本博文涉及的代码都已上传到github上,如果想看可以自行下载。
github代码
1.使用Hash技术检索字符串
本次实验有三个子实验,实验简单,只说一下在编程中遇到的问题,希望可以帮到一些人
- 使用两个数组来进行字符串的匹配
- 读取文本文件时出现乱码,原因是文件的编码格式不对,应该是ANSI编码格式,百度了一下,发现该编码格式是最基本的中文编码格式,GBK也只是它的一种变体形式。
- 读取文件时读取一行字符时,输出到结果文件会换行,也就是读取时把换行符也作为该字符串的有效字符读取到,解决方法是读取字符串时一个一个字符的读取,并对换行符进行判断。
- 比较计数器为int类型是发生溢出现象,使用long long类型就避免了溢出的可能性。
- 使用Hash链表进行字符串的匹配操作
- Hash函数的返回值是unsigned int类型,那么hash的地址空间也应该和unsigned int相匹配不然就会出现数组下标越界访问的错误,在该程序中并不需要如此大的Hash空间,故可在Hash函数的出口模一个实际长度
- 在匹配时,原则上匹配成功一次,那么可以在插入hash表时可以不插入重复的元素,减少相同元素重复开辟空间
- 读到最后一个字符串时,最后一个字符的下一个字符就是文件的结束标志,所以最后一个字符串需要在循环外单独进行插入和匹配判断
- 使用Bloom Filter进行字符串匹配
- 使用字符数组作为位数组,在建立Hash值与字符数组中的位关系映射时采用除8模8的方式,导致了几乎全部匹配成功,经发现该映射错误,应该是模8
- Hash函数中可能会出现数组的访问越界错误,关键在于对length的处理上,该程序使用固定的length值,在头文件中进行宏定义len
2.使用树结构检索字符串
本次实验有四个子实验
- 使用平衡二叉树完成字符串检索
代码借鉴于平衡二叉树
博文叙述简明,代码详细周全,不再赘述。只是说一下,在本次实验中的一个小问题:
在查找时,没有较好理解两个字符串比较操作,把两个字符当作是有符号数的比较,导致程序统计27万多的匹配成功串,正好有一半的概率出错,实际上,OS读入文件时把字符串都变成了01串,只不过在程序中显示的是字符,在直观上理解也应该是把01串看成是无符号数,然后把比较函数做成是无符号数比较时,程序就能正确输出所有的可以匹配成功的串。 - 使用B+树完成字符串检索
代码借鉴于B+tree详解及实现(C语言)
该博文讲解到位,代码注释清晰易读,但是在本次实验中我们需要在树节点中存储字符串,所以还需要对代码进行修改,如果在大一学C语言“指针和二维数组”一节时写过多个字符串的冒泡排序法,程序就可能会好改些。该博文代码实现了一棵B*树(比B+树节省空间),如果从树根节点开始向叶子遍历查找一个关键字,是能正确执行的,但是如果从最左的叶子结点开始向右顺序查找时,程序会在某一个中间节点停掉,经过调试,终于找到了错误的原因。
考虑不周的代码
示意图
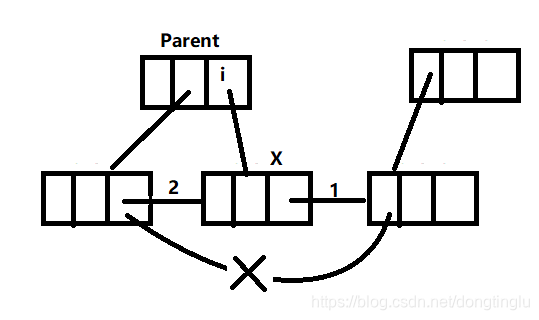
如果按照上面的代码执行,X->next会被置空,提前退出程序。
下面是调试的代码,如果想验证该程序是否正确,其实就是看tt.txt文件的叶子结点数和ff.txt文件的行数是否相等,把tt.txt文件复制到一个word文档里替换[Level:i],i是层数,数替换的总个数,看和行数是否相等,如果相等,正确,否则错误。
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <time.h>
#define M (5)
typedef struct BPlusNode *BPlusTree;
typedef int KeyType;
struct BPlusNode
{
int KeyNum;
KeyType Key[M + 1];
BPlusTree Children[M + 1];
BPlusTree Next;
};
static KeyType Unavailable = INT_MIN;
//生成节点并初始化
static BPlusTree MallocNewNode()
{
BPlusTree NewNode;
int i;
NewNode = (BPlusTree)malloc(sizeof(struct BPlusNode));
if (NewNode == NULL)
exit(EXIT_FAILURE);
i = 0;
while (i < M + 1)
{
NewNode->Key[i] = Unavailable;
NewNode->Children[i] = NULL;
i++;
}
NewNode->Next = NULL;
NewNode->KeyNum = 0;
//输出NewNode结点在堆上的地址
printf("%x\n",NewNode);
return NewNode;
}
//初始化
BPlusTree Initialize()
{
BPlusTree T;
if (M < (3))
{
printf("M最小等于3!");
exit(EXIT_FAILURE);
}
/* 根结点 */
T = MallocNewNode();
return T;
}
