与表是一样的,视图就相当于封装后的表。此时只能查询指定的3列,起到了对 emp 表的封装作用
select * from emp_view;
select * from emp_view_2;
--因为视图是不存储数据的,这里对视图的修改就相当于对 emp 的修改。实际应用中应该避免视图来修改数据,让它尽量只读
update emp_view set ename='liSi' where empno = 7499;--可以修改数据
update emp_view_2 set ename='liSi2' where empno = 7499;--无法再修改数据,因为 emp_view2 只读,此时会报错。
--查询每个部门最高薪水的员工姓名,薪水,以及他所属的部门名称。
select e1.ename, e1.sal,d1.dname from emp e1,(select deptno,max(sal) as maxsal from emp group by deptno) t1,dept d1
where e1.deptno = t1.deptno and e1.sal = t1.maxsal and e1.deptno = d1.deptno;
--对于复杂的查询语句,封装成视图后,查询会看起来清爽很多
create or replace view emp_dept_v1 as
select e1.ename, e1.sal,d1.dname from emp e1,(select deptno,max(sal) as maxsal from emp group by deptno) t1,dept d1
where e1.deptno = t1.deptno and e1.sal = t1.maxsal and e1.deptno = d1.deptno
with read only;
select * from emp_dept_v1;--同样是检索各部门薪水最高的员工,通过视图转一层3、删除视图:drop view 视图名
drop view emp_view_2;--删除视图sequence 序列
1、序列是一种数据库对象,用来自动生成一组唯一的序号。序列是一种共享式的对象,多个用户可以共同使用序列中的序号。一般将序列应用于表的主键列,确保主键不会重复。
2、Sequence 创建语法:
CREATE SEQUENCE sequence_name
[START WITH num]
[INCREMENT BY increment]
[MAXVALUE num|NOMAXVALUE]
[MINVALUE num|NOMINVALUE]
[CYCLE|NOCYCLE]
[CACHE num|NOCACHE]3、语法解析
① START WITH :从某一个整数开始,升序默认值是 1 ,降序默认值是 1 。
② INCREMENT BY :增长数。如果是正数则升序生成,如果是负数则降序生成。升序默认值是 1 ,降序默认值是 1 。
③ MAXVALUE :指最大值。
④ NOMAXVALUE :这是最大值的默认选项,升序的最大值是 10的27次方 ,降序默认值是 1 。
⑤ MINVALUE :指最小值。⑥ NOMINVALUE :这是默认值选项,升序默认值是 1 ,降序默认值是 10的26 次方。
⑦ CYCLE :表示如果升序达到最大值后,从最小值重新开始;如果是降序序列,达到最小值后,从最大值重新开始。
⑧ NOCYCLE :表示不重新开始,序列升序达到最大值、降序达到最小值后就报错。默认 NOCYCLE 。
⑨ CACHE :使用 CACHE 选项时,该序列会根据序列规则 预生成一组序列号 。保留在内存中,当使用下一个序列号时,可以更快的响应。当内存中的序列号用完时,系统再生成一组新的序列号,并保存在缓存中,这样可以提高生成序列 号的效率。 Oracle默认会生产 20 个序列号 。
⑩ NOCACHE :不预先在内存中生成序列号。
4、序列创建之后,可以通过序列对象的 CURRVAL 和 NEXTVAL 两个“伪列” 分别访问该序列的当前值和下一个值。currval 必须在 nextval 调用之后才能使用。
--创建一个从 1 开始,默认最大值,每次增长 1 的序列,要求 NOCYCLE ,缓存中有 30 个预先分配好的序列号。
create sequence seq1 minvalue 1 start with 1 nomaxvalue increment by 1 nocycle cache 30;
select seq1.nextval from dual;--获取序列下一个值
select seq1.currval from dual;--获取序列当前值,必须在使用 nextval 后有了值以后才能获取当前值
create sequence seq3 ;--实际中这种使用最多,其余全部使用默认值
--为 student 插入数据,主键从 seq3 序列中获取
insert into student values(seq3 .nextval,'李四','男',22,23,sysdate,'雨花区人民中路28号',1002);
