简介
- 网络词向量方法,将网络节点嵌入到低纬向量空间
- 适用于任意类型的信息网络:无向、有向和/或加权
- 设计目标函数,同时保留了局部和全局网络结构
针对经典随机梯度下降算法的局限性,提出了一种边缘采样算法,提高了推理的效率和效果
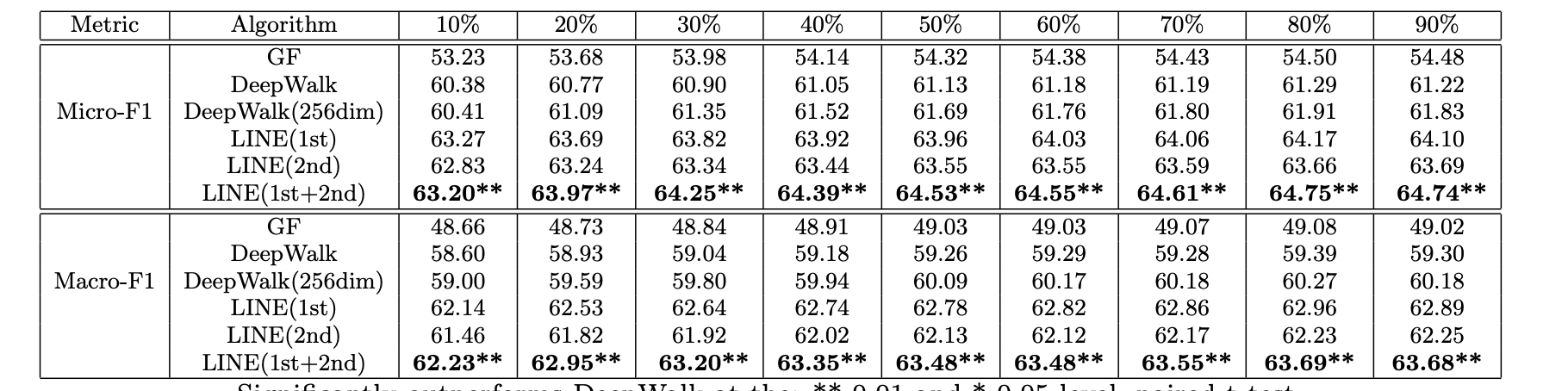
保持网络结构
一阶近似
大多数现有的图嵌入算法被设计成保持这种一阶邻近性(IsoMap和Laplacian特征映射),但是只保留一阶邻近性不足以观察保留全局网络结构,且这些方法通常依赖于求解特征矩阵向量,其复杂度与节点数目至少是二次的,使得它们处理大规模网络的效率很低。
- 二阶近似
通过顶点的共享邻域结构来确定,而不是关系强度,二阶邻近度的一般概念可以被解释为具有共享邻居的节点可能相似。
注:deepwalk保留了二阶相似但是没有保留一阶相似,且更加适用于无向图
LINE with First-order Proximity
一阶近似定义:网络中的一阶相似度是两个顶点之间的自身相似(不考虑其他顶点)。 对于由边(u,v)连接的每一对顶点,边上的权重\(W_{uv}\)表示u和v之间的相似度,如果在u和v之间没有观察到边,则它们的一阶相似度为0。
一阶近似计算
为了模拟一阶相似度,对于每个无向边\((i,j)\)
我们定义顶点\(v_i\)和\(v_j\)之间的联合概率如下:
\[ p_1(v_i,v_j)=\frac{1}{1+exp(-\overrightarrow{u}_{i}^{T}*\overrightarrow{u}_{j}^{})} \]
其中,\(u_i\)表示节点\(v_i\)对应的向量。这样就定义了一个\(V*V\)的分布\(P(.,.)\)
定义经验概率为:
\[ \hat{p_{1}}(i,j)=\frac{w_{ij}}{W} \]
其中\(W=\sum _{w_i}\)
最小化目标函数
\[ O_1=d(\hat{p_1}(.,.),\hat{p}(.,.)) \]
其中d(·,·)是两个分布之间的距离。
最后,最小化两个概率分布的KL散度,用KL散度代替d(·,·),简化公式得到:
\[ O_1=-\sum_{(i,j)\in E}^{}w_{ij}logp_1(v_i,v_j) \]
KL散度(Kullback-Leibler Divergence)也叫做相对熵,用于度量两个概率分布之间的差异程度
