一:Elasticsearch的安装
1.下载elasticsearch(Linux版本)
官网地址:https://www.elastic.co/downloads/elasticsearch
2.传输到特定的目录以后解压
tar -zxvf elasticsearch-6.2.4.tar.gz
3.文件夹改名
mv elasticsearch-6.2.4/ elasticsearch
4.新建用户(高版本Elasticsearch不允许root启动)
useradd ela
passwd ela
5.修改文件夹所属
chown -R ela:ela /elasticsearch
6.修改配置
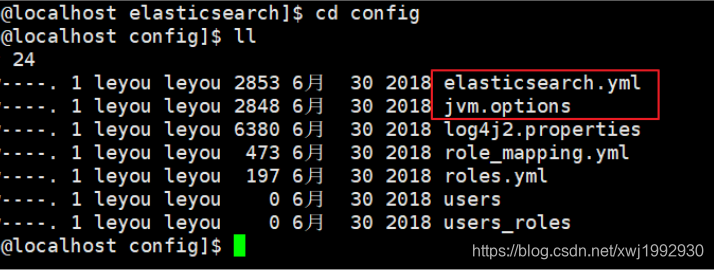
6.1 jvm.options
默认配置如下:
-Xms1g
-Xmx1g
内存占用太多了,我们调小一些:
-Xms512m
-Xmx512m
6.2 elasticsearch.yml
修改数据和日志目录:
path.data: /usr/local/src/elasticsearch/data # 数据目录位置
path.logs: /usr/local/src/elasticsearch/logs # 日志目录位置
修改目录以后记得在相应位置创建这两个文件夹,所有人为ela

修改绑定的ip:
network.host: 0.0.0.0 # 绑定到0.0.0.0,允许任何ip来访问
默认只允许本机访问,修改为0.0.0.0后则可以远程访问
7.启动后可能会出现的问题以及解决(本人的CentOS7只遇到了错误2,4)
错误1:内核过低(CentOS版本过低)
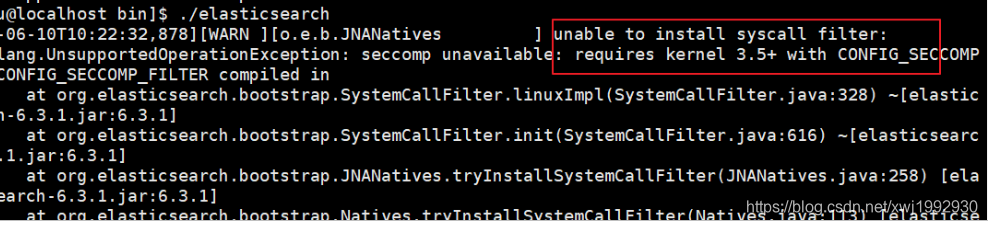
修改elasticsearch.yml文件,在最下面添加如下配置:
bootstrap.system_call_filter: false
错误2:文件权限不足
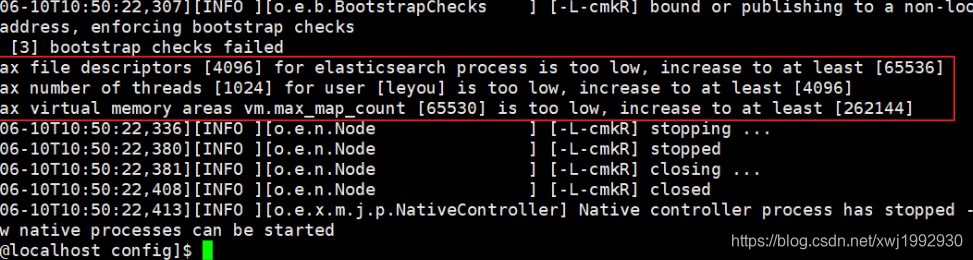
我们用的是ela用户,而不是root,所以文件权限不足。
首先用root用户登录。
然后修改配置文件:
vim /etc/security/limits.conf
添加下面的内容:
* soft nofile 65536
* hard nofile 131072
* soft nproc 4096
* hard nproc 4096
错误3:线程数不够
刚才报错中,还有一行:
[1]: max number of threads [1024] for user [leyou] is too low, increase to at least [4096]
继续修改配置:
vim /etc/security/limits.d/90-nproc.conf
修改下面的内容:
* soft nproc 1024
改为:
* soft nproc 4096
错误4:进程虚拟内存
[3]: max virtual memory areas vm.max_map_count [65530] likely too low, increase to at least [262144]
vm.max_map_count:限制一个进程可以拥有的VMA(虚拟内存区域)的数量,继续修改配置文件, :
vim /etc/sysctl.conf
