随笔:随着互联网行业的飞速发展,互联网行业可谓日新月异,然而在繁华的背后,大多的互联网公司对于网络安全还是处于无重视,不作为的阶段,而作为一个程序员,如果也对信息安全视而不见的话,那将是这个公司的噩梦,给这个公司带来巨大的隐形风险,由于回首新到的所在公司已经遭受过这种风险,所以作为一名程序员,回首也不得不重视起我们平时不以为然的信息安全,一个好的程序员不应只会敲代码,更应将威胁与风险尽自己最大可能降低到最低,所以就有了这个版块,由于初识安全,所以回首也就跟大家分享一下回首的学习内容,希望跟大家一起进步,让更多的人关注网络安全,为互联网行业尽一份绵薄之力。
声明:本文采摘自阿里巴巴集团首席架构师 王坚先生的-《白帽子讲Web安全》一书,本文不做任何商业活动,旨在宣扬王坚先生的安全精神,由于本文精简了大部分内容,只采取部分精简片段,如有想从头好好学习的朋友,请自行购买该书,该书内容丰富有趣,深刻的反应了中国互联网行业背后的安全攻防,引人入胜,十分值得一读。
安全的三要素:
秘密性,完整性,可用性。
机密性要求保护数据内容不能泄露,加密是实现机密性要求的常见手段。
完整性要求保护数据内容是完整,没有被篡改的,常见的保持一致性的技术手段是数字签名。
可用性要求被保护资源是随需而得。
假设一个停车场里有100个车位,在正常情况下,可以停100辆车。但是某一天,有个坏人搬了100块大石头,把每个停车位都占用了,停车场无法再提供正常服务。在安全领域中这种攻击叫做拒绝服务攻击,简称DOS(Denial of Serivice)。拒绝服务攻击破坏的是安全的可用性。
如何实施安全评估:
安全评估可以简单分为四个阶段:资产等级划分,威胁分析,风险分析,确认解决方案。这个实施的过程是层层递进的,前后之间有因果关系。
资产等级划分:
互联网安全的核心问题,是数据安全的问题!!!。
对互联网公司拥有的资产进行等级划分,就是对数据做等级划分,明确公司最重要的资产是什么,每个部门最看重的数据是什么,通过访谈的形式,安全部门才能熟悉,了解公司的业务,公司所拥有的数据,以及不同数据的重要程度,为后续的安全评估过程指明方向。当做完资产登记划分后,对要保护的目标已经有了一个大概的了解,接下来就是要划分信任域和信任边界了。通常最简单的划分方式,就是从网络逻辑上来划分。
威胁分析:
在安全领域里,我们把可能造成危害的来源称为威胁(Threat),而把可能会出现的损失称为风险(Risk)。风险一定是和损失联系在一起的。
什么是威胁分析?威胁分析就是把所有的威胁都找出来。一般采用头脑风暴法,或是使用一个模型,帮助我们去想,在哪些方面可能会存在威胁,这个过程能够避免遗漏,这就是威胁建模。
STRIDE模型是最早由微软提出的,STRIDE是由6个单词的首字母缩写,告诉我们可以从这6个方面去考虑。
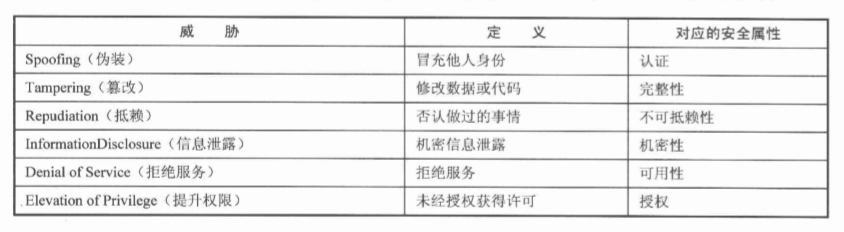
风险分析:
风险有以下因素组成:
Risk = Probability * Damage Potential
影响风险高低的因素,除了造成损失的大小外,还需要考虑到发生的可能性。
DREAD模型,它也是由微软提出的,DREAD也是几个单词的首字母缩写,它指导我们应该从哪些方面去判断一个威胁程度的风险程度。
等级: 高(3) 中(2) 低(1)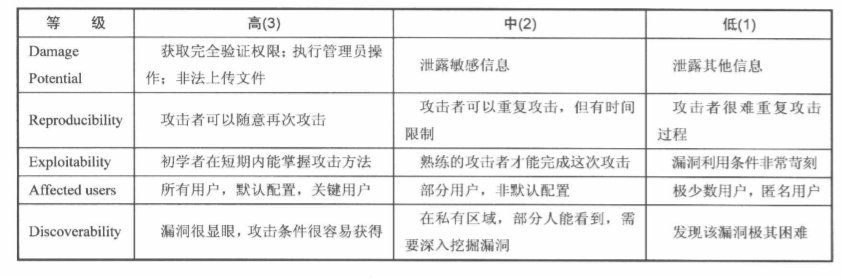
在DREAD模型里,每一个因素都可以分为高,中,低三个等级。在上表中,高,中,低三个等级分别以3,2,1的分数代表其权重数值,因此我们就可以具体算出某一个威胁的风险值。
高威: 12 - 15分 中威: 8 - 11分 低威: 0 - 7分
安全设计方案:
安全评估的产出物,就是安全解决方案。解决方案一定要有针对性,这种针对性是由资产登记划分,威胁分析,风险分析等阶段的结果给出的。
一个优秀的安全方案应该具备以下特点:

白帽子兵法:
