数据结构原理
一、数组:
数组是最常用的数据结构,创建数组必须要内存中一块连续的空间,并且数组中必须存放相同的数据类型。
比如我们创建一个长度为 10,数据类型为整型的数组,在内存中的地址是从 1000 开始,那么它在内存中的存储格式如下:

由于每个整型数据占据 4 个字节的内存空间,因此整个数组的内存空间地址是 1000~1039,可以轻易算出数组中每个数据的内存下标地址。
比如下标 2,就可以计算得到这个数据在内存中的位置 1008,从而对这个位置的数据 66213 进行快速读写访问,时间复杂度为 O(1)。
随机快速读写是数组的一个重要特性,但是要随机访问数据,必须知道数据在数组中的下标。如果我们只是知道数据的值,想要在数组中找到这个值,那么就只能遍历整个数组,时间复杂度为 O(N)。
二、链表:
不同于数组必须要连续的内存空间,链表可以使用零散的内存空间存储数据。
链表在内存中的数据不是连续的,所以链表中的每个数据元素都必须包含一个指向下一个数据元素的内存地址指针。
如图所示:
链表的每个元素包含两部分,一部分是数据,一部分是指向下一个元素的地址指针。最后一个元素指向 null,表示链表到此为止。
因为链表是不连续存储的,要想在链表中查找一个数据,只能遍历链表,所以链表的查找复杂度总是 O(N)。
因为链表是不连续存储的,所以在链表中插入或者删除一个数据是非常容易的,只要找到要插入(删除)的位置,修改链表指针就可以了。如图,想在 b 和 c 之间插入一个元素 x,只需要将 b 指向 c 的指针修改为指向 x,然后将 x 的指针指向 c 就可以了。
相比在链表中轻易插入、删除一个元素这种简单的操作,如果我们要想在数组中插入、删除一个数据,就会改变数组连续内存空间的大小,需要重新分配内存空间,这样要复杂得多。
三、Hash表:
Hash 表中数据以 Key、Value 的方式存储。
比如有一件商品,商品的ID可以定义为Key,商品的详细信息可以为value;存储的时候将 Key、Value 写入 Hash 表,读取的时候,只需要提供 Key,就可以快速查找到 Value。
Hash 表的物理存储其实是一个数组,如果我们能够根据 Key 计算出数组下标,那么就可以快速在数组中查找到需要的 Key 和 Value。
可使用余数法,使用 Hash 表的数组长度对 HashCode 求余, 余数即为Hash 表数组的下标,使用这个下标就可以直接访问得到 Hash 表中存储的 Key、Value。