5、使用 ALTER SEQUENCE 可以修改序列,修改只影响新产生的值,不影响已产生的值,在修改序列时有如下限制:
1. 不能修改序列的初始值。
2. 最小值不能大于当前值。
3. 最大值不能小于当前值。
6、使用 "DROP SEQUENCE 序列名" 命令可以删除一个序列对象:
alter sequence seq1 cache 10;--修改序列
drop sequence seq2;--删除序列 seq2index 索引
1、索引相当于一本书的目录,能过提供检索的速度,如果某一列需要经常作为查询条件,则有必要为其创建索引,能显著提供效率。
2、索引语法:CREATE [UNIQUE] INDEX index_name ON table_name(column_name[,column_name…])
1. UNIQUE 指定索引列上的值必须是唯一的,称为唯一索引,否则就是普通索引。
2. index_name :指定索引名。
3. tabl_name :指定要为哪个表创建索引。
4. column_name :指定要对哪个列创建索引。我们也可以对多列创建索引;这种索引称为 组合索引 。
3、Oracle 数据库会为 表的主键 和 包含唯一约束的列自动创建索引。
--准备表
create table person(
pid number(32) primary key,
pname varchar2(16) not null,
paddress varchar2(16) not null
);
--使用 PLSql 语法插入 500万条数据。plsql 是 Oracle 对原生sql的封装,是 oralce 自己独有的
declare
begin
for i in 1..5000000 loop
insert into person values(i,'姓名'||i,'地址'||i);
end loop;
commit;
end;
--在没有使用索引的情况下,查询 panme='姓名4000000' 的用户 。耗时:3-5 秒
select * from person where pname = '姓名4000000';
--实际中建表后就应该设置索引,这里已经有500万条数据后再创建索引花了32秒
create index index_pname on person(pname);--为 pname 列创建索引
--为 pname 列创建索引后再次查询,耗时:0.030 ,可见有没有索引完全是云泥之别
select * from person where pname = '姓名4000000';
--在没有复合索引的情况查询 panme='姓名4000000' 且 paddress='地址4000000' 的用户,耗时:0.032
select * from person where pname = '姓名4000000' and paddress = '地址4000000';
--为 panme 、paddress 创建复合索引后再次查询。耗时:0.25 与没建复合索引区别不是很明显
create index index_pname_paddress on person(pname,paddress);--花了 46秒
select * from person where pname = '姓名4000000' and paddress = '地址3500000';
--经实测发现,pname 建了复合索引之后,select * from person where pname = '姓名4000000'; 速度更慢了Pl/SQL 工具中可以选中查询语句然后按 F5 进行查看优化目标
4、索引的原理底层使用的是平衡二叉树。数据库中索引Index )的概念与目录的概念非常类似。如果某列出现在查询的条件中
而该列的数据是无序的,查询时只能从第一行开始一行一行的匹配。 创建索引就是对某些特定列中的数据排序,生成独立的索引表。 在某列上创建索引后,如果该列出现在查询条件中,Oracle 会自动的引用该索引,先 从索引表中 查询出符合条件记录的 ROWID ,由于 ROWID 是记录的物理地址,因此可以根据 ROWID 快速的定位到具体的记录,表中的数据非常多时,引用索引带来的查询效率非常可观。
5、如果表中的某些字段经常被查询并作为查询的条件出现时,就应该考虑为该 列创建索引。当从很多行的表中查询少数行时 ,也要考虑创建索引。有一条基本的准则是:当任何单个查询要检索的行少于或者等于整个表行数的 10%时,索引就非常有用。
6、索引可以提高查询的效率,但是在数据增删改时需要更新索引,因此索引对增删改时会有负面影响。
drop index UK_ID_CART_ZZRY_XZ; --删除索引 UK_ID_CART_ZZRY_XZcursor 游标
1、游标:用于操作查询的结果集,类似 JDBC 的 ResultSet。Oralce 中的游标需要结合 PLSQL 使用。
语法:cursor 游标名[(参数名 参数类型)] is 查询结果集
开发步骤:
1)声明游标 —— cursor 游标名 is 查询结果集
