花大笔墨整理的一些java高级程序猿必会的面试题,其中有很多都是大厂面试题.
目录
9.HashMap原理/ConcurrentHashMap原理
26.TCP三次握手,TCP,TCP/IP协议,http协议,http1.0,http1.1,http2.0
29.死锁/活锁/饿锁/分布式锁/乐观锁/悲观锁 分别是什么,如何实现.
30.jdk1.7-1.11新特性以及lambda表达式使用.
1.spring IOC原理
IOC即控制反转,其实现主要依托于IOC容器,IOC容器有很多种,这里只提两种,一种是BeanFactory容器,另外一种是ApplicationContext容器,其中BeanFactory容器的初始化过程:
①读取bean.xml配置文件
②创建BeanFactory(new DefaultListableBeanFactory)
③创建资源读取器(new xmlBeanDefinitionReader,并将其与BeanFactory关联.
④将bean.xml中的信息解析成BeanDefinition元数据对象,并注册到IOC容器(BeanFactory)中,也就是将解析后的对象存入BeanDefinitionMap中.
ApplicationContext容器要比BeanFactory容器要高级一些,提供了一些额外的附加功能:支持不同的信息源,支持应用事件等.
至此,配置在bean.xml中的bean就被容器管理起来了,在注入时,通过扫描注解然后获取对应的bean进行注入即可.
2.spring bean生命周期
①Bean实例的创建
②为Bean实例设置属性
③初始化Bean的接口方法
④应用通过IOC容器获取Bean
⑤当容器销毁时,调用Bean的销毁方法doclose().
3.spring aop原理
spring aop是基于动态代理实现的,在此之前,你需要先了解设计模式-代理模式.
不同的是,spring aop更加智能,动态代理有2种实现方式,一种是通过JDK提供的代理,一种是通过CGLIB实现,前者要求被代理对象必须实现接口,或者则要求被代理对象必须可以被继承,如果加了final修饰则不行.
spring aop在对对象进行代理前会自行判断使用Jdk动态代理还是cglib,部分代码片段如下:
@Override
public AopProxy createAopProxy(AdvisedSupport config) throws AopConfigException {
if (config.isOptimize() || config.isProxyTargetClass() || hasNoUserSuppliedProxyInterfaces(config)) {
Class<?> targetClass = config.getTargetClass();
if (targetClass == null) {
throw new AopConfigException("TargetSource cannot determine target class: " +
"Either an interface or a target is required for proxy creation.");
}
//判断如果是接口,或者是被代理的类,则使用JDK动态代理
if (targetClass.isInterface() || Proxy.isProxyClass(targetClass)) {
return new JdkDynamicAopProxy(config);
}
//否则用cglib动态代理,(没有实现接口的类)
return new ObjenesisCglibAopProxy(config);
}
else {
//默认使用jdk动态代理
return new JdkDynamicAopProxy(config);
}
4.spring mvc原理
Spring mvc是以DispatcherServlet为核心实现的,具体的工作原理如图所示:
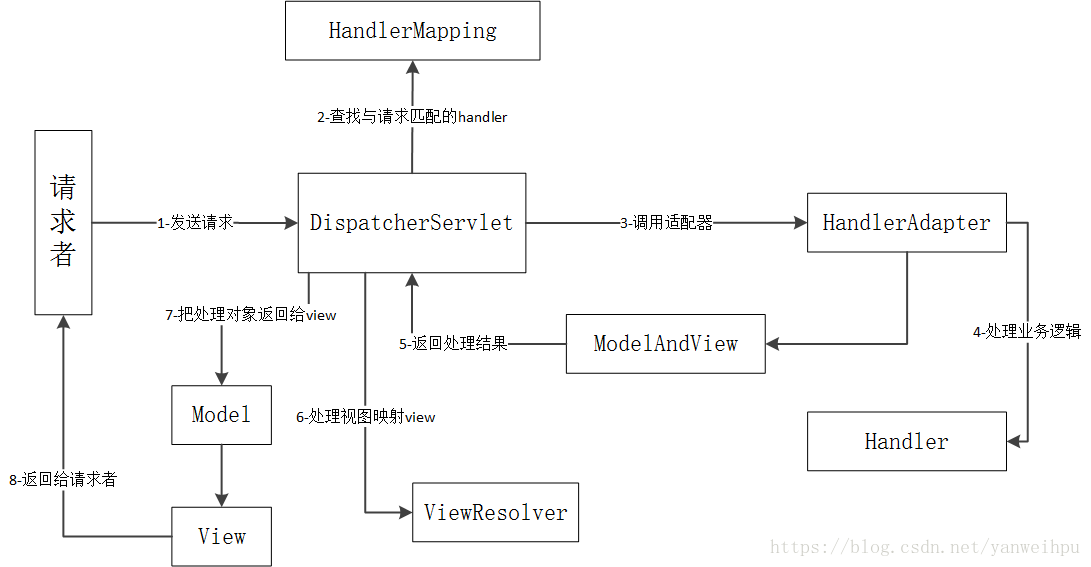
①用户发送请求至DispatcherServlet
② DispatcherServlet根据请求信息调用HandlerMapping,由HandlerMapping查找与请求匹配的Handler.
