1 Impala
Impala是Cloudera公司主导开发的新型查询系统,它提供SQL语义,能查询存储在Hadoop的HDFS和HBASE中的PB级大数据。已有的Hive系统虽然也提供了SQL语义,但由于Hive底层执行使用的是MapReduce引擎,仍然是一个批处理过程,难以满足查询的交互性。相比之下,Impala的最大特点也是最大卖点就是它的快速。
Impala到底是什么?
Impala是用于处理存储在Hadoop集群中的大量数据的MPP(大规模并行处理)SQL查询引擎。 它是一个用C ++和Java编写的开源软件。 与其他Hadoop的SQL引擎相比,它提供了高性能和低延迟。
换句话说,Impala是性能最高的SQL引擎(提供类似RDBMS的体验),它提供了访问存储在Hadoop分布式文件系统中的数据的最快方法。
1.1 Impala介绍
1.1.1 优点
- Impala不需要把中间结果写入磁盘,省掉了大量的I/O开销。
- 省掉了MapReduce作业启动的开销。MapReduce启动task的速度很慢(默认每个心跳间隔是3秒钟),Impala直接通过相应的服务进程来进行作业调度,速度快了很多。
- Impala完全抛弃了MapReduce这个不太适合做SQL查询的范式,而是像Dremel一样借鉴了MPP(大规模并行处理)并行数据库的思想另起炉灶,因此可做更多的查询优化,从而省掉不必要的shuffle、sort等开销。
- 通过使用LLVM来统一编译运行时代码,避免了为支持通用编译而带来的不必要开销。
- 用C++实现,做了很多有针对性的硬件优化,例如使用SSE指令。
- 使用了支持Data locality的I/O调度机制,尽可能地将数据和计算分配在同一台机器上进行,减少了网络开销。
- 基于Hive使用内存计算,兼顾数据仓库、具有实时、批处理、多并发等优点。
- 是CDH平台首选的PB级大数据实时查询分析引擎。
Impala的特点
Impala快的原因:1、2、3、6
1.基于内存进行计算,能够对PB级数据进行交互式实时查询、分析。
2.无需转换为MR,直接读取HDFS及Hbase数据,从而大大降低了延迟。
Impala没有MapReduce批处理,而是通过使用与商用并行关系数据库中类似的分布式查询引擎(由Query Planner、Query Coordinator和Query Exec Engine三部分组成)
3.LLVM统一编译运行(在底层对硬件进行优化,LLVM:编译器,比较稳定,效率高)
4.兼容HiveSQL
支持hive基本的一些查询等,hive中的一些复杂结构是不支持的。
5.具有数据仓库的特征,可对hive数据直接做数据分析。
6.支持Data Local (数据本地化:无需数据移动,减少数据的传输)
7.支持列式存储(可以和Hbase整合:因为Hive可以和Hbase整合)
8.支持JDBC/ODBC远程访问。
1.1.2 Impala劣势
1.对内存依赖大
只在内存中计算,官方建议128G(一般64基本满足)、可优化:各个节点汇总的节点(服务器)内存选用大的,不汇总节点可小点。
2、C++编写 开源?
对java,C++可能不是很了解
3、完全依赖hive
4、实践过程中分区超过1w,性能严重下下降。
定期删除没有必要的分区,保证分区的个数不要太大。
5、稳定性不如hive
因为全在内存中计算,内存不够,会出现问题,hive内存不够,可以使用外存。
1.2 Impala的缺点
Impala不提供任何对序列化和反序列化的支持。
Impala只能读取文本文件,而不能读取自定义二进制文件。
每当新的记录/文件被添加到HDFS中的数据目录中,该表需要被刷新。
1.2.1 功能
Impala可以根据Apache许可证作为开源免费提供。
Impala支持内存中数据处理,它访问/分析存储在Hadoop数据节点上的数据,而无需数据移动。
使用类SQL查询访问数据。
Impala为HDFS中的数据提供了更快的访问。
可以将数据存储在Impala存储系统中,如Apache HBase和Amazon s3。
Impala支持各种文件格式,如LZO,序列文件,Avro,RCFile和Parquet。
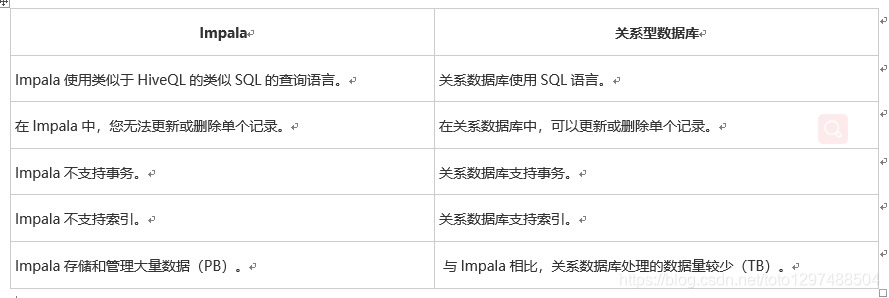
1.2.2 关系数据库和Impala
Impala使用类似于SQL和HiveQL的Query语言。 下表描述了SQL和Impala查询语言之间的一些关键差异。
1.2.3 Hive,Hbase和Impala
虽然Cloudera Impala使用与Hive相同的查询语言,元数据和用户界面,但在某些方面它与Hive和HBase不同。 下表介绍了HBase,Hive和Impala之间的比较分析。
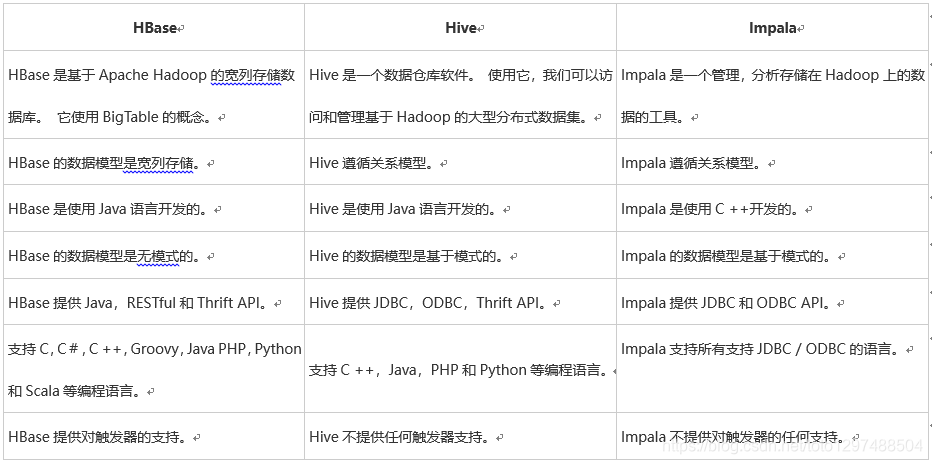
所有这三个数据库 -
• 是NOSQL数据库。
• 可用作开源。
• 支持服务器端脚本。
• 按照ACID属性,如Durability和Concurrency。
• 使用分片进行分区。
1.3 Impala架构
Impala是在Hadoop集群中的许多系统上运行的MPP(大规模并行处理)查询执行引擎。 与传统存储系统不同,impala与其存储引擎解耦。 它有三个主要组件,即Impala daemon(Impalad),Impala Statestore和Impala元数据或metastore.
