其实,写这个是为了督促自己看书……然后 ……其实没有然后了,人一松懈下来,就……ε=(´ο`*)))唉
第五章 字典和结构化数据
①字典数据类型
像列表一样,“字典”是许多值的集合。但不像列表的下标,字典的索引可以使用许多不同数据类型,不止是整数。字典的索引被称为“键”,键及其关联的值被称为“键-值”对。
在代码中,字典输入时带花括号{}。在交互环境中输入一下代码:
>>>myCat={'size':'fat','color':gray',disposition':'loud'}
这将给字典赋给myCat变量。这个字典的键是'size'、'color'、'disposition'。这些键相应的值是'fat'、'gray'和‘loud'。可以通过他们的键访问这些值:
>>>myCat['size'] 'fat' >>'My cat has '+myCat['color']+' fur.' 'My cat has gray fur.'
字典仍然可以用整数值作为键,就像列表用整数值作为下标一样,但是不要求一定要从0开始,可以是任何数字。
——摘自书81~82页
------------------------那个……再歪个楼-----------------------
昨天在做这题的时候:

发现,真的很多东西,乍一看很好解决,真到自己写的时候,就……
比如,怎么去掉字符串中间的空格,怎么把大写字母转换为小写字母,怎么统计字母出现的次数……种种难题,使我到现在都没把这题A掉,超级蓝瘦(T ^ T)。
不过是真的觉得PY真是黑科技,一行代码可以实现好多功能。
……
又跑题了,对,是要记录一下,这些功能怎么实现。
Ⅰ
首先,去掉字符串中间的空格。
string=' soft kitty warm kitty little ball of fur~~ happy kitty sleepy kitty pur pur pur~~ '
先是字符串↑,我们发现,字符串左右两边都有空格
⑴去掉左边的空格——lstrip
string=' soft kitty warm kitty little ball of fur~~ happy kitty sleepy kitty pur pur pur~~ ' string.lstrip() print(string)
输出:
soft kitty warm kitty little ball of fur~~ happy kitty sleepy kitty pur pur pur~~ #右边一直到这里哦
⑵去掉右边的空格——rstrip
与上面的用法相同:字符串名.函数名()#string.rstrip()
⑶去掉左右两边的空格——strip
与上面的用法相同:字符串名.函数名()#string.strip()

⑷去掉中间的空格
法一:split()
split():通过指定分隔符对字符串进行切片,如果参数num 有指定值,则仅分隔 num 个子字符串
string=' soft kitty warm kitty little ball of fur~~ happy kitty sleepy kitty pur pur pur~~ ' print(string.split())
output:
['soft', 'kitty', 'warm', 'kitty', 'little', 'ball', 'of', 'fur~~', 'happy', 'kitty', 'sleepy', 'kitty', 'pur', 'pur', 'pur~~']
当然,还可以自定义操作,见点击打开链接
In[3]: a = 'dfdfd*dfjdf**fdjfd*22*'
In[4]: a
Out[4]: 'dfdfd*dfjdf**fdjfd*22*'
In[5]: a.split('*')
Out[5]: ['dfdfd', 'dfjdf', '', 'fdjfd', '22', '']
In[6]: a.split('*',2)
Out[6]: ['dfdfd', 'dfjdf', '*fdjfd*22*']
法二:replace
>>> a = 'hello world'
>>> a.replace(' ', '')
'helloworld'
法三:使用正则表达式
>>> import re
>>> strinfo = re.compile()
>>> strinfo = re.compile(' ')
>>> b = strinfo.sub('', a)
>>> print(b)
helloworld
法四:先转换成列表……在列表中删除……
法五:循环删除……
哭唧唧,那么多方法,最后还是A不了题
Ⅱ
大小写转化
这个简单,见百度知道……点击打开链接
可以直接通过str类的swapcase方法可以快速实现大写便小写、小写变大写的功能。 In [1]:s='Baidu Zhidao' In [2]:s.swapcase() Out[2]:'bAIDU zHIDAO' 与swapcase类似的还有lower和upper方法,它们分别实现将字符串全部变为小写和全部变为大写的功能。 In [3]: s.upper() Out[3]:'BAIDU ZHIDAO' In [4]: s.lower() Out[4]:'baidu zhidao'
Ⅲ
统计字母出现次数(终于讲到字典了,✿✿ヽ(°▽°)ノ✿)
先说单个字母,就是只统计一个字母的那种
string=input()
s=string.lower()
emm=list(s.replace(' ',''))
emm.sort()
print(emm)
num=emm.count(emm[0])
print(emm[0],num)
↑这个是昨天写的代码的修改版,当然,还是不对,就是展示一下count函数的
>>> '1,2,3'.count(',')<br />
2<br />
>>> 'Hello world'.count('l')<br />
3<br />
酱紫,就可以了。大家看,那个,即使已经是列表了,也是可以用的。
然后是统计很多字符:
from collections import Counter
string=input()
s=string.lower()
emm=list(s.replace(' ',''))
print (Counter(emm).most_common(4))
>>> string = 'hello world'
>>> { a:string.count(a) for a in set(string.replace(' ','')) }
{'h': 1, 'e': 1, 'w': 1, 'l': 3, 'o': 2, 'd': 1, 'r': 1}
用的是字典推导式和str自带的统计方法str.count
作者:匿名用户
链接:https://www.zhihu.com/question/67528074/answer/254847319
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
