索引覆盖 最左前缀 索引下推
索引覆盖
总结问题
-
什么是索引覆盖?
-
怎么用到索引覆盖
-
索引覆盖的情况,using index ; using index using where
-
select * from T where k betwee 3 and 5 这条语句的执行流程是什么样的? 边界查询
-
回表的概念是什么?
-
索引覆盖的概念是什么, 索引覆盖的优点是什么?
-
最左前缀原则的概念是什么? 说明最左前缀原则的执行过程.
-
索引下推的概念是什么? MySQL 5.6 的下推优化是怎么做的?
总结
-
查询的数据在索引树中可以找到,不需要回到数据树中去查找
-
查找select 的列必须被where的列(索引)覆盖,就能使用到索引覆盖(二级索引)
-
查询的列在索引树中可以查到,where条件为前导列
-
查询的列在索引树中,where条件不是联合索引的前导列
-
查询的列在索引树中,where是联合索引前导列的范围查询
- 覆盖索引:如果查询条件使用的是普通索引(或是联合索引的最左原则字段),查询结果是联合索引的字段或是主键,不用回表操作,直接返回结果,减少IO磁盘读写读取正行数据
- 最左前缀:联合索引的最左 N 个字段,也可以是字符串索引的最左 M 个字符
- 联合索引:根据创建联合索引的顺序,以最左原则进行where检索,比如(age,name)以age=1 或 age= 1 and name=‘张三’可以使用索引,单以name=‘张三’ 不会使用索引,考虑到存储空间的问题,还请根据业务需求,将查找频繁的数据进行靠左创建索引。
- 索引下推:like 'hello%’and age >10 检索,MySQL5.6版本之前,会对匹配的数据进行回表查询。5.6版本后,会先过滤掉age<10的数据,再进行回表查询,减少回表率,提升检索速度
建表语句
mysql> create table T (
ID int primary key,
k int NOT NULL DEFAULT 0,
s varchar(16) NOT NULL DEFAULT '',
index k(k))
engine=InnoDB;
insert into T values(100,1, 'aa'),(200,2,'bb'),(300,3,'cc'),(500,5,'ee'),(600,6,'ff'),(700,7,'gg');
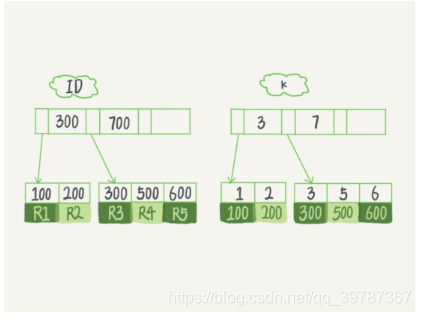
select * from T where k between 3 and 5
sql查询语句的执行流程:
-
在k索引树上找到k=3的记录,取得ID=300;
-
再到ID索引树查到ID=300对应的R3;
-
在k索引树上找到k=5的记录,取得ID=500;
-
再在ID索引树上找到ID=500对应的R4;
-
在k索引树上取得下一个值k=6,不满足条件,循环结束
在这个过程中,**回到主键索引树搜索的过程,我们称为回表,**可以看到,这个查询流程读了k索引的3条记录(1.3.5),回表了两次(2.4)
索引覆盖
如果执行的sql语句是
select ID from T where k between 3 and 5
这时只需要查ID的值,而ID得值已经在k索引树上了,因此可以直接提供查询结果,不需要回表,也就是说,在这个查询里面,索引k已经”覆盖了”我们的查询需求,我们称为索引覆盖
由于索引覆盖可以减少树的搜索次数,显著提升性能,所以使用索引覆盖是一个常用的优化手段
扫描行数
需要注意的是,在引擎内部使用索引覆盖在索引k的记录上其实读了三个记录,R3~R5(还有后面的一条记录),但是对于MYSQL的server来说,他就是找引擎拿到了两条记录,因此认为扫描行数是2
执行计划中的索引覆盖情况
https://www.cnblogs.com/wy123/p/7366486.html
总结
查找select 的列必须被where的列(索引)覆盖,就能使用到索引覆盖
-
执行计划中using index ,查询的列被索引覆盖,并且where的筛选条件是索引的前导列,Extra中为Using index
-
执行计划中 using index using where,查询的列呗索引覆盖,并且where的筛选条件是索引列之一但是不是索引列的前导列,Extra中为using index using where,以为这无法直接通过索引查找来找到符合条件的数据
-
查询的列呗索引覆盖,并且where筛选条件是索引列的前导列的一个范围,同样以为这无法直接通过索引查找到符合的数据
-
Using index不读数据文件,只从索引文件获取数据
-
Using where过滤元组和是否读取数据文件或索引文件没有关系