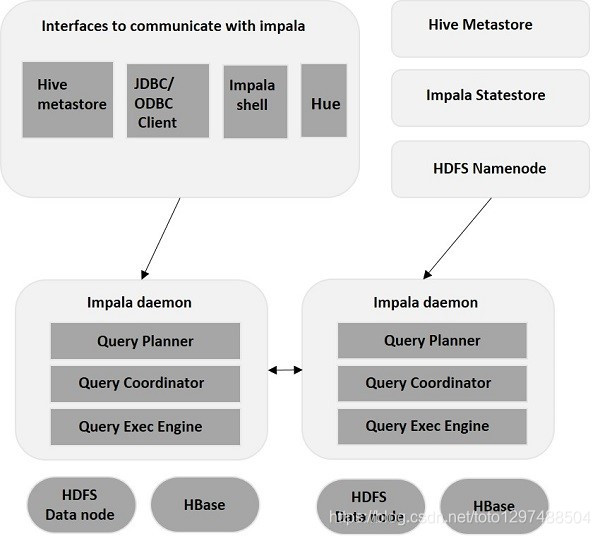
1.3.1 Impala的核心组件
Statestore Daemon
• Name Service,负责收集分布在集群中各个impalad进程的资源信息、各节点健康状况,同步节点信息。在集群中运行一个StateStroe daemon进程。多数的生产环境上将它部署在namenode节点上。
Catalog Daemon
Metadata的通信服务,用于广播impala ddl和DML语句的变更到所有的受影响的impala节点。因此新的表,新的load的数据,等等的等等通过任何Impala节点提交的查询都可以立即看到这些信息。(在Impala 1.2之前,你必须运行REFRESH 或INVALIDATE METADATA 陈述,在每个节点上同步变更的元数据信息,现在,只有通过外部机制(如Hive)或将数据上载到Amazon S3文件系统来执行DDL或DML时,才需要这些语句),在你的集群上运行有一个这样的后台进程,最好与状态守护进程位于同一主机上。
Impala Daemon(impalad)
Impala的后台进程。基于HDFS、HBASE和Amazon S3上的数据计划和执行查询。在集群上的每个DataNode节点上运行一个impalad进程。
• 接收client、hue、jdbc或者odbc的各种接口的查询、Query执行并返回给中心协调节点。
• 子节点上的守护进程,负责向statestore保持通信,汇报工作。
每当将查询提交到特定节点上的impalad时,该节点充当该查询的“协调器节点”。 Impalad还在其他节点上运行多个查询。 接受查询后,Impalad读取和写入数据文件,并通过将工作分发到Impala集群中的其他Impala节点来并行化查询。 当查询处理各种Impalad实例时,所有查询都将结果返回到中央协调节点。
根据需要,可以将查询提交到专用Impalad或以负载平衡方式提交到集群中的另一Impalad。
impala-shell:
命令行接口,用于向Impala守护进程发出查询。您可以在网络上的任何地方的一台或多台主机上安装此功能,不一定是datanode,甚至与Impala在同一个集群中。它可以远程连接到Impala守护进程的任何实例。
考虑集群性能问题,一般将StateStoreDaemon与 Catalog Daemon放在统一节点上,因之间要做通信。
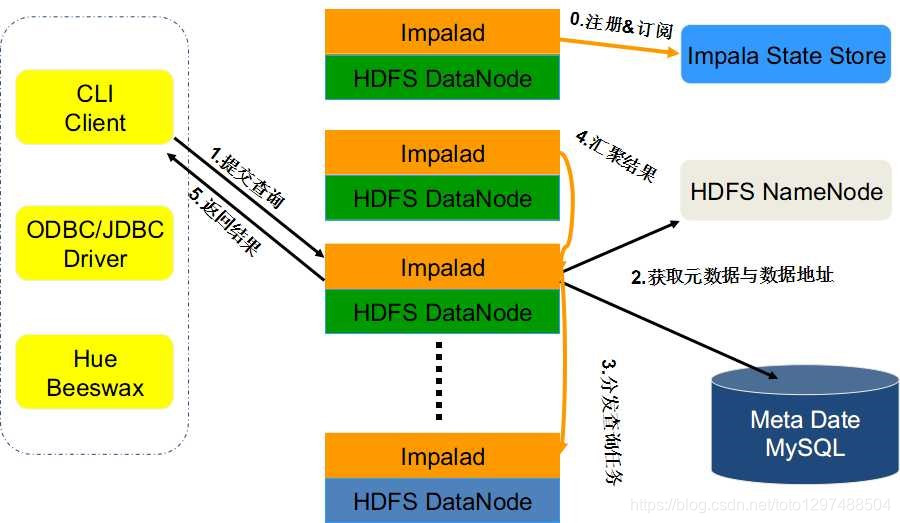
1.3.2 整体架构流程
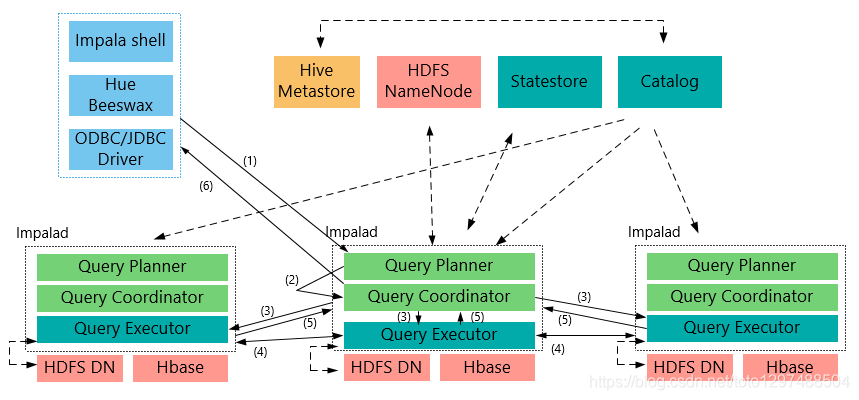
1:客户端向某一个Impalad发送一个query(SQL)
Impalad会与StateStore保持连接(通信),确定Impala集群哪些Impalad是否健康可工作,与NameNode得到数据元数据(数据的位置等);每个Impalad通过Catalog可知表元数据数据信息。
2: Impalad将query解析为具体的执行计划Planner, 交给当前机器Coordinator即为中心协调节点。
Impalad通过jni,将query传送给java前端,由java前端完成语法分析和生成执行计划(Planner),并将执行计划封装成thrift格式返回,执行计划分为多个阶段,每一个阶段叫做一个(计划片段)PlanFragment,每一个PlanFragment在执行时可以由多个Impalad实例并行执行(有些PlanFragmeng只能由一个Impalad实例执行)。
3.Coordinator(中心协调节点)根据执行计划Planner,通过本机Executor执行,并转发给其它有数据的impalad用Executor进行执行。
4.impalad的Executor之间可进行通信,可能需要一些数据的处理。
5.各个impalad的Executor执行完成后,将结果返回给中心协调节点。
