一、通过下面代码跟踪XmlBeanFactory初始化过程
import org.junit.Assert;
import org.springframework.beans.factory.BeanFactory;
import org.springframework.beans.factory.xml.XmlBeanFactory;
import org.springframework.context.support.ResourceBundleMessageSource;
import org.springframework.core.io.ClassPathResource;
public class BeanFactoryTest {
@SuppressWarnings("deprecation")
public void testSimpleLoad() {
BeanFactory beanFactory = new XmlBeanFactory(new ClassPathResource("springMVC-servlet/xml"));
ResourceBundleMessageSource messageSource = (ResourceBundleMessageSource) beanFactory.getBean("messageSource");
Assert.assertTrue(messageSource != null);
}
}其中
BeanFactory beanFactory = new XmlBeanFactory(new ClassPathResource("springMVC-servlet/xml"));上述代码时序图如下
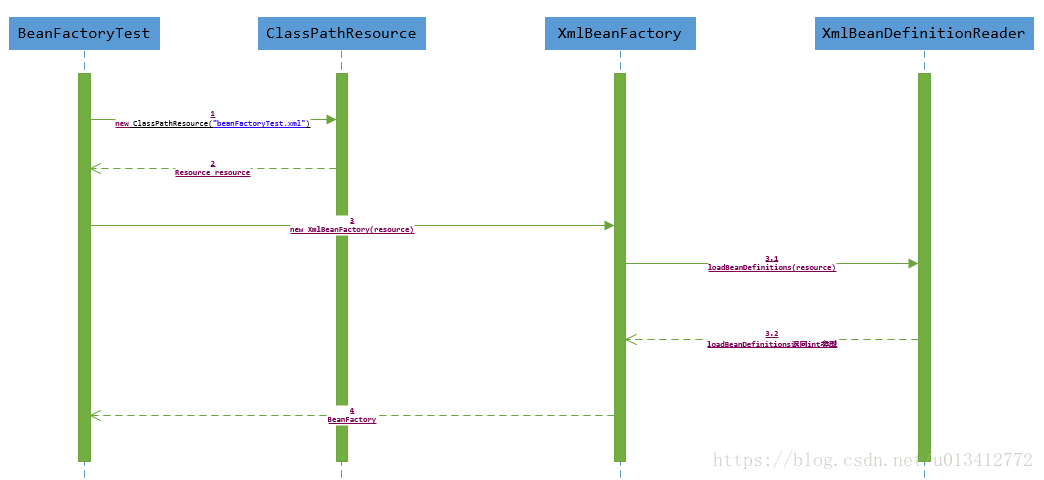
时序图从BeanFactoryTest测试类开始,通过时序图可以大概看出整个逻辑顺序。在测试的BeanFactoryTest中首先调用ClassPathResource的构造方法来构造Resource资源文件的实例对象,这样后续的资源处理就可以用Resource提供的各种服务来操作了。当我们有了Resource后就可以进行XmlBeanFactory的初始化了。那么Resource资源是如何封装的?请参照:
在了解了Spring中将配置文件封装后Resource类型的实例方法后,继续XmlBeanFactory的初始化过程了,XmlBeanFactory的初始化有若干个方法,Spring中提供了很多的构造函数,在这里分析的是使用Resource实例作为构造函数参数的办法,代码如下:
@Deprecated
@SuppressWarnings({"serial", "all"})
public class XmlBeanFactory extends DefaultListableBeanFactory {
private final XmlBeanDefinitionReader reader = new XmlBeanDefinitionReader(this);
/**
* Create a new XmlBeanFactory with the given resource,
* which must be parsable using DOM.
* @param resource XML resource to load bean definitions from
* @throws BeansException in case of loading or parsing errors
*/
public XmlBeanFactory(Resource resource) throws BeansException {
this(resource, null);//调用下面的构造方法
}
/**
* Create a new XmlBeanFactory with the given input stream,
* which must be parsable using DOM.