添加下面内容:
vm.max_map_count=655360
然后执行命令:
sysctl -p
8.重启终端窗口
所有错误修改完毕,一定要重启你的 Xshell终端,否则配置无效
9.启动Elasticsearch
进入安装目录的bin文件夹,执行
./elasticsearch 普通启动
./elasticsearch -d 后台启动
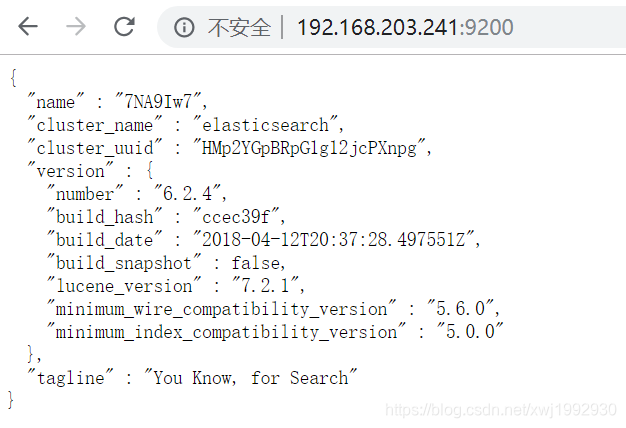
10.启动成功后访问网页出现界面
二:Kibana的安装(windows版本)
kibana的使用依赖于node.js,所以先安装node
https://jingyan.baidu.com/article/d169e1860e6d8c436611d89a.html
1.官网下载(版本最好与Elasticsearch版本一致)
https://www.elastic.co/cn/downloads/kibana
2.解压到特定目录
3.修改配置文件
进入安装目录下的config目录,修改kibana.yml文件:
elasticsearch.url: "http://192.168.203.241:9200/"
4.运行
进入安装目录下的bin目录:
双击kibana.bat
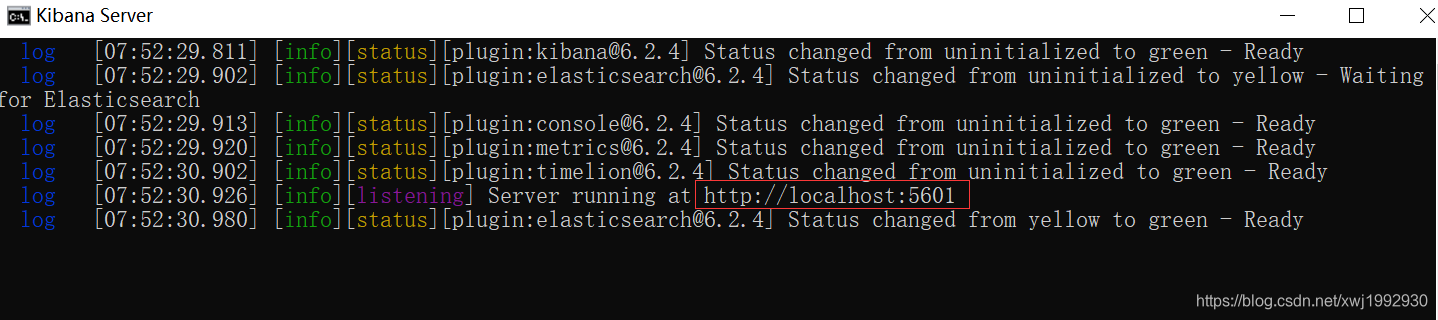
我们访问:http://127.0.0.1:5601 显示下图为成功
三:安装分词器
1.官网下载(版本必须与Elasticsearch一致)
https://github.com/medcl/elasticsearch-analysis-ik/releases?after=v6.4.2
2.解压到Elasticsearch目录的plugins目录中
unzip elasticsearch-analysis-ik-6.2.4.zip
对于本人的ik-6.2.4,解压后发现有一个父文件夹,高版本的ik分词器没有父文件夹,文件目录解析就会出问题,所以需要Elasticsearch和分词器一致
3.必须删除压缩包,不然Elasticsearch会扫描压缩包然后报错
4.重启Elasticsearch
5.测试
在kibana控制台输入下面的请求:
POST _analyze
{
"analyzer": "ik_max_word",
"text": "我是中国人"
}
运行得到以下结果就表明分词器启用成功:
{
"tokens": [
{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "是",
"start_offset": 1,
"end_offset": 2,
"type": "CN_CHAR",
"position": 1
},
{
"token": "中国人",
"start_offset": 2,
"end_offset": 5,
"type": "CN_WORD",
"position": 2
},
{
"token": "中国",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 3
},
{
"token": "国人",
"start_offset": 3,
"end_offset": 5,
"type": "CN_WORD",
"position": 4
}
]
}