在设计安全方案时,最基本也最重要的原则就是“Secure by Default”。在做任何安全设计时,都要牢牢记住这个原则。“Secure by Default”原则,也可以归纳为白名单、黑名单的思想。如果更多的使用白名单,那么系统就会变得更安全。
黑名单、白名单:
比如,在制定防火墙的网络访问控制策略时,如果网站只提供Web服务,那么正确的作法是只允许网站服务器的80和443端口对外提供服务,屏蔽除此之外的其他端口。这是一种“白名单”的作法:
又比如,在网站的生产环境服务器上,应该限制随意安装软件,而需要制定统一的软件版本规范,以防止因为安装了不熟悉的软件而导致的一些漏洞,从而扩大攻击面。
再比如,再Web安全中,对处理用户提交的富文本时,考虑到XSS的问题,需要做安全检查。常见的XSS Filter一般是先对用户输入的HTML原文作HTML Parse,解析成标签对象后,再针对标签匹配XSS的规则。这个规则列表就是一个黑白名单。如果选择白名单的思想,就能避免这种问题,如只允许用户输入诸如特点的a标签,img标签等。
选择白名单的思想,给予白名单来设计安全方案,其实就是信任白名单是好的,是安全的,但是一旦这个信任基础不存在了,那么安全就荡然无存。
在Flash跨域访问请求里,是通过检查目标资源服务器端的crossdomain.xml文件来验证是否允许客户端的Flash跨域发起请求的,它使用的是白名单的思想。指定了只允许特点域的Flash对本域发起请求。可是如果这个信任列表中的域名变得不可信了,那么问题就会随之而来。比如:
<cross-domain-policy>
<allow-access-from domain="*">
</cross-domain-policy>
通配符“*”,代表来自任意域的Flash都能访问本域的数据,因此就造成了安全隐患。所以在选择使用白名单时,需要注意避免出现类似通配符“*”的问题。
最小权限原则
Secure By Default的另一层含义就是“最小权限原则”。最小权限原则也是安全设计的基本原则之一。最小权限原则要求系统只授予主体不必要的权限,而不要过度授权,这样能有效地减少系统、网路、应用、数据库出错的机会。
比如在Linux系统中,一种良好的操作习惯是使用普通账户登录,在执行需要root权限的操作时,在通过sudo命令完成。这样能最大化地降低一些误操作导致的风险;同时普通账户被盗用后,与root账户被盗用所导致的后果是完全不同的。
在使用最小权限原则时,需要认真梳理业务所需要的权限,在很多时候,开发者并不会意识到业务授权用户的权限过高。在通过访谈了解业务时,可以多设置一些反问句,比如:您确定您的程序一定需要访问Internet吗?通过此类问题,来确定业务所需的最小权限。
纵深防御原则
与Secure by Defalut 一样,Defense in Depth(纵深防御)也是设计安全方案时的重要指导思想。
纵深防御包含两层含义:首先,要在各个不同层面、不同方面实施安全方案,避免出席那疏漏,不同安全方案之间需要相互配合,构成一个整体;其次,要在正确的地方做正确的事情,既:在根本解决问题的地方实施针对性的安全方案。
在常见的入侵案例中,大多数利用WEB应用的漏洞,攻击者先获得一个低权限的webshll,然后通过低权限 webshell上传更多的文件,并尝试执行更高权限的系统命令,尝试在服务器上提升权限为root;接下来攻击者再进一步尝试渗透内网,比如数据库服务器所在的网段。
在这类入侵案例中,如果在攻击过程中的任何一个环节设置有效的防御措施,都有可能导致入侵过程功亏一篑,但是世上没有万能灵药,也没有哪种解决方案能解决所有问题,因此非常有必要将风险分散到系统的各个层面。就入侵的防御来说,我们需要考虑的可能有Web应用安全、OS系统安全、数据库安全、网络环境安全等。在这些不同层面设计的安全方案,将共同组成防御体系,这也就是纵深防御的思想。
纵深防御的第二层含义,是要在正确的地方做正确的事情。它要求我们深入理解威胁的本质,从而做出正确的应对措施。
