offset
消息队列里的数据,是不会因为消费而被删除的,默认保存7天或1G;
patition和Consumer都维护这自己的offset;
消费者默认从自己记录的offset开始消费;
想要从Partition最早记录开始消费,需要两个条件:(API)
- 设置AUTO_OFFSET_RESET_CONFIG为 "earliest"
- 消费者换组,无法获得自己的offset;
- 或者消费者当前的offset的数据已经不存在了;
(图画错了,消费者只能消费到offset 8,这里会在kafka的保持数据一致中写到)

offset提交机制
消费者的offset是由kafka来维护的,存储在zookeeper的文件目录中;
每次消费者消费完成都将自己消费到的offset提交给kafka;
分为:
自动提交:存在提交延迟
// 开启自动提交,必须设置消费组 props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true"); // 自动提交延迟 props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000"); // 设置消费组 props.put(ConsumerConfig.GROUP_ID_CONFIG, "c2");- 提交延迟高:已经写入数据,还没提交,机器故障,恢复之后,会重新读取数据,造成重复数据;
- 提交延迟低:数据还没读完,已经提交完成,这时候故障,恢复之后就会丢数据;
手动提交;
分为同步提交,异步提交
// 关闭自动提交 props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false"); // 异步提交:提交线程和poll线程,异步 kafkaConsumer.commitAsync(); // 同步提交:阻塞,提交成功,才会下一次数据拉取 kafkaConsumer.commitSync();
topic消息存储
在server.properties中此配置:
log.dirs=/tmp/kafka-logs此目录下,会存放topic-partition目录,内部存放着partition的消息;
[root@spark001 test-0]# ll
-rw-r--r--. 1 root root 10485760 1月 00000000000000000000.index
-rw-r--r--. 1 root root 1893 1月 00000000000000000000.log
-rw-r--r--. 1 root root 10485756 1月 00000000000000000000.timeindex
-rw-r--r--. 1 root root 8 1月 leader-epoch-checkpoin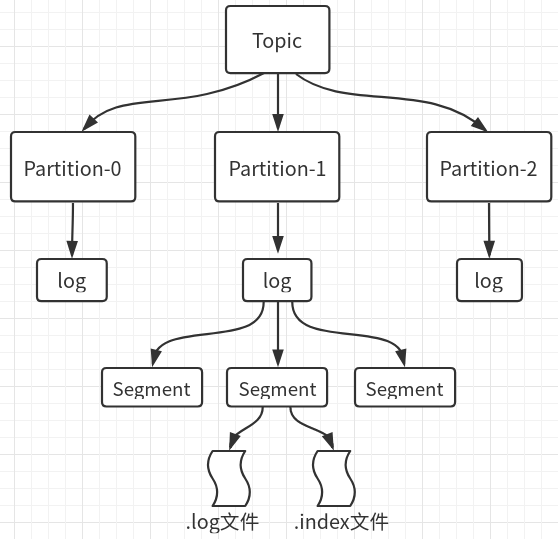
- 一个Topic分为多个Partitions,每个Partition分为多个Segment片段,一个Segment片段对应两个文件:.log文件(只存放消息),.index文件(索引文件)
- segment只是一个概念,代表了index文件和log文件的总称;
- .index文件,存放offset 和对应的消息所在.log文件的偏移量(有点绕,画了看图)
- .log文件,存放具体消息内容和相对于此文件的偏移量;

如何找到message
首先找到segment,通过文件名,根据二分查找,可以找到offset所在的segment;
比如此partition有如下segment:
segment1:00000000000000.index 表示此segment存放0~123的消息
segment1:00000000000123.index 表示此segment存放124~的消息
找到了segment之后,查找.index文件内offset,对应得到message在log文件内的偏移量;
到log文件,找到message,返回;
消费者offset存储
查看offset
$ kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list localhost:9092 --topic bigdata
bigdata:0:119 # 分区0
bigdata:1:129 # 分区1java API拿offset:通过拉取的记录,可以拿到offset
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer(props);
ConsumerRecords<String, String> records = kafkaConsumer.poll(100);
for (ConsumerRecord<String, String> consumerRecords : records) {
System.out.println("offset:"+ String.valueOf(consumerRecords.offset()));
}