③找到Handler后,由对应的HandlerAdapter来调用真正的处理器来处理业务.
④处理完返回Model/View至Dispatcher.
⑤调用ViewResolver处理view,根据逻辑找到相应的View并返回
详见:https://blog.csdn.net/yanweihpu/article/details/80366218
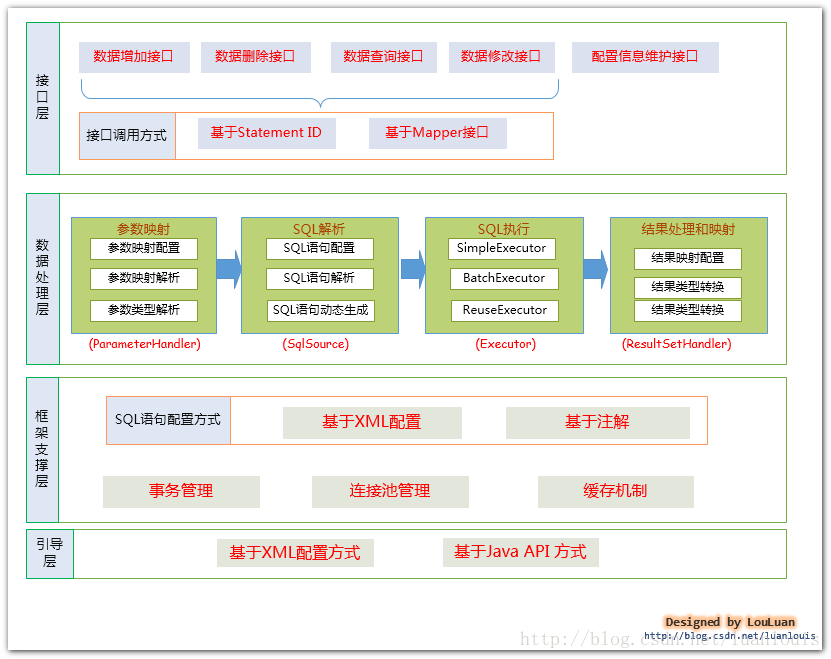
5.Mybatis原理
Mybatis作为一套优秀的ORM框架,主要做了两件事:
①自动创建jdbc连接并执行sql
②利用反射打通java类和sql之间的相互转换.