2)打开游标 —— open 游标名
3)从游标中读取数据 —— fetch 游标名 into 变量
游标名%found :表示找到数据
游标名%notfound :表示没有找到数据
4)关闭游标 —— close 游标名
select * from emp;--查询员工表中所有数据
--输出/打印所有员工的姓名与薪水。
declare -- declare - begin - end 为 PLSQL 固定结构。declare 中定义变量,begin 中执行业务/逻辑操作,end 表示结束
cursor vrows is select * from emp;--1、声明游标
vrow emp%rowtype;--2、声明变量 vrow,变量类型为 emp 中的一行
begin
open vrows; --3、打开游标
loop--4、使用 loop 循环遍历游标
fetch vrows into vrow;--5、遍历游标 v rows 的每一行结果给(into)遍历 vrow
exit when vrows%notfound;--6、当游标 vrows 中没有值了,则退出循环
--dbms_output.put_line():plsql 的输出语句
dbms_output.put_line('姓名:'||vrow.ename || ' 工资:'|| vrow.sal);
end loop;
end;

select * from emp where deptno = 10;--查询指定部门下的员工
--输出/打印指定部门(deptno)下员工的姓名与薪水
declare
cursor vrows(dno number) is select * from emp where deptno = dno;--1、声明带参数的游标,参数名为 dno,参数类型为 number
vrow emp%rowtype;--2、定义变量 vrow,为 emp 行类型
begin
open vrows(10);--3、打开游标。查询 10 号部门
loop --4、遍历游标,读取数据进行处理
fetch vrows into vrow;
exit when vrows%notfound;--5、退出条件
dbms_output.put_line('姓名:'|| vrow.ename || ' 薪水:'|| vrow.sal);
end loop;
close vrows; --6、关闭游标
end;--结尾必须要有分号2、系统引用游标与上面的普通游标写法上就是第一、二步稍有不同,使用步骤:
1)声明游标:游标名 sys_refcursor
2)打开游标:open 游标名 for 查询结果集
3)从游标中读取数据 —— fetch 游标名 into 变量
游标名%found :表示找到数据
游标名%notfound :表示没有找到数据
4)关闭游标 —— close 游标名
select * from emp;--查询整个员工表
--仍然输出/打印所有员工的姓名与薪水
declare
vrows sys_refcursor;--声明系统引用游标
vrow emp%rowtype;--声明接收变量
begin
open vrows for select * from emp;--打开游标
loop--遍历游标
fetch vrows into vrow;
exit when vrows%notfound;
dbms_output.put_line('姓名:'|| vrow.ename || ' 薪水:'|| vrow.sal);
end loop;
close vrows;--必须关闭游标
end;3、除了使用 PLSQL 的 loop 循环方式,遍历游标还可以使用 for 循环,for 不再需要额外声明每次遍历接收的遍历,也不再需要手动开关游标,for 循环会自动进行处理。
select * from emp;--查询整个员工表
--仍然输出/打印所有员工的姓名与薪水。使用普通游标 加 for 循环遍历
declare
cursor vrows is select * from emp;--声明游标
begin
for vrow in vrows loop --for 循环
dbms_output.put_line('姓名:'||vrow.ename||' 薪水:'||vrow.sal);
end loop;
end;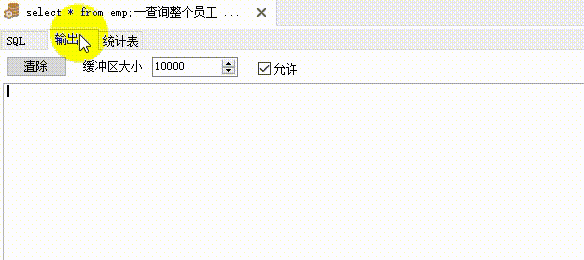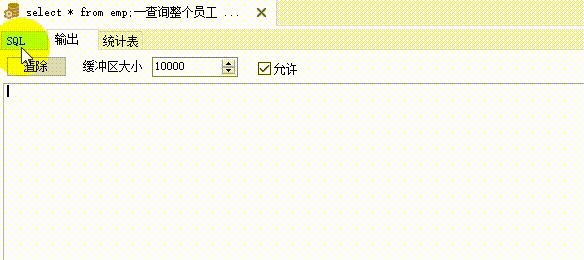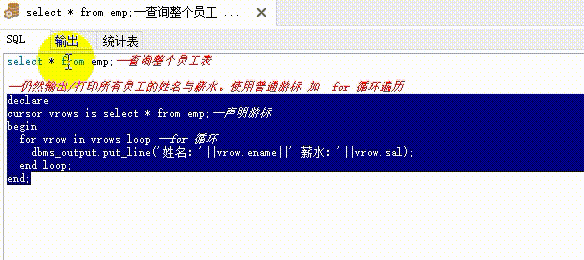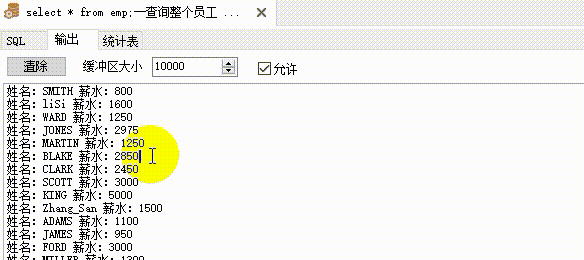
4、Oralce 的 PLSQL 因为有判断、循环等操作,就像是脚本一样,可以写成百上千上,很多业务 java 代码中的逻辑都可以放在数据库这边进行处理,游标、存储过程就是典型的操作。
select * from emp;--查询整个员工表
--给所有员工加薪,总裁加 1000,经理加600,其它人加 400
