在默认情况下,LabVIEW的文本文件只支持ASCI的编码存取。对中文而言则取决于系统默认,如果是简体中文则为GB2312编码,繁体中文则为Big5编码。
但是某些情况下需要使用到Unicode编码的文件,如果此时直接使用LabVIEW的文本读取方式去读取,则会导致乱码,或者读取出来的只能肉眼判断,而无法用于文本截取或正则读取。
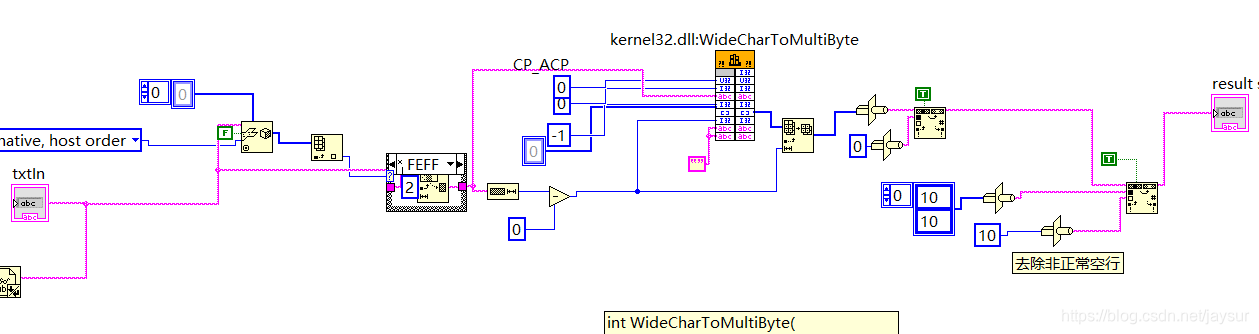
LabVIEW中没有提供各种常用文字编码之间相互转换的函数,此时可以借助外部的dll解决该问题。本例程中借用了kernel32.dll:WideCharToMultiByte来实现Unicode文本的读取。
WideCharToMultiByte
函数功能:该函数映射一个unicode字符串到一个多字节字符串。 (—Unicode转ANSI(GB2312))
int WideCharToMultiByte(
_In_ UINT CodePage,
_In_ DWORD dwFlags,
_In_ LPCWSTR lpWideCharStr,
_In_ int cchWideChar,
_Out_opt_ LPSTR lpMultiByteStr,
_In_ int cbMultiByte,
_In_opt_ LPCSTR lpDefaultChar,
_Out_opt_ LPBOOL lpUsedDefaultChar
);
在LabVIEW中,可如下构建程序:
在此,编辑了以下测试文本:

运行,可看到直观对比结果:
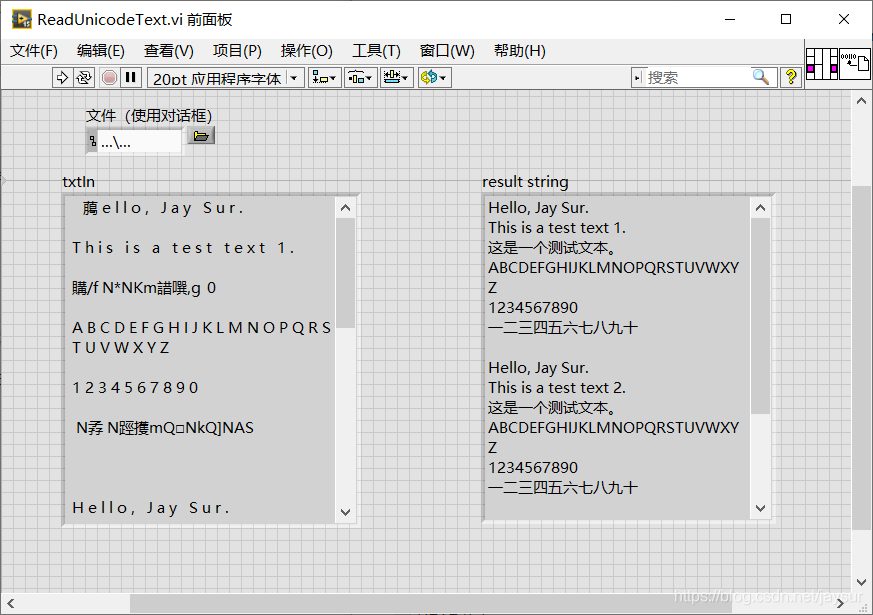
由上图可见,利用LabVIEW自带的读取文本控件读出来的都乱码了,见上图左边txtIn.经过本程序处理后,可恢复得到我们想要的结果,见上图右边Result string.
本程序源码地址:
1、GitHub:https://github.com/JaySur/Read-unicode-text-in-LabVIEW
2、CSDN花积分下载:点击直达下载页面
