东北农业大学2020寒假培训day4 D题思路与思考
先放题目和链接(本人蒟蒻,如有不对还请大佬轻喷,555)
传送门
有n种物品,第i个物品可以选择至少1个至多n个,但要求第i个物品的数量不大于第i+1个物品的数量,求方案种类。

先看题目,然后先思考,n=1时,只有一种情况,1,n=2时,可以是11,12,22,一共3种情况,n=3时,就是111,112,113,122,123,133,222,223,233,333,一共10种情况,想到这里,我觉得我学通了,“这不水题吗?直接按顺序排不就行了吗?”
所以我们直接写一个按顺序排的程序
直接暴力搜索dfs
#include <bits/stdc++.h>
using namespace std;
int sum=0,n,i;
int dfs(int b,int a)
{
if(b==n)
{
sum++;
return 0;
}
for(int i=a;a>=1;a--)
{
dfs(b+1,a);
}
}
int main()
{
ios::sync_with_stdio(false);cin.tie(0);cout.tie(0);
int T;
cin>>T;
while(T--)
{
sum=0;
cin>>n;
dfs(0,n);
cout<<sum<<"\n";
}
return 0;
}
很好,写完了,验证了几组数据,很棒棒,都是对的
开开心心去交代码喽
然后
你就tle了,emmmmmmmmmm
你人傻了,我这没错呀,也没跑死循环呀,
呀嘞呀嘞,不用担心,你的思路和代码的确没错,甚至答案也没错,你只是单纯的时间超了,那么我们可以做什么措施来避免tle呢?
1,改算法
先留着,等下次再说,逃
2,预处理
先分析下,这题的最多耗时是什么情况,T<=15,n<=15,哦豁,你一下就懂了,对的,就是15个15,这种时候你的程序要跑15次完整的非递减排列,时间炸了,再想想,n最多就是15????那我们直接打表呗,先预先跑一次dfs,把每一次的值都存起来,不就行了吗?
说干就干
#include <bits/stdc++.h>
using namespace std;
int num[20];
int sum=0,n,i;
int dfs(int b,int a)
{
if(b==i)
{
sum++;
return 0;
}
for(int i=a;a>=1;a--)
{
dfs(b+1,a);
}
}
int main()
{
ios::sync_with_stdio(false);cin.tie(0);cout.tie(0);
int T;
cin>>T;
for( i=1;i<=15;i++)
{
sum=0;
dfs(0,i);
num[i]=sum;
}
while(T--)
{
cin>>n;
cout<<num[n]<<"\n";
}
return 0;
}
或者这个(究极打表)
#include<stdio.h>
int a[20];
int main()
{
a[1]=1;
a[2]=3;
a[3]=10;
a[4]=35;
a[5]=126;
a[6]=462;
a[7]=1716;
a[8]=6435;
a[9]=24310;
a[10]=92378;
a[11]=352716;
a[12]=1352078;
a[13]=5200300;
a[14]=20058300;
a[15]=77558760;
int T;
scanf("%d",&T);
while(T--)
{
int n;
scanf("%d",&n);
printf("%d\n",a[n]);
}
}
那么恭喜你到现在为止,已经ac了这道题了,棒棒的!!
发散思维:那么n很大,咋办
我们继续回看这题,我们在打表之前,我们看看我们这个dfs,我们可以很轻松的发现一个问题,当n在扩大时,其实dfs有几个是必然会跑的,比如dfs(1,1),不论你n多大,你都必然会跑,那么我们在dfs跑的时候加一个输出他自己本身,来看一看

我们可以轻易的发现,不仅仅是dfs(1,1),当n=2时,dfs(2,1)跑了2次,当n=3时,dfs(3,2)跑了3次,dfs(2,2),dfs(2,1)等等,都跑了不止一次,**那么他们的值一样吗????**为了方便查看是否一样,我们稍微改动下代码
#include <bits/stdc++.h>
using namespace std;
int n,i;
int dfs(int b,int a)
{
int chuli[a+1];
memset(chuli,0,sizeof(chuli));
if(b==n)
{
return 1;
}
for(int i=a;i>=1;i--)
{
chuli[i]=dfs(b+1,i);
}
for(int i=1;i<=a;i++)
{
chuli[0]+=chuli[i];
}
return chuli[0];
}
int main()
{
ios::sync_with_stdio(false);cin.tie(0);cout.tie(0);
int T;
cin>>T;
while(T--)
{
cin>>n;
cout<<dfs(0,n)<<"\n";
}
return 0;
}
在这次的代码里,我们去掉了sum作为外部变量,现在我们的程序已经不依赖任何外部变量了!!!!
ok ok 趁现在,我们看下dfs(x,y)都是多少吧
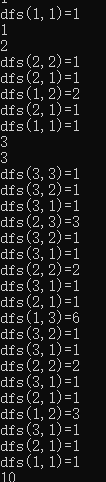
震惊!!!!对于相同的dfs(x,y),他的值!!!居然是完全相同的,道理也很简单,我们现在的dfs已经不依赖任何外部变量了,自然每次都一样,所以!!!!我们可以开一个数组mem,记录每一次dfs(x,y)的返回值,一开始全设为 -1 (未访问),每次进入dfs前,先看看mem对应的值是否为 -1,是的话就正常跑dfs,假如不是 -1 呢???
那就直接返回mem中的值!!!!!!!!!!!!!!!!
那么看代码
#include <bits/stdc++.h>
using namespace std;
int n,i;
int mem[20][20];
int dfs(int b,int a)
{
if(mem[b][a]!=-1)
return mem[b][a];
int chuli[a+1];
memset(chuli,0,sizeof(chuli));
if(b==n)
{
return 1;
}
for(int i=a;i>=1;i--)
{
chuli[i]=dfs(b+1,i);
}
for(int i=1;i<=a;i++)
{
chuli[0]+=chuli[i];
}
return chuli[0];
}
int main()
{
ios::sync_with_stdio(false);cin.tie(0);cout.tie(0);
int T;
cin>>T;
while(T--)
{
memset(mem,-1,sizeof(mem));
cin>>n;
cout<<dfs(0,n)<<"\n";
}
return 0;
}
但是,放心吧,这个过不去的,绝对会T的,不用试都知道(因为我还没优化结构,嘘,悄悄地)
(并且这个n就到15,我能咋办,就比如说我说计算器nb,但你非要跟我比试1+1=2是口算快还是敲计算器快一样,估计我还没敲,你就知道了)
但但是,恭喜你现在已经知道了记忆化搜索的基本步骤了(话说我前面是不是压根没提 )
假如这题数据范围稍大一些,比如n到100,1000,打表就开始显得不现实了,这个时候,你的方法就可以显出他的用处了
那么我们总结下什么是记忆化搜索
1.不依赖外部变量
2.以自己返回值作为答案
3.对于同一组参数,dfs返回值总是相同
总结:记忆化搜索就是:利用相同参数答案相同的特性,对相同的参数,记录其答案,避免重复计算,优化时间复杂度
相关题目练习推荐(个人向)
洛谷:P1048 采药
P1060 开心的金明
POJ:3176 Cow Bowling
2229 Sumsets
歌曲推荐: 这首歌真的8错,前几天随机听歌听到的,特别是2:10秒后那一段旋律,非常8错,唯一的问题,我学不来他那个整句连读。。。。。

逃。。。。。。(话说我是不是忘记写dp了)(算了,下次吧)