用户调用GetNext()方法获取计算结果,如果是insert语句,则将计算结果写回hdfs
当所有输入数据被消耗光,执行结束(完成)。
在执行过程中,如果有任何故障发生,则整个执行失败。
6.有中心节点Coordinator将汇聚的查询结果返回给客户端。
1.3.3 Impala与Hive的异同
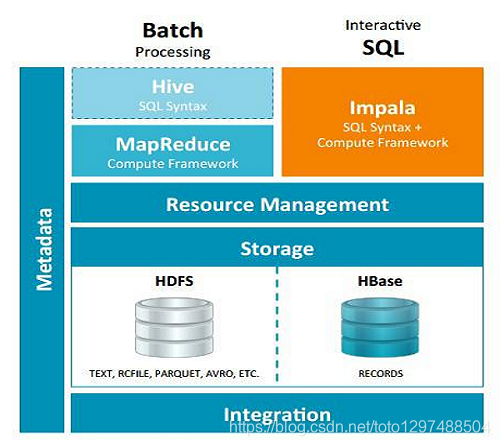
数据存储:
使用相同的存储数据池都支持把数据存储于HDFS, HBase。
元数据:
两者使用相同的元数据。
SQL解释处理:
比较相似都是通过词法分析生成执行计划。
执行计划:
Hive: 依赖于MapReduce执行框架,执行计划分成 map->shuffle->reduce->map->shuffle->reduce…的模型。如果一个Query会 被编译成多轮MapReduce,则会有更多的写中间结果。由于MapReduce执行框架本身的特点,过多的中间过程会增加整个Query的执行时间。
Impala: 把执行计划表现为一棵完整的执行计划树,可以更自然地分发执行计划到各个Impalad执行查询,而不用像Hive那样把它组合成管道型的 map->reduce模式,以此保证Impala有更好的并发性和避免不必要的中间sort与shuffle。
数据流:
• Hive: 采用推的方式,每一个计算节点计算完成后将数据主动推给后续节点。
• Impala: 采用拉的方式,后续节点通过getNext主动向前面节点要数据,以此方式数据可以流式的返回给客户端,且只要有1条数据被处理完,就可以立即展现出来,而不用等到全部处理完成,更符合SQL交互式查询使用。
内存使用:
• Hive: 在执行过程中如果内存放不下所有数据,则会使用外存,以保证Query能顺序执行完。每一轮MapReduce结束,中间结果也会写入HDFS中,同样由于MapReduce执行架构的特性,shuffle过程也会有写本地磁盘的操作。
• Impala: 在遇到内存放不下数据时,当前版本1.0.1是直接返回错误,而不会利用外存,以后版本应该会进行改进。这使用得Impala目前处理Query会受到一 定的限制,最好还是与Hive配合使用。Impala在多个阶段之间利用网络传输数据,在执行过程不会有写磁盘的操作(insert除外)
调度
• Hive任务的调度依赖于Hadoop的调度策略。
• Impala的调度由自己完成,目前的调度算法会尽量满足数据的局部性,即扫描数据的进程应尽量靠近数据本身所在的物理机器。但目前调度暂时还没有考虑负载均衡的问题。从Cloudera的资料看,Impala程序的瓶颈是网络IO,目前Impala中已经存在对Impalad机器网络吞吐进行统计,但目前还没有利用统计结果进行调度。
容错
• Hive任务依赖于Hadoop框架的容错能力,可以做到很好的failover
• Impala中不存在任何容错逻辑,如果执行过程中发生故障,则直接返回错误。当一个Impalad失败时,在这个Impalad上正在运行的所有query都将失败。但由于Impalad是对等的,用户可以向其他Impalad提交query,不影响服务。当StateStore失败时,也不会影响服务,但由于Impalad已经不能再更新集群状态,如果此时有其他Impalad失败,则无法及时发现。这样调度时,如果有一个已经失效的Impalad调度了一个任务,则整个query无法执行。
1.3.4 Impala的查询流程
1.4 Impala安装
安装CDH6,里面自带Impala,CDH6的参考文档:https://blog.csdn.net/tototuzuoquan/article/details/85111018
安装后的效果:
1.5 Impala Shell
1.5.1 Impala shell外部shell
命令
Impala shell的命令分为一般命令,查询特定选项以及表和数据库特定选项,如下所述。
通用命令
• help
• version
• history
• shell (or) !