* @param resource XML resource to load bean definitions from
* @param parentBeanFactory parent bean factory
* @throws BeansException in case of loading or parsing errors
*/
public XmlBeanFactory(Resource resource, BeanFactory parentBeanFactory) throws BeansException {
super(parentBeanFactory);
this.reader.loadBeanDefinitions(resource);
}
}在上面的代码中:
public XmlBeanFactory(Resource resource, BeanFactory parentBeanFactory) throws BeansException;才是资源加载的真正实现。依据时序图可以中提到的XmlBeanDefinitionReader加载数据就是在这里完成的,但是在XmlBeanDefinitionReader加载数据前海油一个调用父类构造函数初始化的过程:
super(parentBeanFactory);跟踪代码到父类AbstractAutowireCapableBeanFactory的构造函数中
public AbstractAutowireCapableBeanFactory() {
super();
ignoreDependencyInterface(BeanNameAware.class);
ignoreDependencyInterface(BeanFactoryAware.class);
ignoreDependencyInterface(BeanClassLoaderAware.class);
}这里有必要说一下ignoreDependencyInterface方法。ignoreDependencyInterface的主要功能是忽略给定接口的自动装配功能,那么,这样做的目的是为什么?会产生什么样的效果。
举例来说,当A中有属性B,那么当Spring在获取A的bean的时候如果其属性也有B还没有初始化,那么Spring会自动初始化B,这也是Spring提供的一个重要特性。但是,某些情况下,B不会被初始化,其中的一种情况就是B实现了BeanNameAware接口。Spring中是这样介绍的:
自动装配时忽略给定的依赖接口,典型应用就是通过其他方式解析Application上下文注册依赖,类似于BeanFactory通过BeanFactoryAware进行注入或者ApplicationContext通过ApplicationContextAware进行注入。
二、 XmlBeanDefinitionReader类中loadBeanDefinitions(Resource resource)方法
public int loadBeanDefinitions(Resource resource) throws BeanDefinitionStoreException;先来看一下loadBeanDefinitions函数执行时序图
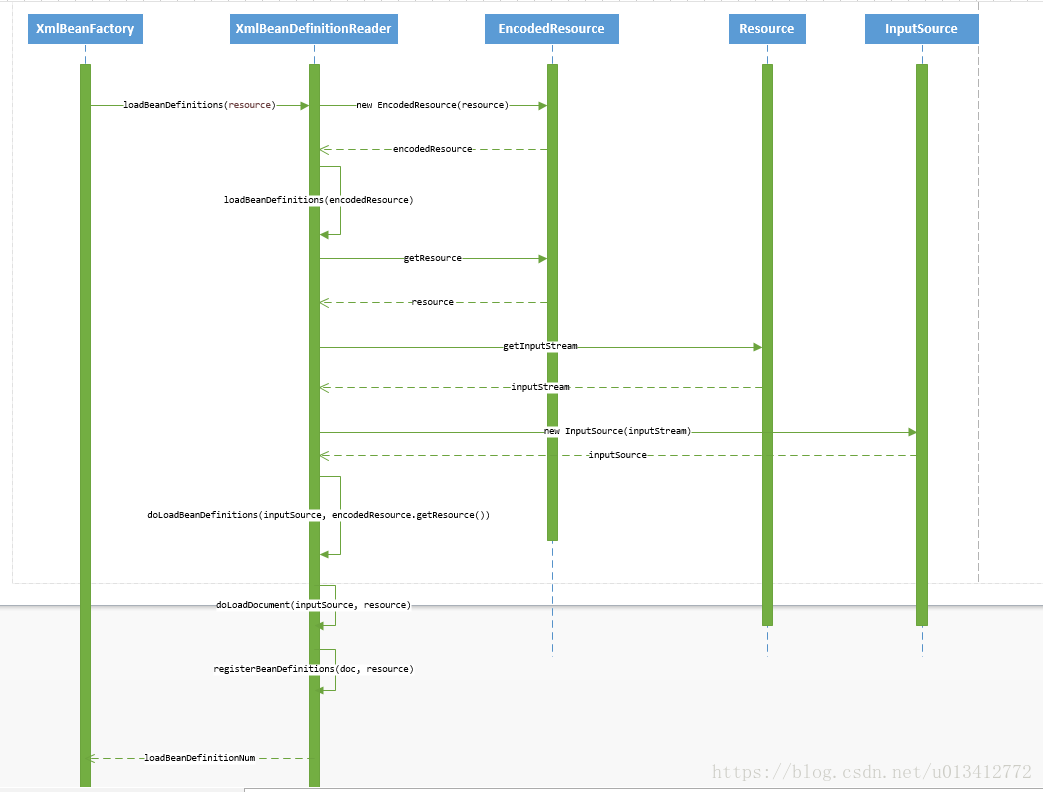
从上面的时序图中可以看到整个处理流程如下:
- 封装资源文件。当进入XmlBeanDefinitionReader后首先对参数Resource使用EncodedResource类进行封装。
- 获取输入流。从Resource中获取对应的InputStream并构造InputSource。
- 通过构造的InputSource实例和Resource实例继续调用函数doLoadBeanDefinitions。
loadBeanDefinitions函数具体的实现过程如下:
/**
* Load bean definitions from the specified XML file.
*
* @param resource the resource descriptor for the XML file
* @return the number of bean definitions found
* @throws BeanDefinitionStoreException in case of loading or parsing errors
*/
@Override
public int loadBeanDefinitions(Resource resource) throws BeanDefinitionStoreException {
return loadBeanDefinitions(new EncodedResource(resource));
}其中EncodedResource的作用是什么?