Mybatis的架构设计可以参考这张图:
其实现主要依托下面这些类:
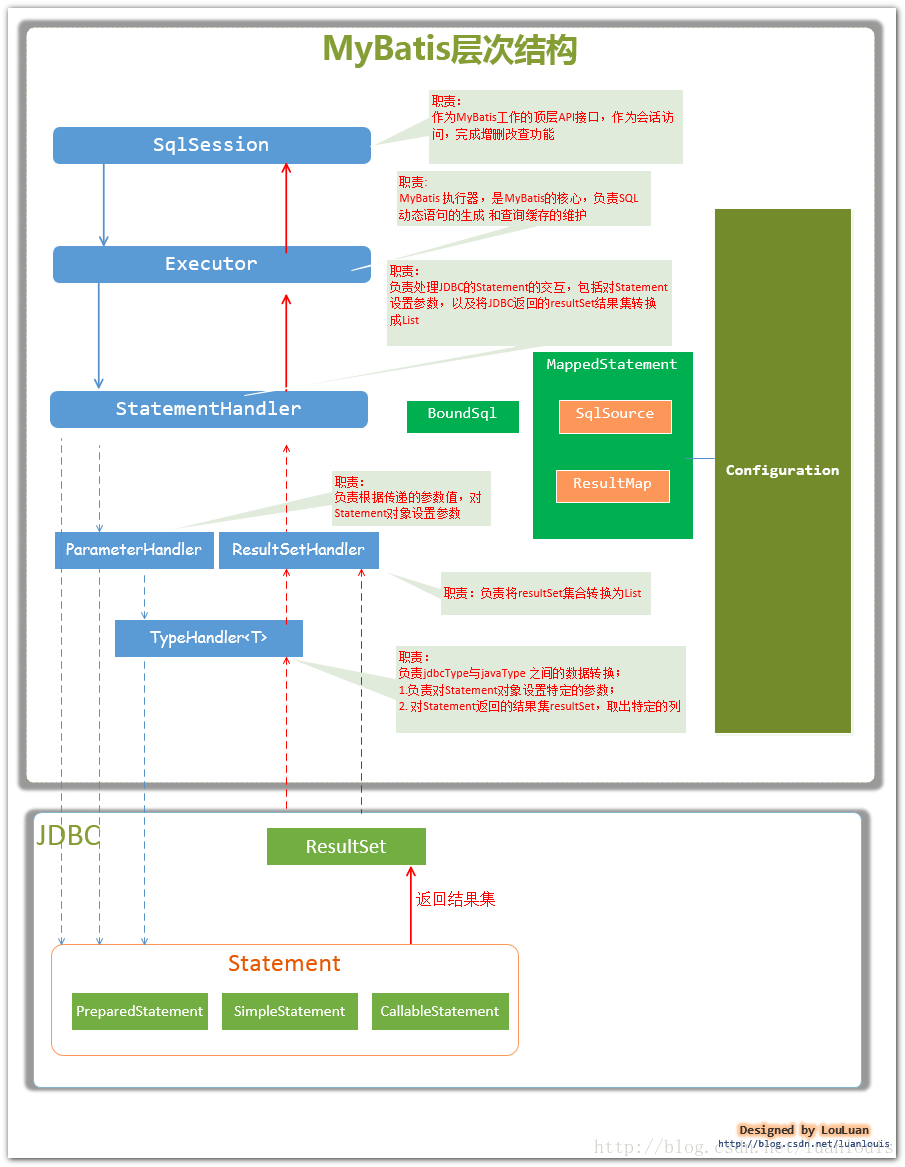
Configuration:Mybatis的大部分配置信息都放在该类中.
SqlSession:负责和数据库的交互会话
Executor:执行sql和缓存管理
ResultsetHandler:负责将sql查询返回的结果集set转换为List
parameterHandler:负责将用户传入的参数转为jdbc statement 对应的数据类型
statementHandler:负责对jdbc statement的操作 如设置参数
TypeHandler:负责将查询结果和实体映射
Sqlsource:负责动态生成sql语句
详见:https://www.cnblogs.com/luoxn28/p/6417892.html
6.servlet原理
详见:https://www.ibm.com/developerworks/cn/java/j-lo-servlet/和https://www.cnblogs.com/gaoxiangde/p/4339571.html
7.netty原理
详见:https://www.jianshu.com/p/a4e03835921a
8.dubbo原理

Dubbo的架构图主要包含4个部分
Registry:注册中心,服务的注册和调用都需要依赖它
Consumer:消费者,启动后会向注册中心订阅生产者信息,配置信息,路由信息等.
Provider:生产者,启动后会向注册中心发送生产者信息,并注册它提供服务的接口,订阅配置信息.
Monitor :负责监控服务的调用情况
再细一点
9.HashMap原理/ConcurrentHashMap原理
HashMap原理:
Jdk1.7 数组+链表
Jdk1.8 数组+链表+红黑树
详见:https://cloud.tencent.com/developer/article/1337158
ConcurrentHashMap原理:
jdk1.7 数组+链表+segment
jdk1.8 数组+链表+红黑树+cas+sync
在put时采用cas锁,在扩容时使用sync同步锁.