• connect
• exit | quit
查询特定的选项
• Set/unset
• Profile
• Explain
表和数据库特定选项
• Alter
• describe
• drop
• insert
• select
• show
• use
基本数据类型
| Sr.No | 数据类型及说明 |
|---|---|
| 1 | BIGINT 此数据类型存储数值,此数据类型的范围为-9223372036854775808至9223372036854775807.此数据类型在create table和alter table语句中使用。 |
| 2 | BOOLEAN 此数据类型只存储true或false值,它用于create table语句的列定义。 |
| 3 | CHAR 此数据类型是固定长度的存储,它用空格填充,可以存储最大长度为255。 |
| 4 | DECIMAL 此数据类型用于存储十进制值,并在create table和alter table语句中使用。 |
| 5 | DOUBLE 此数据类型用于存储正值或负值4.94065645841246544e-324d -1.79769313486231570e + 308范围内的浮点值。 |
| 6 | ** FLOAT ** 此数据类型用于存储正或负1.40129846432481707e-45 … 3.40282346638528860e + 38范围内的单精度浮点值数据类型。 |
| 7 | ** INT ** 此数据类型用于存储4字节整数,范围从-2147483648到2147483647。 |
| 8 | ** SMALLINT ** 此数据类型用于存储2字节整数,范围为-32768到32767。 |
| 9 | ** STRING ** 这用于存储字符串值。 |
| 10 | ** TIMESTAMP ** 此数据类型用于表示时间中的点。 |
| 11 | ** TINYINT ** 此数据类型用于存储1字节整数值,范围为-128到127。 |
| 12 | ** VARCHAR ** 此数据类型用于存储可变长度字符,最大长度为65,535。 |
| 13 | ** ARRAY ** 这是一个复杂的数据类型,它用于存储可变数量的有序元素。 |
| 14 | ** Map ** 这是一个复杂的数据类型,它用于存储可变数量的键值对。 |
| 15 | ** Struct ** 这是一种复杂的数据类型,用于表示单个项目的多个字段。 |
Impla-shell相关参数
下面是Impala的外部Shell的一些参数:
-h (--help) 帮助
-v (--version) 查询版本信息
-V (--verbose) 启用详细输出
--quiet 关闭详细输出
-p 显示执行计划
-i hostname (--impalad=hostname) 指定连接主机格式hostname:port 默认端口21000, impalad shell 默认连接本机impalad
- r(--refresh_after_connect)刷新所有元数据
-q query (--query=query) 从命令行执行查询,不进入impala-shell
-d default_db (--database=default_db) 指定数据库
-B(--delimited)去格式化输出
--output_delimiter=character 指定分隔符
--print_header 打印列名
-f query_file(--query_file=query_file)执行查询文件,以分号分隔
-o filename (--output_file filename) 结果输出到指定文件
-c 查询执行失败时继续执行
-k (--kerberos) 使用kerberos安全加密方式运行impala-shell
-l 启用LDAP认证
-u 启用LDAP时,指定用户名
示例:
编写外部sql文件outersql.sql,文件内容如下:
[root@hadoop2 impala]# cat outersql.sql
use default;
select * from tab2;
通过impala-shell执行外部sql文件:
[root@hadoop2 impala]# impala-shell -i hadoop2 -f outersql.sql
Starting Impala Shell without Kerberos authentication
Connected to hadoop2:21000
Server version: impalad version 3.0.0-cdh6.0.1 RELEASE (build 9a74a5053de5f7b8dd983802e6d75e58d31472db)
Query: use default
Query: select * from tab2
Query submitted at: 2019-09-16 10:01:29 (Coordinator: http://hadoop2:25000)
Query progress can be monitored at: http://hadoop2:25000/query_plan?query_id=58415ef715ff66dc:7f6bd85600000000
+----+-------+---------------+
| id | col_1 | col_2 |
+----+-------+---------------+
| 1 | true | 12789.123 |
| 2 | false | 1243.5 |
| 3 | false | 24453.325 |
| 4 | false | 2423.3254 |
| 5 | true | 243.325 |
| 60 | false | 243565423.325 |
| 70 | true | 243.325 |
| 80 | false | 243423.325 |
| 90 | true | 243.325 |
+----+-------+---------------+
Fetched 9 row(s) in 4.67s
在如直接在impala-shell的后面执行sql语句:
[root@hadoop2 impala]# impala-shell -i hadoop2 -q 'select count(0) from tab2';
Starting Impala Shell without Kerberos authentication
Connected to hadoop2:21000
Server version: impalad version 3.0.0-cdh6.0.1 RELEASE (build 9a74a5053de5f7b8dd983802e6d75e58d31472db)
Query: select count(0) from tab2
Query submitted at: 2019-09-16 10:21:36 (Coordinator: http://hadoop2:25000)
Query progress can be monitored at: http://hadoop2:25000/query_plan?query_id=60409a284c3015ac:5892e5bc00000000
+----------+
| count(0) |
+----------+
| 9 |
+----------+
Fetched 1 row(s) in 0.12s
[root@hadoop2 impala]#
1.5.2 Impala内部shell
不进入Impala内部,直接执行的impala-shell
例如:
[root@hadoop2 ~]# impala-shell -i hadoop3 --quiet -- 通过外部Shell查看Impala帮助
[hadoop3:21000] default>
[hadoop3:21000] default> select version();
+-----------------------------------------------------------------------------------------+
| version() |
+-----------------------------------------------------------------------------------------+
| impalad version 3.0.0-cdh6.0.1 RELEASE (build 9a74a5053de5f7b8dd983802e6d75e58d31472db) |
| Built on Wed Sep 19 11:27:37 PDT 2018 |
+-----------------------------------------------------------------------------------------+
[hadoop3:21000] default> show databases;
+------------------+----------------------------------------------+
| name | comment |
+------------------+----------------------------------------------+
| _impala_builtins | System database for Impala builtin functions |
| default | Default Hive database |
+------------------+----------------------------------------------+
[hadoop3:21000] default> create database test2;
+----------------------------+
| summary |
+----------------------------+
| Database has been created. |
+----------------------------+