点击打开链接
Ⅳ
判断是字母还数字
str_1 = "123" str_2 = "Abc" str_3 = "123Abc" #用isdigit函数判断是否数字 print(str_1.isdigit()) Ture print(str_2.isdigit()) False print(str_3.isdigit()) False #用isalpha判断是否字母 print(str_1.isalpha()) False print(str_2.isalpha()) Ture print(str_3.isalpha()) False #isalnum判断是否数字和字母的组合 print(str_1.isalpha()) False print(str_2.isalpha()) False print(str_1.isalpha()) Ture
----------------------------------楼好像歪了不少----------------------------
#希望大家还能记得是在第五章,要继续讲一讲字典……
#刚刚翻了一下书,还有好多啊,好绝望,不想写了,但是已经立了flag了,哭唧唧
spam=['cat', 'dogs', 'moose'] bacon=['dogs', 'moose', 'cat'] print(spam==bacon)#output:False
eggs={'name': 'Zophie','species': 'cat','age': '8'}
ham={'species': 'cat','age': '8','name': 'Zophie'}
print(eggs==ham)#output:True
列表和字典的区别还是很明显的,就像数列和集合的区别一样,列表中一个个元素不仅有自己的值还有特定的位置,而字典就像集合,只要在里面就万事大吉。--》字典是不排序的,列表是排序的。
尝试访问不在字典中的键('age'),将导致KeyError报错。
eggs={'name': 'Zophie','species': 'cat'}
print(eggs['age'])
报错信息
Traceback (most recent call last):
File "/usercode/file.py", line 29, in <module>
print(eggs['age'])
KeyError: 'age'
字典又是一个很万精油的东西,不挑,任意值都可以作为键,比如书上举例如何将好友的生日作为值,名字作为键。
birthdays={'Alice':'Apr 1','Bob':'Dec 12','Carol':'Mar 4'}
while True:
print('Enter a name :(blank to quit)')
name=input()
if name==' ':
break
if name in birthdays:
print(birthdays[name]+' is the birthday of '+name)
else:
print('I do not have birthday information for '+name)
print('What is their birthday?')
bday=input()
birthdays[name]=bday
print('Birthday database updated.')
当然,这里的数据在程序终止之后,都会丢失,具体如何保存,将在以后的笔记中提到(其实是还没看到那部分)
②keys()、values()和items()方法
有3个字典方法,他们将返回类似列表的值,分别对应字典是键、值和键-值对:keys()、values()和items()。
但是
这些方法返回的不是真正的列表,他们不能被修改,不能应用append()方法。
不过,
这些数据类型(dict_keys、dict_values和dict_items)可以用于for循环。
比如:
spam={'color':'red','age':42}
for v in spam.values():
print(v)
'''
output:
42
red
''' 这里for循环迭代了spam字典中的每个值。for循环也可以迭代每个键或者键值对:
spam={'color':'red','age':42}
for k in spam.keys():
print(k)
'''
output:
color
age
'''
for i in spam.items():
print(i)
'''
output:
('age', 42)
('color', 'red')
'''
items()方法返回的dict_items值中,包含的是键和值的元组,如果想得到真正的列表哦,就要吧类似列表的返回值传递给list()
#多重赋值
spam={'color':'red','age':42}
for k,v in spam.items():
print('Keys: '+k+' Values: '+str(v))
output:
Keys: color Values: red
Keys: age Values: 42
--------再歪一个楼---------
据说本书提供源码来着
然后给了这个网址:
https://nostarch.com/automatestuff/
具体……我刚刚打开了,有一个
下载下来的是一个
……
所以,我想说的是
……
那个,小程序的代码我就不放了
……
迅速逃走……
---------------------------------
③检查字典中是否存在键或值
法一:和列表方法类似:
键 in 字典名.keys()
值 in 字典名.values()
返回True或False
也可以采取简写形式,比如:
spam={'name':'Zophie','age':7}
'color' in spam.keys()与'color' in spam都会返回False
法二:get()方法
用于在访问某一个键的值之前,检查该键是否在字典里。
picnicItems={'apples':5,'cups':2}
print('I am bringing '+str(picnicItems.get('cups',0))+' cups.')
print('I am bringing '+str(picnicItems.get('eggs',0))+' eggs.')
'''
output:
I am bringing 2 cups.
I am bringing 0 eggs.
'''
如果不用get():
Traceback (most recent call last):
File "/usercode/file.py", line 2, in <module>
print('I am bringing '+str(picnicItems['eggs'])+' eggs.')