详见:https://www.jianshu.com/p/c0642afe03e0
https://cloud.tencent.com/developer/article/1124663
10.线程池原理
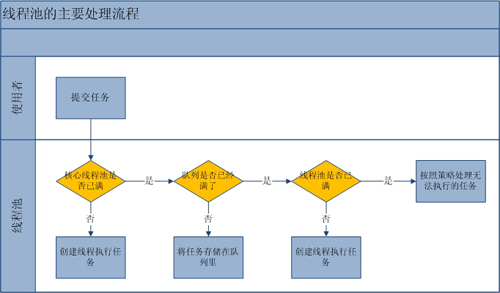
如图,通过调用线程池的execute方法条件任务至线程池,线程池会先判断核心线程池是否已满?如果没满就分配线程去执行该任务,如果满了会判断当前队列中排队的线程是否已满?如果没满就加入队列中排队等待,如果满了就去判断线程池是否已满(线程数>maximumPoolSize),如果未满就创建新的线程执行任务,如果满了就按饱和策略去处理.
11.redis集群
详见:https://blog.csdn.net/lovexiaotaozi/article/details/83411918
12.mongodb集群
详见:https://blog.csdn.net/lovexiaotaozi/article/details/86479008
13.zookeeper集群
详见:https://blog.csdn.net/lovexiaotaozi/article/details/83308386
14.msyql 集群(主从模式)
详见:https://blog.csdn.net/lovexiaotaozi/article/details/82591248
15.nginx集群
详见:https://www.cnblogs.com/xiugeng/p/10155283.html
16.mycat集群
详见:https://blog.csdn.net/lovexiaotaozi/article/details/83022009
17.spring cloud 集群
详见:https://blog.csdn.net/lovexiaotaozi/article/category/8018191
18.springboot的部署如何区分测试环境/生成环境
可以使用参数: --spring.profiles.active=test/prod来动态指定
eg: java -jar app.jar --spring.profiles.active=prod &
19.springboot 和 spring 区别
springboot 整合了spring+spring mvc 是spring的免配置版,免去了spring中繁琐的配置,实现了自动化配置,并内置了tomcat服务器,可以直接以jar包启动项目.
20.jvm的类加载机制

jvm的类加载过程一共有以下几个步骤:
①加载:将二进制.class文件加载进jvm虚拟机
②验证:验证字节码文件是否符合Jvm规范,不会对jvm造成损害
③准备:为类变量分配内存,设置类变量的初始值
④解析:将常量池中的符号引用替换为直接引用
⑤初始化:调用类的构造器,将类初始化
⑥使用:完成相应调用
⑦卸载:被垃圾回收器回收
其中,②~④三个步骤统称为连接.
jvm的类加载器采用双亲委派模型,在类加载时不会先直接调用自己的类加载器,而是去尝试调用其父类加载器,父类加载器处理不了会向上传递,直到顶层的bootstrap类加载器也完成不了时,才会使用该类的类加载器,这样可以保证安全,避免我们哪天自己定义了一个叫Object的类,被jvm混淆.
21.jvm的内存模型
jvm的内存模型如下:
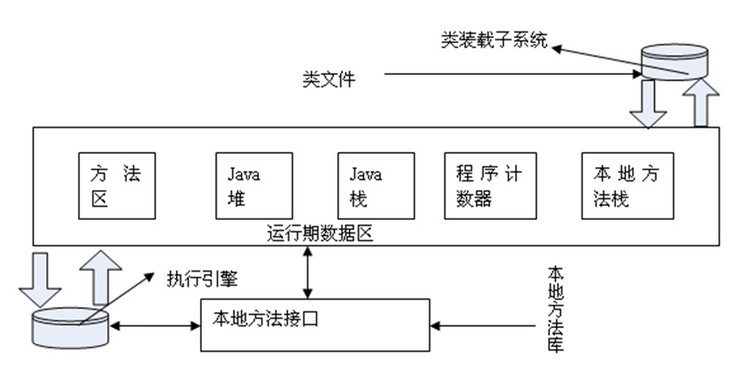
①方法区 :存放常量,静态变量等.