\[ D_{KL}(P||Q)=\sum_{i=1}^{n}P^{_{i}}log(\frac{P_i}{Q_i}) \]
- 一阶近似只适用于无向图
LINE with Second-order Proximity
- 二阶近似定义:网络中一对顶点\((u,v)\)之间的二阶相似度是它们邻近网络结构之间的相似性。 设\(p_u=(\omega _{u,1},...,\omega _u,{|v|})\)表示u与所有其他顶点的一阶相似度,则u和v之间的二阶相似度 由$ p_u\(和\)p_v$决定。 如果没有顶点与u和v都连接,则u和v之间的二阶相似度为0。
- 二阶近似计算
二阶相似度假设共享邻居的顶点彼此相似。每个顶点扮演两个角色:顶点本身和其他顶点的邻居。因此,为每个节点引入两个向量表示\(\overrightarrow{u_i}\)和\({\overrightarrow{u_i}}'\),\(\overrightarrow{u_i}\)被视为顶点时的表示,\({\overrightarrow{u_i}}'\)是当\(v_i\)被视为特定邻居时的表示。
定义\(v_j\)是\(v_i\)的邻居的概率为:
\[ p_2(v_j|v_i)=\frac{exp({{\vec{u}}'}_{i}^{T}*\vec{u}_i)}{\sum_{k=1}^{|V|}exp({{\vec{u}}'}_{k}^{T}*\vec{u}_i)} \]
其中,|V|是网络中顶点的数目。方程 (12)定义了一个条件分布\(p_2(·| vi)\),表明了低维向量空间中,各个点是顶点\(v_i\)的邻居的概率。
经验概率(网络中,各个点是\(v_i\)的邻居的概率)定义为:
\[ \hat{P_2}(v_j|v_i)=\frac{w_{ij}}{d_i} \]
其中\(d_i = \sum_{k \in N(i)}^{}W_{ik}\)
为了保持二阶相似度,同一个顶点在向量空间中的的条件分布要接近在网络中的条件分布。引入λi表示网络中顶点的重要程度。最小化目标函数(14)
\[ O_2=\sum_{i /in V}^{}\lambda _{i}d(\hat{p_2}(.|v_i),p_2(.|v_i)) \]
将设置为顶点i的度数,即\(\lambda _i\)= \(d_i\),用KL散度代替\(d(.,.)\),简化得
\[ O_2=-\sum_{(i,j) /in E}^{} w_{ij}logp_2(v_j|v_i) \]