[hadoop3:21000] default> show databases;
+------------------+----------------------------------------------+
| name | comment |
+------------------+----------------------------------------------+
| _impala_builtins | System database for Impala builtin functions |
| default | Default Hive database |
| test2 | |
+------------------+----------------------------------------------+
[hadoop3:21000] test2>
再如:
[hadoop2:21000] default> show databases;
Query: show databases
+------------------+----------------------------------------------+
| name | comment |
+------------------+----------------------------------------------+
| _impala_builtins | System database for Impala builtin functions |
| data_center | |
| default | Default Hive database |
| test2 | |
+------------------+----------------------------------------------+
Fetched 4 row(s) in 0.21s
[hadoop2:21000] default> show tables in data_center;
Query: show tables in data_center
+---------------+
| name |
+---------------+
| tb_agent_area |
| tb_shop |
+---------------+
Fetched 2 row(s) in 0.11s
[hadoop2:21000] data_center> describe tb_member_card;
Query: describe tb_member_card
+------------------+---------------+-------------------------------------------------+
| name | type | comment |
+------------------+---------------+-------------------------------------------------+
| userid | varchar(40) | 会员id |
| areacode | varchar(10) | 区域code(从tb_shop表中获取) |
| areaname | varchar(30) | 区域中文名称(从tb_shop表中获取) |
| agentid | varchar(40) | 代理商id(从tb_shop表中获取) |
| agentname | varchar(20) | 代理商中文名称(从tb_shop表中获取) |
| rootcategoryid | varchar(40) | 一级类目ID |
| parentcategoryid | varchar(40) | 二级类目ID |
| industryid | varchar(40) | 经营类目id(从tb_shop表中获取) |
| industryname | varchar(20) | 经营类目中文名称(从tb_shop表中获取) |
| cardid | varchar(40) | 会员卡号Id |
| shopid | varchar(40) | 店铺Id,主键唯一 |
| rechargefee | decimal(10,2) | 充值金额 |
| givefee | decimal(10,2) | 赠送金额 |
| usefee | decimal(10,2) | 消耗金额 |
| refundfee | decimal(10,2) | 退款金额 |
| addtime | bigint | 创建时间,也是上面充值时间,退款时间等 |
| createdate | bigint | 创建天,时间格式为yyyyMMdd的integer值,分区时间 |
| pt_createdate | int | 创建天,时间格式为yyyyMMdd的integer值,分区时间 |
+------------------+---------------+-------------------------------------------------+
Fetched 18 row(s) in 4.46s
[hadoop2:21000] data_center> desc tb_member_card;
Query: describe tb_member_card
+------------------+---------------+-------------------------------------------------+
| name | type | comment |
+------------------+---------------+-------------------------------------------------+
| userid | varchar(40) | 会员id |
| areacode | varchar(10) | 区域code(从tb_shop表中获取) |
| areaname | varchar(30) | 区域中文名称(从tb_shop表中获取) |
| agentid | varchar(40) | 代理商id(从tb_shop表中获取) |
| agentname | varchar(20) | 代理商中文名称(从tb_shop表中获取) |
| rootcategoryid | varchar(40) | 一级类目ID |
| parentcategoryid | varchar(40) | 二级类目ID |
| industryid | varchar(40) | 经营类目id(从tb_shop表中获取) |
| industryname | varchar(20) | 经营类目中文名称(从tb_shop表中获取) |
| cardid | varchar(40) | 会员卡号Id |
| shopid | varchar(40) | 店铺Id,主键唯一 |
| rechargefee | decimal(10,2) | 充值金额 |
| givefee | decimal(10,2) | 赠送金额 |
| usefee | decimal(10,2) | 消耗金额 |
| refundfee | decimal(10,2) | 退款金额 |
| addtime | bigint | 创建时间,也是上面充值时间,退款时间等 |
| createdate | bigint | 创建天,时间格式为yyyyMMdd的integer值,分区时间 |
| pt_createdate | int | 创建天,时间格式为yyyyMMdd的integer值,分区时间 |
+------------------+---------------+-------------------------------------------------+
Fetched 18 row(s) in 0.03s
[hadoop2:21000] data_center> select count(*) from tb_member_card;
Query: select count(*) from tb_member_card
Query submitted at: 2019-09-15 22:51:19 (Coordinator: http://hadoop2:25000)
Query progress can be monitored at: http://hadoop2:25000/query_plan?query_id=74a30bb25fbf783:24bf49f00000000
+----------+
| count(*) |
+----------+
| 0 |
+----------+
Fetched 1 row(s) in 0.47s
[localhost:21000] > select count(distinct c_birth_month) from customer;
+-------------------------------+
| count(distinct c_birth_month) |
+-------------------------------+
| 12 |
+-------------------------------+
[localhost:21000] > select count(*) from customer where c_email_address is null;
+----------+
| count(*) |
+----------+
| 0 |
+----------+
[localhost:21000] > select distinct c_salutation from customer limit 10;
+--------------+
| c_salutation |
+--------------+
| Mr. |
| Ms. |
| Dr. |
| |
| Miss |
| Sir |
| Mrs. |
+--------------+
[hadoop2:21000] data_center> show tables;
Connection lost, reconnecting...