②堆区:存放实例对象,占用大部分内存空间,垃圾回收的主要区域.
③java虚拟机栈:存放每个方法执行时创建的操作枕,链接,方法出口等信息.
④程序计数器:jvm所执行字节码行号的指示器,通过改变计数器的数值来控制程序的循环,分支,跳转等.
⑤本地方法栈:功能与java虚拟机栈类似,但仅服务于java虚拟机调用的一些native方法.
22.jvm的垃圾回收器
SerialGC串行的垃圾回收器,单线程垃圾回收器,在较早的Jdk版本中使用.
ParallelGC并行的垃圾回收器,多线程垃圾回收,效率较高,目前大多数版本默认使用的垃圾回收器,垃圾回收时服务会短暂中断.
CMSGC并发GC,垃圾回收不影响服务,对那些服务延迟敏感的业务可以使用,但会产生一定的垃圾碎片.
G1GC 出现时间较晚,Jdk1.7出现,性能极好,支持并行和并发,也是我最喜欢的一款垃圾回收器,非常智能.仅需少量的jvm调优参数,即可实现大师级的Jvm调优效果.
23.jvm调优
可以使用java自带的jconsole,jvisualvm对想要监控的jvm进行监控,观测.
通常做法是,在启动Jar的时候 添加一条参数 -Xloggc: .../log/gc.log(存放路径) 导出gc日志,然后将该gc日志用winscp导出,用gcview或者http://gceasy.io 等工具进行分析和优化. 监控的主要参数有 垃圾回收暂停时间,吞吐量等指标进行评估,当然还要结合当前CPU和内存的空闲率,比如cpu比较空闲,内存比较紧张,那可以适当的增加gc次数,如果cpu资源比较紧张,内存比较空闲,可以通过调整最大堆大小减少gc次数.
下面是一条我总结的万金油,大部分springboot项目适用,我拿大量项目进行测试都屡试不爽!基于G1GC:
-xmn:256m -xmx: 512m -XX:+UseG1GC -XX:MaxGCPauseMillis=200
前两条参数可以不指定,或者根据你当前服务器的剩余内存和CPU综合考量, 暂停时间200毫秒也可以根据你自己项目的要求去调整,我测过大量的项目在上述约束条件的限制下,均能够保持95%以上的吞吐量,有个项目的吞吐量竟然达到了99.987%,让人喜出望外.
24.jvm的垃圾回收算法.
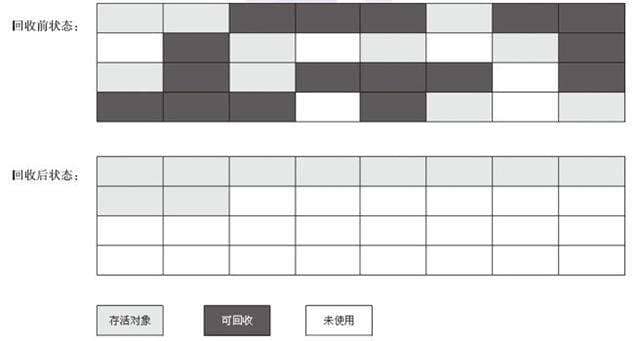
标记-清除算法 也叫白灰黑三色算法.
第一遍进行标记,将不可达对象标记为白色,根对象标记为黑色,被引用对象标记为灰色,然后第二遍进行清除,将第一遍被标记为白色的对象清除. 优点是效率较高,缺点是会产生大量不连续碎片.