using index
https://www.cnblogs.com/wy123/p/7366486.html
using index and using shere
https://www.cnblogs.com/wy123/p/7366486.html
最左前缀

很好的问题,仔细考虑其中的原因,会有收获
解答:
-
like ‘j’ 或 ‘j%’ 可以使用索引,并且快速定位记录。
-
like ‘%j’ 或 ‘%j%’,只是在二级索引树上遍历查找记录,并不能快速 定位(扫描了整棵索引树)。
-
只有 id 和 uname 字段时,上述 4 种 like 查询,uname 索引能满足 id 和 uname 的查询情况,不需要回表,所以选择了使用 uname 的索引树解决问题。
-
添加了 age 但无联合索引 (uname, age) 的情况,如果使用 uname 索引树,需要回表。在 like ‘%j’ 或 ‘%j%’ 直接扫描主键索引树,现象就是没有使用 uname 索引。
-
添加了 age 字段,也添加了 (uname, age) 索引,和第 3 点同理,使用覆盖索引就能满足 select * 的字段查询,不需要回表,因此使用了 (uname, age) 索引树。但是只有 like ‘j’ 和 ‘j%’
能快速定位记录,而 like ‘%j’ 和 ‘%j%’ 也能使用该索引树,但是不能快速定位,需要顺序遍历。
二级索引比主键索引快的场景
数据量大的时候,二级索引的覆盖索引会比主键查询快,主键索引的记录的数据量很大,二级索引的数据小,并且索引覆盖

索引下推
总结
-
索引下推是什么?
-
索引下推的好处?
-
索引下推的场景?
select 列不是or不全包括在二级索引中,where中是索引的列有范围或者模糊查询的时候,不直接取最左前缀回表取数据在做比较,会先比较索引列的其他值,然后在回表,减少回表次数.
场景

索引下推一般可用于所求查询字段(select列)不是/不全是联合索引的字段,查询条件为多条件查询且查询条件子句(where/order by)字段全是联合索引。
假设表t有联合索引(a,b),下面语句可以使用索引下推提高效率
select * from t where a > 2 and b > 10;
索引是name age的联合索引
查询名字第一个是张,并且年龄是10岁的所有男孩
mysql> select * from tuser where name like '张%' and age=10 and ismale=1;
这个sql只用到了索引前缀的ID3
索引下推
从5.6之前,只能从ID3开始一个一个回表,到主键索引上找到数据行,在对比字段值
而5.6以后引入的索引下推优化(index condition pushdown),可以在遍历过程中,对索引中包含的字段先做判断,直接过滤掉不满足条件的记录,减少回表次数.

图3中,在(name,age)索引里面我特意去掉了age的值,这个过程InnoDB并不会看age的值,只是顺序的吧”name”第一个是”张”的记录一条条取出来回表,因此需要回表4次
图4和图3的区别是,InnoDB在(name,age)索引内部就判断了age是否等于10,对于不等于10的记录,直接跳过,在这个例子中,只需要对ID4.ID5这两条记录回表去数据判断,就只需要回表2次