/* 当要对X插入Key的时候,i是X在Parent的位置,j是Key要插入的位置
当要对Parent插入X节点的时候,i是要插入的位置,Key和j的值没有用
isKey用来对以上两种状态的区分
*/
static BPlusTree InsertElement(int isKey, BPlusTree Parent,BPlusTree X,KeyType Key,int i,int j)
{
int k;
if (isKey)
{
//插入key
k = X->KeyNum - 1; //为即将插入的Key腾地方
while (k >= j)
{
X->Key[k + 1] = X->Key[k];
k--;
}
X->Key[j] = Key; //插入j位置
//printf("插入X->Key[j]\n");
//插入子节点一个新的key必须要更新父结点中相应的key
if (Parent != NULL)
Parent->Key[i] = X->Key[0];
X->KeyNum++;
}
else
{
//插入节点
//对树叶节点进行连接
if (X->Children[0] == NULL)
{
BPlusTree tmp;
if(i > 0)
tmp = Parent->Children[i-1]->Next;
if (i > 0)
Parent->Children[i - 1]->Next = X;
X->Next = Parent->Children[i];
if(i == Parent->KeyNum && i > 0) //要插入的结点对应Parent节点的最后
X->Next = tmp;
}
k = Parent->KeyNum - 1;
while (k >= i)
{
Parent->Children[k + 1] = Parent->Children[k];
Parent->Key[k + 1] = Parent->Key[k];
k--;
}
Parent->Key[i] = X->Key[0];
Parent->Children[i] = X;
Parent->KeyNum++;
}
return X;
}
static BPlusTree SplitNode(BPlusTree Parent,BPlusTree X,int i)
{
int j,k,Limit;
BPlusTree NewNode;
NewNode = MallocNewNode();
k = 0;
j = X->KeyNum / 2;
Limit = X->KeyNum;
while (j < Limit) //把关键字较大的部分移入NewNode节点中 至多多一个元素
{
if (X->Children[0] != NULL) //X不是树叶节点
{
NewNode->Children[k] = X->Children[j];
X->Children[j] = NULL;
}
//元素移入操作
NewNode->Key[k] = X->Key[j];
X->Key[j] = Unavailable;
NewNode->KeyNum++;
X->KeyNum--;
j++;
k++;
}
if (Parent != NULL)
{
InsertElement(0, Parent, NewNode, Unavailable, i + 1, Unavailable);
//输出以X为表头的链
BPlusTree Tmp = X;
int i=0;
while (Tmp != NULL){
i=0;
printf(",,,,,,%x\n",Tmp);
while(i<Tmp->KeyNum)
{
printf("%d ",Tmp->Key[i]);
i++;
}
printf("\n");
Tmp = Tmp->Next;
}
}
else
{
//如果是X是根,那么创建新的根并返回
Parent = MallocNewNode();
InsertElement(0, Parent, X, Unavailable, 0, Unavailable);
InsertElement(0, Parent, NewNode, Unavailable, 1, Unavailable);
//输出以X为表头的链
BPlusTree Tmp = X;
int i=0;
while (Tmp != NULL){
i=0;
printf(",,,,,,%x\n",Tmp);
while(i<Tmp->KeyNum)
{
printf("%d ",Tmp->Key[i]);
i++;
}
printf("\n");
Tmp = Tmp->Next;
}
return Parent;
}
return X;
}
static BPlusTree RecursiveInsert(BPlusTree T,KeyType Key,int i,BPlusTree Parent)
{
int j,Limit;
BPlusTree Sibling;
//查找分支
j = 0;
while (j < T->KeyNum && Key >= T->Key[j])
{
//重复值不插入
if (Key == T->Key[j])