Query: use `data_center`
Query: show tables
+----------------+
| name |
+----------------+
| tb_agent_area |
| tb_member_card |
| tb_shop |
+----------------+
Fetched 3 row(s) in 0.02s
[hadoop2:21000] data_center> alter table tb_shop rename to shop;
Query: alter table tb_shop rename to shop
+--------------------------+
| summary |
+--------------------------+
| Renaming was successful. |
+--------------------------+
Fetched 1 row(s) in 5.52s
[hadoop2:21000] data_center> show tables;
Query: show tables
+----------------+
| name |
+----------------+
| shop |
| tb_agent_area |
| tb_member_card |
+----------------+
Fetched 3 row(s) in 0.02s
[hadoop2:21000] data_center> create table t1(x int);
Query: create table t1(x int)
+-------------------------+
| summary |
+-------------------------+
| Table has been created. |
+-------------------------+
Fetched 1 row(s) in 0.26s
[hadoop2:21000] data_center> insert into t1 values(1),(3),(2),(4);
Query: insert into t1 values(1),(3),(2),(4)
Query submitted at: 2019-09-16 00:09:56 (Coordinator: http://hadoop2:25000)
Query progress can be monitored at: http://hadoop2:25000/query_plan?query_id=874ed9b5a0c973a6:5b9ea0fc00000000
Modified 4 row(s) in 6.52s
[hadoop2:21000] data_center> select x from t1 order by x desc;
Query: select x from t1 order by x desc
Query submitted at: 2019-09-16 00:16:10 (Coordinator: http://hadoop2:25000)
Query progress can be monitored at: http://hadoop2:25000/query_plan?query_id=ed473c678702d9aa:96ab138700000000
+---+
| x |
+---+
| 4 |
| 3 |
| 2 |
| 1 |
+---+
[hadoop2:21000] data_center> select min(x),max(x),sum(x),avg(x) from t1;
Query: select min(x),max(x),sum(x),avg(x) from t1
Query submitted at: 2019-09-16 00:21:15 (Coordinator: http://hadoop2:25000)
Query progress can be monitored at: http://hadoop2:25000/query_plan?query_id=b74aa0dc8354b2f4:843e1aad00000000
+--------+--------+--------+--------+
| min(x) | max(x) | sum(x) | avg(x) |
+--------+--------+--------+--------+
| 1 | 4 | 10 | 2.5 |
+--------+--------+--------+--------+
Fetched 1 row(s) in 0.33s
[hadoop2:21000] data_center> insert into t2 values(1,'one'),(3,'three'),(5,'five');
Query: insert into t2 values(1,'one'),(3,'three'),(5,'five')
Query submitted at: 2019-09-16 00:23:28 (Coordinator: http://hadoop2:25000)
Query progress can be monitored at: http://hadoop2:25000/query_plan?query_id=c043b83ea895c2ae:3e68fac500000000
Modified 3 row(s) in 4.99s
[hadoop2:21000] data_center> select word from t1 join t2 on(t1.x = t2.id);
Query: select word from t1 join t2 on(t1.x = t2.id)
Query submitted at: 2019-09-16 00:24:51 (Coordinator: http://hadoop2:25000)
Query progress can be monitored at: http://hadoop2:25000/query_plan?query_id=4945efba241c9e41:f6cc18d800000000
+-------+
| word |
+-------+
| one |
| three |
+-------+
Fetched 2 row(s) in 0.35s
显示表中的文件信息
[hadoop2:21000] data_center> show table stats t1;
Query: show table stats t1
+-------+--------+------+--------------+-------------------+--------+-------------------+-----------------------------------------------------------+
| #Rows | #Files | Size | Bytes Cached | Cache Replication | Format | Incremental stats | Location |
+-------+--------+------+--------------+-------------------+--------+-------------------+-----------------------------------------------------------+
| -1 | 1 | 8B | NOT CACHED | NOT CACHED | TEXT | false | hdfs://hadoop2:8020/user/hive/warehouse/data_center.db/t1 |
+-------+--------+------+--------------+-------------------+--------+-------------------+-----------------------------------------------------------+
Fetched 1 row(s) in 0.03s
[hadoop2:21000] data_center>
显示表中文件:
[hadoop2:21000] data_center> SHOW FILES IN t1;
Query: SHOW FILES IN t1
+----------------------------------------------------------------------------------------------------------------+------+-----------+
| Path | Size | Partition |
+----------------------------------------------------------------------------------------------------------------+------+-----------+
| hdfs://hadoop2:8020/user/hive/warehouse/data_center.db/t1/874ed9b5a0c973a6-5b9ea0fc00000000_1276072409_data.0. | 8B | |
+----------------------------------------------------------------------------------------------------------------+------+-----------+
Fetched 1 row(s) in 0.02s