在XSS防御技术的发展过程中,曾经出现过几种不同的解决思路,知道最近几年的XSS的防御思路才逐渐成熟和统一。例如从最早的过滤输入中特殊符号,到区分富文本和非富文本encode非富文本,再到对富文本开始做语法树分析,知道最后的综合方案。
数据与代码分离原则
另一个重要的原则是数据与代码分离原则。这一原则广泛适用于各种由于“注入”而引发安全问题的场景。
实际上,缓存区溢出,也可以认为是程序违背了这一原则的后果--程序在栈或者堆中,将用户数据当做代码执行,混淆了代码与数据的边界,从而导致安全问题的发生。
在Web安全中,有“注入”引起的问题比比皆是,入XSS,SQL Injection、CRLF Injection、X-Path Injection等。此类问题均可以根据“数据与代码分离原则”设计出真知安全的解决方案,因为这个原则抓住了漏洞形成的本质原因。
不可预测下原则
前面介绍的几条原则:Secure By Default,是时刻要牢记的总则;纵深防御,是要更全面、更正确地看待问题;数据与代码分离,是从漏洞成因上看问题;接下来要讲的“不可预测性”原则,则是从客服攻击方法的角度看问题。
微软的Windows系统用户多年来深受缓存区溢出之苦,因此微软在Windows的新版本中增加了许多对抗缓存区溢出等内存攻击的功能。微软无法要求运行在系统中的软件没有漏洞,因此它采取的作法是让漏洞的攻击方法失效。比如,使用DEP来保证堆栈不可执行,使用ASLR让进程的栈基址随机变化,从而使攻击程序无法准确地猜测到内存地址,大大提高了攻击的门槛。经过实践检验,证明微软的这个思路确实是有效的--即使无法修复code,但是如果能够使得攻击的方法无效,那么也可以算是成功的防御。
微软使用的ASLR技术,在叫较新版本的Linux内核中也支持。在ALSR的控制下,一个程序每次启动时,其进程的栈基址都不相同,具有一定的随机性,对于攻击者来说,这就是“不可预见性”。
不可预见性(Unpredictable),能有效地对抗基于篡改、伪造的攻击。我们看看如下这个场景:
假设一个内存管理系统中的文章序号,是按照数字升序排列的,比如 ID = 1000 , ID = 1002, ID = 1003 ······
这样的顺序,使得攻击者能够很方便地遍历出系统中的所有文章编号:找到一个整数,依次递增即可。如果攻击者想要批量删除这些文章,写个简单的脚本:
for(i=0;i<100000;i++){
Delete(url +"?id="+i);
}
就可以很方便地达到目的。但是如果该内容管理系统使用了“不可预见性”原则,将ID的值变的不可预测,会产生什么结果呢?
id=asdasdasdasd,id=dasdasdasdasdas,id=asdasdasdasdasda······
id的值变得完全不可预测了,攻击者在想批量删除文章,只能通过爬虫把所有的页面ID全部抓取下来,再一一进行分析,从而提高了攻击的门槛。
不可预测性原则,可以巧妙地用在一些敏感数据上。比如在CSRF的防御技术中,通常会使用一个token来进行有效防御。这个token能成功防御CSRF,就是因为攻击者在实施CSRF攻击的过程中,是无法提前预支这个token值的,因此要求token足够复杂时,不能被攻击者猜测到。
不可预测性的实现往往需要用到加密算法、随机数算法、哈希算法,好好使用这条原则,在设计安全方案时往往会事半功倍。
小结:
本章内容归纳了作者王坚先生对于安全世界的认识和思考,揭示了安全问题的本质,以及应该如何展开安全工作,最后总结了设计安全方案的几种思路和原则。在后续的章节中,将继续揭示web安全的方方面面,并深入理解攻击原理和正确的解决之道--我们会面对各种各样的攻击,解决方案为什么要这样设计,为什么这最合适?这一切的出发点,都可以在后续的学习笔记中看到本质的原有。
安全是一门朴素的学问,也是一种平衡的艺术。无论是传统安全,还是互联网安全,其内在的原理都是一样的。我们只需要抓住安全问题的本质,之后无论遇到任何安全问题(不仅仅局限web安全或互联网安全),都会无往而不胜,因为我们已经真正地懂得了如何用安全的严管来看待这个世界!