declare
cursor vrows is select * from emp;--声明游标(使用普通游标)
vrow emp%rowtype;--声明接收一行记录的变量
begin
for vrow in vrows loop--for 循环遍历游标
--根据不同的职位(job)加薪,使用 PLSQL 的 if else 判断语法
if vrow.job = 'PRESIDENT' then
update emp set sal = sal + 1000 where empno = vrow.empno;
elsif vrow.job = 'MANAGER' then
update emp set sal = sal + 600 where empno = vrow.empno;
else
update emp set sal = sal + 400 where empno = vrow.empno;
end if;--必须结束if判断
end loop;
commit;--提交事务
end;
触发器
1、触发器是一个与表关联的、存储的 PL/SQL 程序,当用户执行了 insert、update、delete 操作之后,Oracle 自动地执行触发器中定义的语句序列。
2、触发器作用:
1)数据确认:如员工涨薪后,新工资不能少于之前的工资
2)安全性检查:如禁止非工作时间插入新员工
3)做审计,跟踪表上所做的数据操作等
4)数据的备份与同步
3、触发器类型:
语句级触发器:在指定的操作语句之前或之后执行一次,不管这个语句影响了多上行记录
行级触发器:触发语句作用的每一条记录都被触发,在行级触发器中使用 old 和 new 伪记录变量,识别值的状态。
4、触发器创建语法:
create [or replace] trigger 触发器名
before/after
insert/update/delete [of 列名]
on 表名
[for each row [when(条件)]]
declare
...
begin
PLSQL块
end;
(删除触发器:DROP TRIGGER 触发器名 )
select * from emp;
--新员工入职后,输出 "欢迎加入" 字符串。创建触发器
create or replace trigger trig_show_hello
after --after 表示操作后触发
insert on emp
declare
begin
dbms_output.put_line('欢迎加入');
end;
--插入员工。插入成功后就会触发上面的 trig_show_hello 触发器
insert into emp values(9996,'华安','MANAGER','7698',sysdate,9888.87,300,30);--更新所有员工的薪水,同一加 100,创建触发器,更新完成后给出提示
create or replace trigger tric_update_sal
after update on emp
for each row --表示行级触发器
declare
begin
-- :old 表示操作前的记录行,:new 表操作后的记录行
dbms_output.put_line('原来工资:'||:old.sal|| ' 现在薪水:'||:new.sal);
end;
--更新员工薪水。自动触发上面的 tric_update_sal 触发器
update emp set sal = sal+100;
序列+触发器模拟主键自增
--模拟 mysql 中主键 id 的自增属性 auto_increment
--Oralce 中可以使用 序列 sequence 结合 触发器 trigger 达到同样的效果
--先建一张表
create table person2(
pid number(32) primary key,
pname varchar2(16)
);
create sequence person2_id_sequ;--创建一个序列。默认从1开始,每次递增1,没有最大值
--创建触发器
create or replace trigger trig_person2_add_pid
before insert on person2 --在插入数据前触发,因为需要修改 pid 的 null值
for each row --行级触发器
declare
begin
dbms_output.put_line('新增员工名称为:'||:new.pname);--打印语句,可以删除
select person2_id_sequ.nextval into :new.pid from dual;--正式插入前修改新记录的 pid 字段值
end;
--插入用户
insert into person2 values(null,'华安');--插入前触发器会自动通过序列修改 pid 的 null 值为具体的数字
insert into person2 values(2,'华安');--此时自己设置 pid 也是无效的
select * from person2;