[hadoop2:21000] data_center>
再查看表的信息:
[hadoop2:21000] data_center> DESCRIBE FORMATTED t1;
Query: describe FORMATTED t1
+------------------------------+------------------------------------------------------------+----------------------+
| name | type | comment |
+------------------------------+------------------------------------------------------------+----------------------+
| # col_name | data_type | comment |
| | NULL | NULL |
| x | int | NULL |
| | NULL | NULL |
| # Detailed Table Information | NULL | NULL |
| Database: | data_center | NULL |
| Owner: | root | NULL |
| CreateTime: | Mon Sep 16 00:09:23 CST 2019 | NULL |
| LastAccessTime: | UNKNOWN | NULL |
| Retention: | 0 | NULL |
| Location: | hdfs://hadoop2:8020/user/hive/warehouse/data_center.db/t1 | NULL |
| Table Type: | MANAGED_TABLE | NULL |
| Table Parameters: | NULL | NULL |
| | transient_lastDdlTime | 1568563763 |
| | NULL | NULL |
| # Storage Information | NULL | NULL |
| SerDe Library: | org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe | NULL |
| InputFormat: | org.apache.hadoop.mapred.TextInputFormat | NULL |
| OutputFormat: | org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat | NULL |
| Compressed: | No | NULL |
| Num Buckets: | 0 | NULL |
| Bucket Columns: | [] | NULL |
| Sort Columns: | [] | NULL |
+------------------------------+------------------------------------------------------------+----------------------+
Fetched 23 row(s) in 0.07s
[hadoop2:21000] data_center>
NDV() 方法返回不重复数据的数据条数。
[hadoop2:21000] data_center> show create table t1;
Query: show create table t1
+----------------------------------------------------------------------+
| result |
+----------------------------------------------------------------------+
| CREATE TABLE data_center.t1 ( |
| x INT |
| ) |
| STORED AS TEXTFILE |
| LOCATION 'hdfs://hadoop2:8020/user/hive/warehouse/data_center.db/t1' |
| |
+----------------------------------------------------------------------+
1.6 Load CSV Data From Local Files
这个章节介绍如何从本地文件中加载CSV 数据。在本地Linux环境中,执行以下命令:
[root@hadoop2 ~]# hdfs dfs -mkdir -p /user/username/sample_data/tab1 /user/username/ sample_data/tab2
接下来为TAB1和TAB2准备一些数据。拷贝下面的内容到你本地的.csv文件中。
tab1.csv的内容如下:
1,true,123.123,2012-10-24 08:55:00
2,false,1243.5,2012-10-25 13:40:00
3,false,24453.325,2008-08-22 09:33:21.123
4,false,243423.325,2007-05-12 22:32:21.33454
5,true,243.325,1953-04-22 09:11:33
tab2.csv的内容如下:
1,true,12789.123
2,false,1243.5
3,false,24453.325
4,false,2423.3254
5,true,243.325
60,false,243565423.325
70,true,243.325
80,false,243423.325
90,true,243.325
使用如下的命令,分别将.csv文件放到独立的HDFS目录中。
[root@hadoop2 impala]# hdfs dfs -put tab1.csv /user/username/sample_data/tab1
[root@hadoop2 impala]# hdfs dfs -ls /user/username/sample_data/tab1
Found 1 items
-rw-r--r-- 3 root supergroup 192 2019-09-16 09:08 /user/username/sample_data/tab1/tab1.csv
[root@hadoop2 impala]# hdfs dfs -put tab2.csv /user/username/sample_data/tab2
[root@hadoop2 impala]# hdfs dfs -cat /user/username/sample_data/tab2/tab2.csv
1,true,12789.123
2,false,1243.5
3,false,24453.325
4,false,2423.3254
5,true,243.325
60,false,243565423.325
70,true,243.325
80,false,243423.325
90,true,243.325
每个数据文件的名称是没有意义的。事实上,当Impala第一次检查数据目录下的文件的时候,它认为在目录下的所有文件组成了表的数据,而不是多少文件,也不管文件的名字是什么。
创建tab1表:
[hadoop2:21000] default> DROP TABLE IF EXISTS tab1;
Query: DROP TABLE IF EXISTS tab1
+-------------------------+
| summary |
+-------------------------+
| Table has been dropped. |
+-------------------------+
Fetched 1 row(s) in 0.12s
[hadoop2:21000] default> CREATE EXTERNAL TABLE tab1
> (
> id INT,
> col_1 BOOLEAN,
> col_2 DOUBLE,
> col_3 TIMESTAMP
> )
> ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
> LOCATION '/user/username/sample_data/tab1';
Query: CREATE EXTERNAL TABLE tab1
(
id INT,
col_1 BOOLEAN,
col_2 DOUBLE,
col_3 TIMESTAMP
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
LOCATION '/user/username/sample_data/tab1'
+-------------------------+
| summary |
+-------------------------+
| Table has been created. |
+-------------------------+
WARNINGS: Impala does not have READ_WRITE access to path 'hdfs://hadoop2:8020/user/username/sample_data'
Fetched 1 row(s) in 0.11s
[hadoop2:21000] default> select * from tab1;
Query: select * from tab1