return T;
j++;
}
if (j != 0 && T->Children[0] != NULL) j--; //T是一个分支节点 应该插入到j-1孩子中 这是根据这棵二叉树的结构来说的
//树叶
if (T->Children[0] == NULL)
{
T = InsertElement(1, Parent, T, Key, i, j);
}
//内部节点
else
T->Children[j] = RecursiveInsert(T->Children[j], Key, j, T);
//先插入节点再进行调整节点
Limit = M;
if (T->KeyNum > Limit)
{
T = SplitNode(Parent, T, i);
}
if (Parent != NULL) //不是根节点都需要更新父节点对应位置的值
Parent->Key[i] = T->Key[0];
return T;
}
//插入
BPlusTree Insert(BPlusTree T,KeyType Key)
{
return RecursiveInsert(T, Key, 0, NULL);
}
static void RecursiveTravel(BPlusTree T,int Level,FILE *f){
int i;
if (T != NULL){
fprintf(f," ");
fprintf(f,"[Level:%d]-->",Level);
fprintf(f,"(");
i = 0;
while (i < T->KeyNum)/* T->Key[i] != Unavailable*/
fprintf(f,"%d:",T->Key[i++]);
fprintf(f,")\n");
Level++;
i = 0;
while (i <= T->KeyNum) {
RecursiveTravel(T->Children[i], Level,f);
i++;
}
}
}
/* 遍历 */
extern void Travel(BPlusTree T,FILE *f){
RecursiveTravel(T, 0,f);
printf("\n");
}
/* 遍历树叶节点的数据 */
extern void TravelData(BPlusTree T,FILE* f,FILE* f1){
BPlusTree Tmp;
int i;
if (T == NULL)
return ;
printf("All Data:");
Tmp = T;
while (Tmp->Children[0] != NULL)
Tmp = Tmp->Children[0];
/* 第一片树叶 */
while (Tmp != NULL){
fprintf(f1,",,,,,,%x\n",Tmp);
i = 0;
while (i < Tmp->KeyNum)
fprintf(f," %d\n",Tmp->Key[i++]);
Tmp = Tmp->Next;
}
}
int main(int argc, char *argv[])
{
int i,size=10000;
BPlusTree T;
T = Initialize();
i = 0;
FILE* f = fopen("t.txt","w");//存储顺序读取结果
FILE* f1 = fopen("tt.txt","w");//树的每一层结构
FILE* f2 = fopen("rand.txt","w");//存储每一个随机数
FILE* ff = fopen("ff.txt","w");//每一个新节点的地址
//设置种子,最好是默认种子
//srand((unsigned int)time(NULL));
while (i < size)
{
int t = rand();
fprintf(f2,"%d\n",t%size);
T = Insert(T,t%size);
i++;
}
TravelData(T,f,ff);
Travel(T,f1);
fclose(f);fclose(f1);fclose(f2);fclose(ff);
return 0;
}该代码建造的B+树,父节点中存储的是子节点中的最小值。
-
使用4叉01基数树完成字符串检索
按照读取的字符串建立一棵4叉树即可 -
使用2叉01基数树完成字符串检索
同理,按照读取的字符串建立一棵2叉树即可
3.多模式字符串匹配
本次实验有三个子实验,
- 朴素的字符串匹配
- Multi KMP
本次实验参考的代码源自于:
从头到尾彻底理解KMP(2014年8月22日版) - AC自动机
借助了前面讲到的前缀树,使得对于多模式字符串的匹配,只需要主串在这棵树上遍历一次,就可以得出模式串在主串中出现的次数。
本次实验参考的代码源自于:
ac自动机最详细的讲解,让你一次学会ac自动机。
4.网络爬虫+PageRank算法
说实话,这部分内容我并没有做出来,因为临近考试了,我并没有花太多的时间去查一些网络爬虫的知识,而PageRank算法关于不可约的推导没看明白,虽然代码是比着优化后的矩阵写的,能跑出结果来,但是看结果好像不太对,也没有再去调,也欢迎大家提出意见。
