使用 scrapy 的时候 ,莫名出现了 ‘‘TCP 连接超时’’ 的错误 ,错误状态码110
TCP : 传输控制协议,是一种可靠的面向连接的协议
从客户端来看,在我们的应用场景中,因为频繁的使用短连接,而且在同一台机上的客户端的数量比较多,造成了大量的 TIME-WAIT 状态的端口,当 TIME-WAIT 状态端口的数量铺满了整个 port_range 范围后,就会产生 99 号错误;从服务端来看,因为频繁大量的 accept 短连接,到达一定量后,服务端口的 listen 队列会出现溢出,这个时候,新的连接请求会被丢弃,连接建立失败,客户端也就产生了 110 号错误。
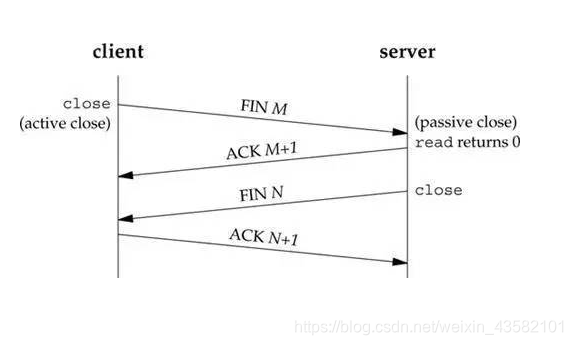
- TCP短连接:一次读写完成,此时双方任何一个都可以发起 close 操作
- TCP长连接:长时间操作之后再由 client发起关闭请求
- port_range :Linux中限定的端口的使用范围
- TIME-WAIT状态:是连接一端主动关闭并发送完最后一个 ACK 之后所处的状态,(即首先调用close()发起主动关闭的一方,在发送最后一个ACK之后会进入time-wait状态)。之所以要有这个状态,是为了让前一个连接的包不影响后面的链接,并且可以被有效的应答,以保证 TCP 连接的可靠性。
长连接可以省去较多的TCP建立和关闭的操作,减少浪费,节约时间。对于频繁请求资源的客户端适合使用长连接。
Client与server之间的连接如果一直不关闭的话,会存在一个问题,随着客户端连接越来越多,连接就会越来越多。
短连接对于服务器来说管理较为简单,存在的连接都是有用的连接,不需要额外的控制手段。但如果客户请求频繁,将在TCP的建立和关闭操作上浪费时间和带宽。
为了避免混淆在 TIME-WAIT 状态连接上的处理的包是前一个连接迟到的包还是新连接的包,TCP 协议规定在整个 TIME-WAIT 状态下,不能再建立同样的连接。并且会检测端口的使用情况。
相较于爬虫程序来说,长连接过多会导致连接池溢出,,导致服务器压力过大。短连接过多,会导致TIME-WAIT溢出,端口无法使用,从而TCP连接超时。
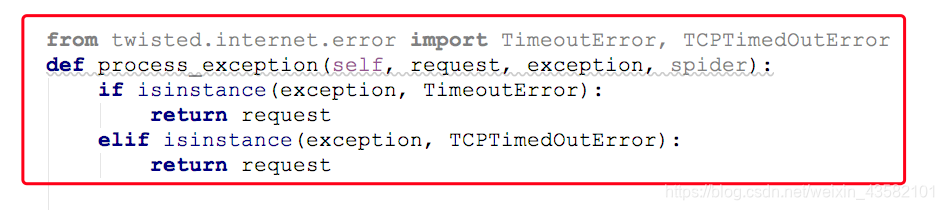
解决方法1:
在中间键的 process_exception 方法中 ,重新请求一次
解决方法2:
通过调整内核参数,提高客户端的链接超时限制。
可自行百度:linux 大量time_wait的解决方法。
解决方法3:
降低并发请求的数量,减少短连接的使用,或者将短连接替换为长连接。
在 settings.py 中设置一些参数

参数值需按自身使用情况自行更改。
解决方法4:
还有一种情况就是服务端有问题,所有的人都访问不了。或者是你的网络断网,网络波动导致。这种情况暂时搁置,明日再试一次。 还有在使用解决方法之前,先查看下你的代理IP是否稳定可用。