Query submitted at: 2019-09-16 09:37:33 (Coordinator: http://hadoop2:25000)
Query progress can be monitored at: http://hadoop2:25000/query_plan?query_id=4f44222f65a4cbf6:a624798000000000
+----+-------+------------+-------------------------------+
| id | col_1 | col_2 | col_3 |
+----+-------+------------+-------------------------------+
| 1 | true | 123.123 | 2012-10-24 08:55:00 |
| 2 | false | 1243.5 | 2012-10-25 13:40:00 |
| 3 | false | 24453.325 | 2008-08-22 09:33:21.123000000 |
| 4 | false | 243423.325 | 2007-05-12 22:32:21.334540000 |
| 5 | true | 243.325 | 1953-04-22 09:11:33 |
+----+-------+------------+-------------------------------+
Fetched 5 row(s) in 5.93s
[hadoop2:21000] default> DROP TABLE IF EXISTS tab2;
Query: DROP TABLE IF EXISTS tab2
+-----------------------+
| summary |
+-----------------------+
| Table does not exist. |
+-----------------------+
Fetched 1 row(s) in 0.01s
[hadoop2:21000] default> CREATE EXTERNAL TABLE tab2
> (
> id INT,
> col_1 BOOLEAN,
> col_2 DOUBLE
> )
> ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
> LOCATION '/user/username/sample_data/tab2';
Query: CREATE EXTERNAL TABLE tab2
(
id INT,
col_1 BOOLEAN,
col_2 DOUBLE
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
LOCATION '/user/username/sample_data/tab2'
+-------------------------+
| summary |
+-------------------------+
| Table has been created. |
+-------------------------+
WARNINGS: Impala does not have READ_WRITE access to path 'hdfs://hadoop2:8020/user/username/sample_data'
Fetched 1 row(s) in 0.09s
[hadoop2:21000] default> DROP TABLE IF EXISTS tab3;
Query: DROP TABLE IF EXISTS tab3
+-----------------------+
| summary |
+-----------------------+
| Table does not exist. |
+-----------------------+
Fetched 1 row(s) in 0.01s
[hadoop2:21000] default> CREATE TABLE tab3
> (
> id INT,
> col_1 BOOLEAN,
> col_2 DOUBLE,
> month INT,
> day INT
> )
> ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
Query: CREATE TABLE tab3
(
id INT,
col_1 BOOLEAN,
col_2 DOUBLE,
month INT,
day INT
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
+-------------------------+
| summary |
+-------------------------+
| Table has been created. |
+-------------------------+
Fetched 1 row(s) in 0.41s
[hadoop2:21000] default>
要注意的是,上面的tab1和tab2指定了LOCATION,它的地址为最开始的时候创建的csv文件所在的目录位置。
1.7 分区表创建、refresh表、获取数据的元数据
创建分区表,并插入数据:
create database external_partitions;
use external_partitions;
create table logs (field1 string, field2 string, field3 string)
partitioned by (year string, month string , day string, host string)
row format delimited fields terminated by ',';
insert into logs partition (year="2013", month="07", day="28", host="host1") values ("foo","foo","foo");
insert into logs partition (year="2013", month="07", day="28", host="host2") values ("foo","foo","foo");
insert into logs partition (year="2013", month="07", day="29", host="host1") values ("foo","foo","foo");
insert into logs partition (year="2013", month="07", day="29", host="host2") values ("foo","foo","foo");
insert into logs partition (year="2013", month="08", day="01", host="host1") values ("foo","foo","foo");
查看hdfs中数据目录:
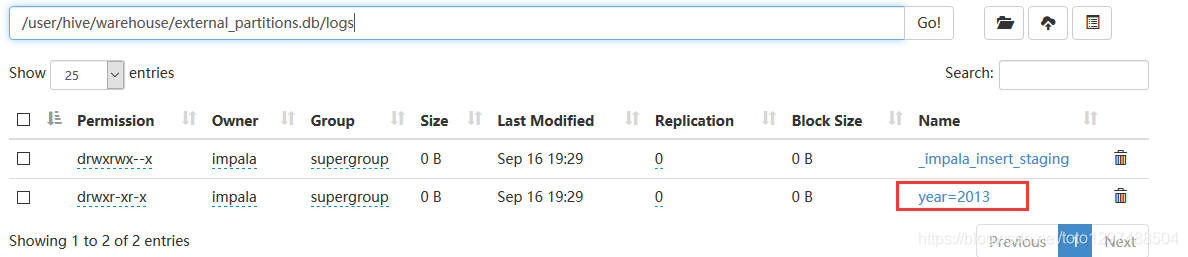


添加分区:
alter table logs add partition (year="2013",month="07",day="28",host="host1");
alter table log_type add partition (year="2013",month="07",day="28",host="host2");
alter table log_type add partition (year="2013",month="07",day="29",host="host1");
alter table log_type add partition (year="2013",month="08",day="01",host="host1");
当数据文件中的数据被手动修改(如添加、移动或者改变了)了之后,使用refresh语句更新表。例如:
refresh log_type;
select * from log_type limit 100;
+--------+--------+--------+------+-------+-----+-------+
| field1 | field2 | field3 | year | month | day | host |
+--------+--------+--------+------+-------+-----+-------+
| bar | baz | bletch | 2013 | 07 | 28 | host1 |
| bar | baz | bletch | 2013 | 08 | 01 | host1 |
| bar | baz | bletch | 2013 | 07 | 29 | host1 |
| bar | baz | bletch | 2013 | 07 | 28 | host2 |
+--------+--------+--------+------+-------+-----+-------+
在hive中创建一个db,然后切回到impala-shell中,发现数据库并没有显示,若想让它显示,可以使用如下命令刷新数据,并获得最新数据:
INVALIDATE METADATA;
1.8 参考资料
https://www.w3cschool.cn/impala/impala_overview.html
https://blog.csdn.net/flyingsk/article/details/8590000
https://blog.csdn.net/qiyongkang520/article/details/51067803