Combining first-order and second-order proximities
- 采用分别训练一阶相似度模型和二阶相似度模型,然后将学习的两个向量表示连接成一个更长的向量。
- 更适合的方法是共同训练一阶相似度和二阶相似度的目标函数,比较复杂,没有实现。
Model optimization
优化目标(12)的计算开销比较大,所以对模型进行优化
- 负采样:根据每个边\((i,j)\)的噪声分布对多个负边进行采样
- 边采样(解决加权边缘随机梯度下降的局限性)
采用异步随机梯度下降算法(ASGD)来进行优化 。如果边\((i,j)\)被采样,则对应的梯度将被计算为:
\[ \frac{\partial O_2}{\partial \vec{u}_{i}}=w_{ij}*\frac{\partial logp_2(v_j|v_i)}{\partial \vec{u}_{i}} \]
因为梯度计算过程中,要乘以边的权重,所以当权重的变化范围很大时,就会导致梯度变化大,很难找到合适的学习率。
解决办法:将边转换为无权边,权重为$\omega \(的边转换为\)w$个无权边
问题:增加内存和参数
优化方法:现在网络中,对边进行采样,采样的概率与边的权重成正比;再将采样后的边展开成无权边。
Line中的边采样的方法采用的是别名抽样法:https://blog.csdn.net/haolexiao/article/details/65157026
实验
实验数据

实验及实验结果
词类比:
给定一个单词对(a,b)和一个单词c,任务的目的是发现一个单词d,使得c和d之间的关系类似于a和b之间的关系。例woman-man = queen-king,即woman-man+king=queen。实验中用到了两类词类比:语义和句法,例:woman-man = queen-king是语义上类比,is good=are bed是句法上类比。
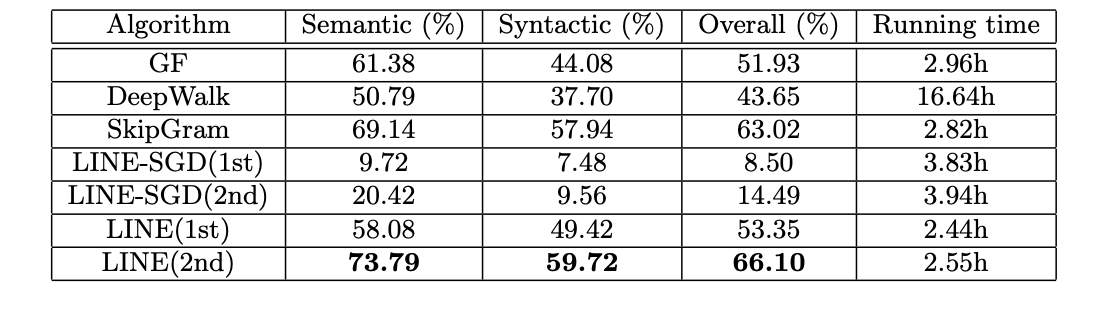
2.文档分类
取文档中的单词向量表示的平均值作为文档向量。在实验中,随机抽取不同百分比的有标签的文件进行训练,其余的则用于评估, 结果在10次不同的运行中取平均值。。分类指标使用了Micro-F1和Macro-F1。
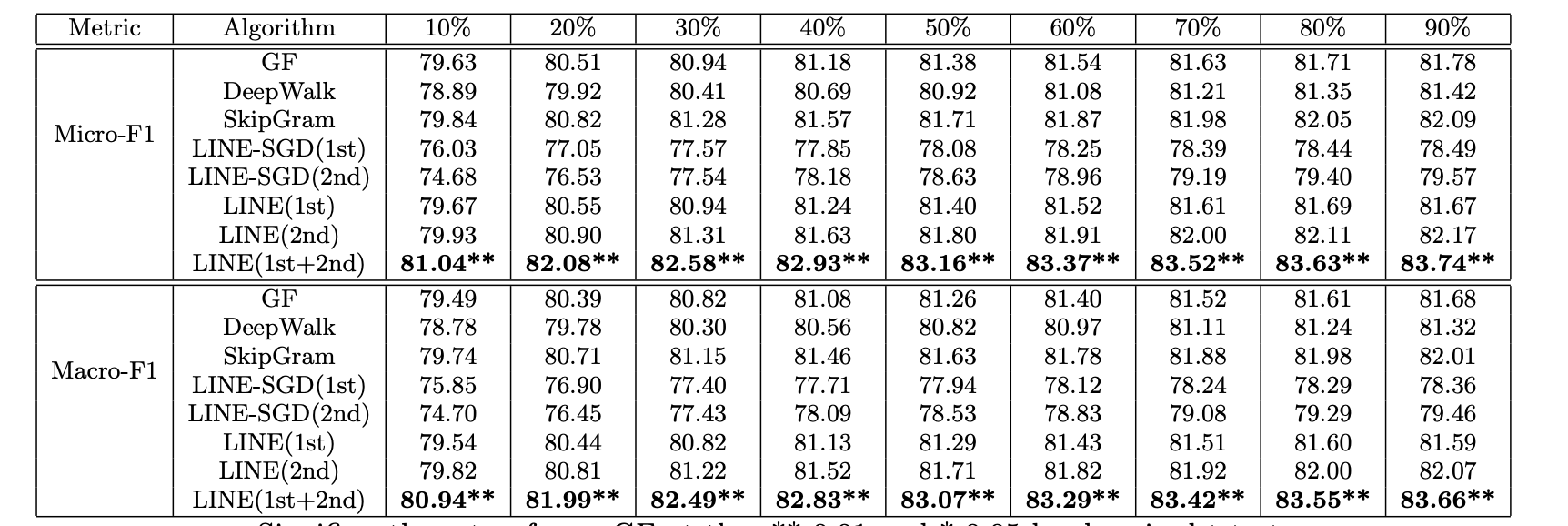
3.多标签分类