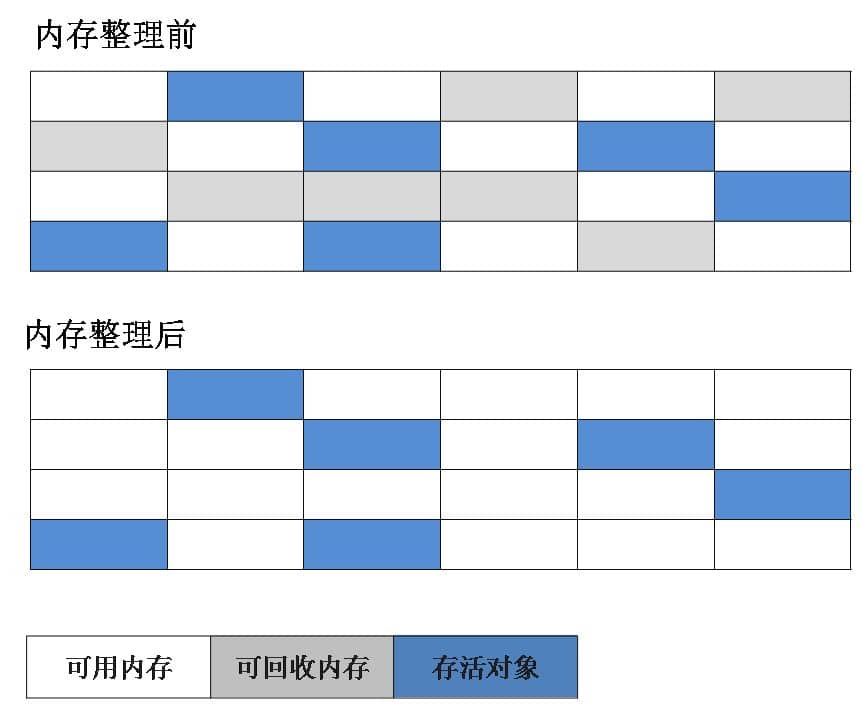
标记-复制算法
是对标记清除算法的改良,解决了碎片问题,第一遍进行标记,第二遍将标记为有用的对象复制到一个新的区域,然后把原来老区域中的对象全部清除.对应young区的s0和s1区.在垃圾较少时效率会很低,因为要复制很多对象,而且始终有一半等大的内存区域处于空闲状态,浪费了内存空间.
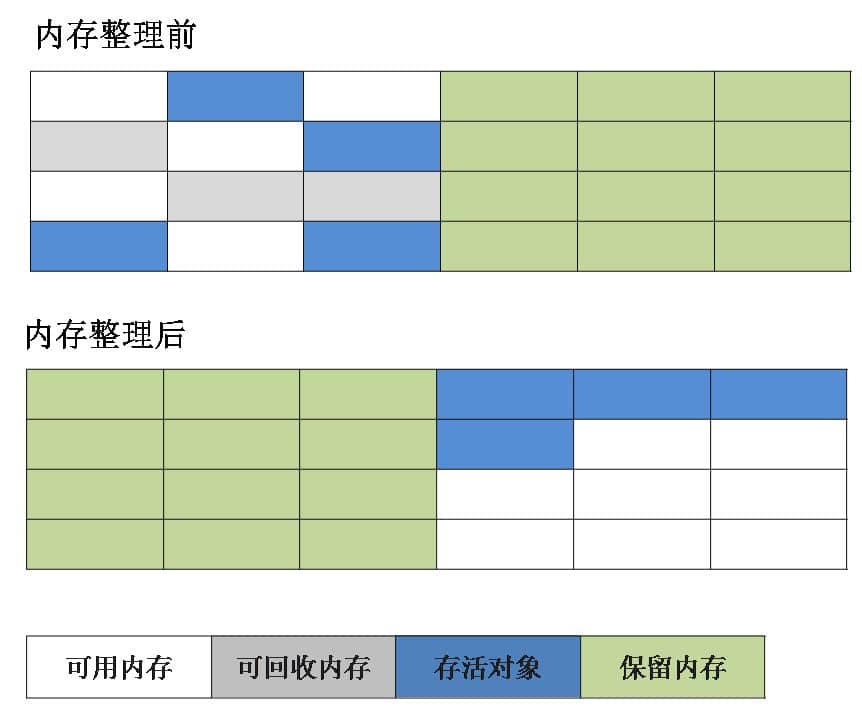
标记-整理算法
是对标记复制算法的改进,第一遍与前面两种算法一样,先进性标记,第二遍是让所有存活的对象往一端移动,然后把边界以外的对象进行清理.
分代收集算法
将内存区域分为新生代和老年代,分别对新生代和老年代采取不同的回收策略.
25.什么时候会发生minor gc, full gc?
当Young区中的Eden空间不足时会触发minor gc,当old区空间不足时会触发full gc,当方法区空间不足时会触发full gc,当调用System.gc时有可能会触发full gc. 另外要提到的是major gc和 full gc的区别,major gc只清理永久代的垃圾,full gc会清理整个堆空间的垃圾.