通过名称可以大概推断出这个类主要的作用是用于对资源文件的编码处理。其中的主要逻辑体现在getReader方法中,当设置了编码属性的时候Spring会使用响应的编码作为输入流的编码:
/**
* Open a {@code java.io.Reader} for the specified resource, using the specified
* {@link #getCharset() Charset} or {@linkplain #getEncoding() encoding}
* (if any).
* @throws IOException if opening the Reader failed
* @see #requiresReader()
* @see #getInputStream()
*/
public Reader getReader() throws IOException {
if (this.charset != null) {
return new InputStreamReader(this.resource.getInputStream(), this.charset);
}
else if (this.encoding != null) {
return new InputStreamReader(this.resource.getInputStream(), this.encoding);
}
else {
return new InputStreamReader(this.resource.getInputStream());
}
}在上面的代码构造了一个由编码的InputStreamReader。当构造好encodedResource对象后,再次转入了可复用方法loadBeanDefinitions(new EncodedResource(resource))。这个方法内部才是真正的数据准备阶段,这也是时序图所描述的逻辑:
public int loadBeanDefinitions(EncodedResource encodedResource)
throws BeanDefinitionStoreException {
Assert.notNull(encodedResource, "EncodedResource must not be null");
if (logger.isInfoEnabled()) {
logger.info("Loading XML bean definitions from "
+ encodedResource.getResource());
}
// 通过属性来记录已经加载的资源
Set<EncodedResource> currentResources = this.resourcesCurrentlyBeingLoaded.get();
if (currentResources == null) {
currentResources = new HashSet<EncodedResource>(4);
this.resourcesCurrentlyBeingLoaded.set(currentResources);
}
if (!currentResources.add(encodedResource)) {
throw new BeanDefinitionStoreException("Detected cyclic loading of "
+ encodedResource + " - check your import definitions!");
}
try {
// 从EncodedResource中获取已经封装的Resource对象并再次从Resource中获取其中的inputStream
InputStream inputStream = encodedResource.getResource().getInputStream();
try {
// InputSource这个类并不是来源于Spring,他的全路径为:org.xml.sax.InputSource
InputSource inputSource = new InputSource(inputStream);
if (encodedResource.getEncoding() != null) {
inputSource.setEncoding(encodedResource.getEncoding());
}
// 真正进入了逻辑核心服务
return doLoadBeanDefinitions(inputSource, encodedResource.getResource());
}
finally {
inputStream.close();
}
}
catch (IOException ex) {
throw new BeanDefinitionStoreException(
"IOException parsing XML document from "
+ encodedResource.getResource(), ex);
}
finally {
currentResources.remove(encodedResource);
if (currentResources.isEmpty()) {
this.resourcesCurrentlyBeingLoaded.remove();
}
}
}再次整理一下数据准备阶段的逻辑,首先对传入的resource参数做封装,目的是考虑到Resource可能存在编码要求的情况,其次,通过SAX读取XML文件的方式来准备InputSource对象,最后将准备的数据通过参数传入真正的核心处理部分:doLoadBeanDefinitions(inputSource, encodedResource.getResource());
protected int doLoadBeanDefinitions(InputSource inputSource, Resource resource)
throws BeanDefinitionStoreException {
try {
Document doc = doLoadDocument(inputSource, resource);
return registerBeanDefinitions(doc, resource);
}
catch (BeanDefinitionStoreException ex) {
throw ex;
}
catch (SAXParseException ex) {
throw new XmlBeanDefinitionStoreException(resource.getDescription(), "Line "
+ ex.getLineNumber() + " in XML document from " + resource
+ " is invalid", ex);
}
catch (SAXException ex) {
throw new XmlBeanDefinitionStoreException(resource.getDescription(),
"XML document from " + resource + " is invalid", ex);
}
catch (ParserConfigurationException ex) {
throw new BeanDefinitionStoreException(resource.getDescription(),
"Parser configuration exception parsing XML from " + resource, ex);
}
catch (IOException ex) {
throw new BeanDefinitionStoreException(resource.getDescription(),
"IOException parsing XML document from " + resource, ex);
}
catch (Throwable ex) {
throw new BeanDefinitionStoreException(resource.getDescription(),
"Unexpected exception parsing XML document from " + resource, ex);
}
}
protected Document doLoadDocument(InputSource inputSource, Resource resource)
throws Exception {
return this.documentLoader.loadDocument(inputSource, getEntityResolver(),
this.errorHandler, getValidationModeForResource(resource),
isNamespaceAware());
}在上面的代码中只做了三件事情:
- 获取对XML文件的验证模式
- 加载XML文件,并得到对应的Document。
- 依据返回的Document注册Bean信息。