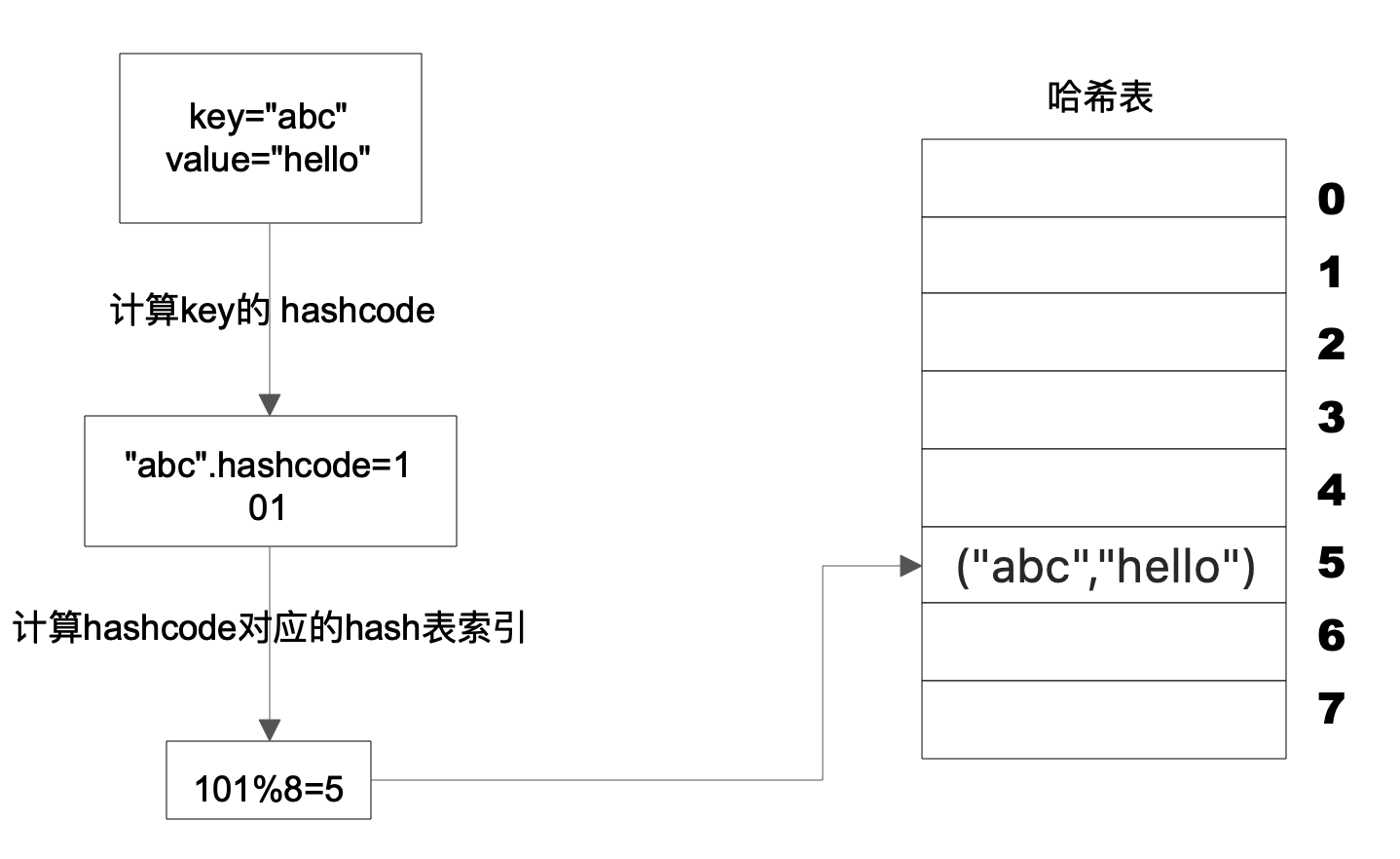
解释上述栗子:
- Key 是字符串 abc,Value 是字符串 hello;
- 计算 Key 的哈希值,得到 101 这样一个整型值;
- 然后用 101 对 8 取模,这个 8 是哈希表
数组的长度; - 101 对 8 取模余 5,这个 5 就是
数组的下标; - 这样就可以把 (“abc”,“hello”) 这样一个 Key、Value 值存储在下标为 5 的数组记录中;
如果不同的 Key 计算出来的数组下标相同怎么办?
不同的 Key 有可能计算得到相同的数组下标,这就是所谓的 Hash 冲突,解决 Hash 冲突常用的方法是链表法。
事实上,(“abc”,“hello”) 这样的 Key、Value 数据并不会直接存储在 Hash 表的数组中,因为数组要求存储固定数据类型,主要目的是每个数组元素中要存放固定长度的数据。所以,数组中存储的是 Key、Value 数据元素的地址指针。一旦发生 Hash 冲突,只需要将相同下标,不同 Key 的数据元素添加到这个链表就可以了。查找的时候再遍历这个链表,匹配正确的 Key。
Hash 表的时间复杂度为什么是 O(1)?
- 这句话并不严谨,极端情况下,如果所有 Key 的数组下标都冲突,那么 Hash 表就退化为一条链表,查询的时间复杂度是 O(N)。
四、栈:
数组和链表都被称为线性表,因为里面的数据是按照线性组织存放的,每个数据元素的前面只能有一个(前驱)数据元素,后面也只能有一个(后继)数据元素,所以称为线性表。
栈就是在线性表的基础上加了操作限制条件;简单理解就是"后进先出";
栈不需要随机访问、也不需要在中间添加、删除数据,所以可以用数组实现,也可以用链表实现。
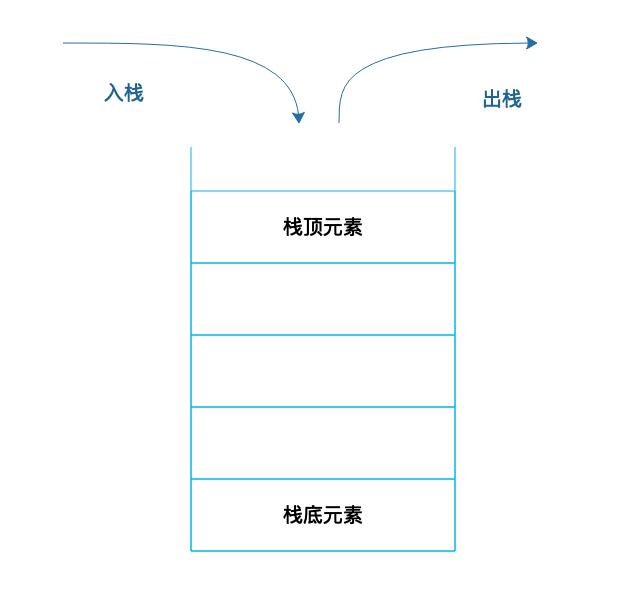
可以理解一个桶,往里面放食物,先放进去的后拿出,可能底下的食物都过期了,拿出来的都是刚放进去的食物。
五、队列:
队列也是一种操作受限的线性表,栈是后进先出,而队列是先进先出。

场景:
- 提交任务请求线程池执行,但是线程已经用完了,任务需要放入队列,先进先出排队执行;
- 线程在运行中需要访问数据库,数据库连接有限,已经用完了,线程进入阻塞队列;
六、树:
数组、链表、栈、队列都是线性表,也就是每个数据元素都只有一个前驱,一个后继。而树则是非线性表。
传统上树的遍历使用递归的方式。
参考资料
《后端技术详解38讲》