26.TCP三次握手,TCP,TCP/IP协议,http协议,http1.0,http1.1,http2.0
①TCP协议为啥是三次握手而不是两次或者更多?
两次握手是基本的,比如A向B发送请求,B收到A的请求向A回应一个ack,表示它可以接受,如果在这个时候建立通道,在大部分情况下是可以的,但如果A向B发送请求时网络延迟太长了,这时候A可能已经不再需要与B建立连接了,但B在收到请求后向A回应一个ack并建立了连接,于是B就傻傻的等着,接收不到任何消息,造成资源浪费,所以需要三次握手,之所以不需要更多是因为3次就可以保证可靠了,没必要再浪费资源进行第四次握手.
②TCP/IP

应用层:为用户提供一组常用的应用程序,如邮件,ftp等.
传输层:控制流量,提供错误处理,如TCP,UDP
网络层:实现物理地址与逻辑地址的转换,IP协议.
网络接口层:物理层次的一些接口,比如网线.
http1.0仅支持短连接,每次请求都要创建新的连接,浪费资源,http1.1在此基础上进行了改进,可以支持长连接,一个tcp连接可以处理多个http请求,减少了频繁创建关闭连接的开销.
http2.0在性能上较前两代有了较大提升,它对请求的头部采用了更先进的压缩方式,同时传输的数据格式采用二进格式,而非1.1中采用的文本,相比之下更为健壮,另外http2.0支持服务端推送.
27.各种设计模式
详见:https://blog.csdn.net/lovexiaotaozi/article/category/8327036
28.自定义注解
详见:https://blog.csdn.net/lovexiaotaozi/article/details/88351750
29.死锁/活锁/饿锁/分布式锁/乐观锁/悲观锁 分别是什么,如何实现.
死锁:不能自己解锁,会一直死下去... 比如A持有B的锁,尝试获取A的锁,B持有A的锁,尝试获取B的锁,A和B谁也不释放自己持有的锁而想着获取对方拥有的锁,于是就这样一直僵持下去...
活锁:有可能自己解锁.比如两个优先级一样的线程A和B,A很绅士,让B先执行,B也很绅士,让A先执行,于是它们就这样互相谦让下去...
饿锁:常发生在多个线程的情况下,A线程刚准备执行,发现来了个优先级更高的B线程,于是让B线程先执行,B线程执行完了A准备执行时又来了个优先级更高的C,于是C执行了...又来了个D...E...就这样A一直出在饥饿状态
分布式锁:在分布式场景下会经常用到,在单体架构中,我们可以通过同步锁,同步代码块来解决超卖的问题,但在分布式的情况下,一个项目中的同步锁/同步代码块都不会对另一个项目产生影响,于是超卖问题又出现了,所以这时候需要一把全局的锁来防止类似超卖这种问题的发生,常见的分布式锁可以通过zk,redis,mysql来实现.
乐观锁:比较乐观,认为并发不存在或者并发比较少,不会锁住资源,而是在更新时通过字段的version来判断是否有并发,比如Jdk1.8中的crurrentHashMap就有用到CAS乐观锁.
悲观锁:比较悲观,认为并发存在,会阻塞线程,没有获取到锁的线程需要等待拥有锁的线程释放锁.比如经常用到的synchronized,juc包提供的各种锁都是悲观锁.
详见:https://blog.csdn.net/lovexiaotaozi/article/details/83825531
30.jdk1.7-1.11新特性以及lambda表达式使用.
jdk1.7新特性:
①新增了G1GC
②新增了try with resouce 不用try catch finally来关闭资源,会自动关闭.
③新增switch支持String类型
jdk1.8新特性:
①新增lambda表达式,匿名内部类的简写和stream的各种功能要会用.
②改变了原有HashMap,ConcurrentHashMap结构.
③新增日期类API,如LocalDate
jdk1.9
引入了var 可以像写前端js那样 直接声明一个变量var而不需要定义它的类型,比如 var x = new ArrayList<Integer>();
jdk11
引入了ZGC,垃圾回收暂停时间比G1GC更短.