KeyError: 'eggs'
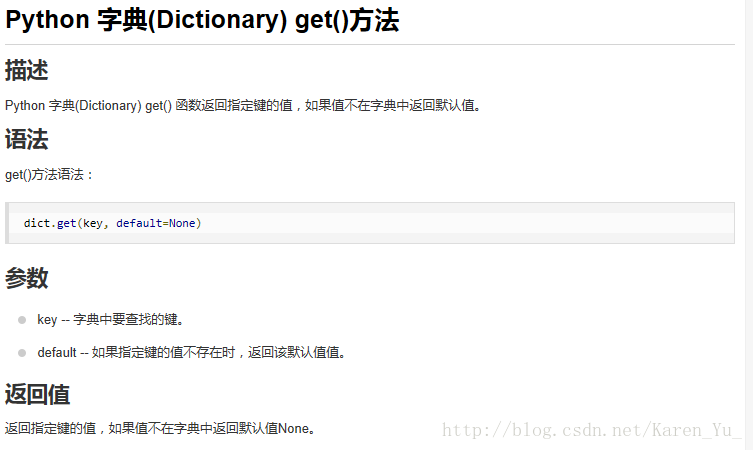
④setdefault()方法
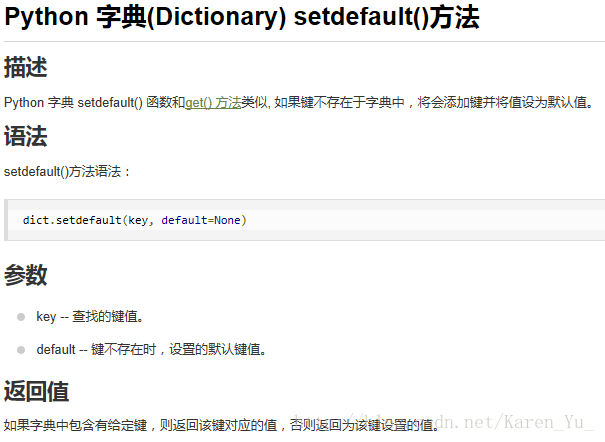
D = {'Name': 'Runoob', 'Age': 7}
print ("Age 键的值为 : %s" % D.setdefault('Age','25')) # 键存在在字典中则不会设置为指定值
print ("Sex 键的值为 : %s" % D.setdefault('Sex', 'NA')) # 键不存在,指定一个值
print ("School 键的值为 : %s" % D.setdefault('School')) # 键不存在,不指定值,默认为None
print ("新字典为:", D) 输出:
Age 键的值为 : 7
Sex 键的值为 : NA
School 键的值为 : None
新字典为: {'Name': 'Runoob', 'School': None, 'Sex': 'NA', 'Age': 7}
再比如:
'''
picnicItems={'apples':5,'cups':2}
if 'eggs' not in picnicItems:
picnicItems['eggs']=2
print(picnicItems)
'''
"""
上面的内容完全可以写作:
"""
picnicItems={'apples':5,'cups':2}
picnicItems.setdefault('eggs',2)
print(picnicItems)
picnicItems={'apples':5,'cups':2}
picnicItems.setdefault('eggs',2)
picnicItems.setdefault('eggs',3)
print(picnicItems)#output:{'apples': 5, 'cups': 2, 'eggs': 2}
'''
即使在后面更改,其实也没有什么作用,这不禁让我想到了const关键字……
'''
⑤漂亮打印
本来不想再写这个的,但是,为终于可以打印正常字典打call……
方法:
在程序中导入pprint模块,就可以使用pprint()和pformat()函数。
--------------------再歪个楼--------------------
刚刚找到疑似资料

https://docs.python.org/2/library/pprint.html
-----------------------------------------------------
import pprint
message='The amount of indentation added for each recursive level is specified by indent; the default is one. Other values can cause output to look a little odd, but can make nesting easier to spot. '
count={}
for character in message:
count.setdefault(character,0)
count[character]=count[character]+1
pprint.pprint(count)
输出:
{' ': 34,
',': 1,
'.': 2,
';': 1,
'O': 1,
'T': 1,
'a': 12,
'b': 2,
'c': 6,
'd': 9,
'e': 22,
'f': 4,
'g': 1,
'h': 4,
'i': 11,
'k': 2,
'l': 7,
'm': 2,
'n': 11,
'o': 12,
'p': 3,
'r': 5,
's': 9,
't': 16,
'u': 8,
'v': 3,
'y': 1}
如果希望打印的是字符串,可以调用pprint.pformat()
print(pprint.pformat(count))
与
pprint.pprint(count)
等价
'''
好啦,就先到这里啦ヾ(◍°∇°◍)ノ゙
'''
----------------这里是更新的分割线---------------------
from collections import Counter
string=input()
newS=''
string= ''.join(string.split())
string.replace('.','')
for s in string:
if s.isalpha():
newS+=s
s=''
s=newS.lower()
emm=[]
emm=list(s)
emm.sort()
wa=[]
wa=(Counter(emm).most_common(1))
#print(wa)
#print (wa[0][0])
#print(wa[1][0])
#tup=tuple(wa)
#print(tup)
#for x in tup:
# print(x)
stri=''
stri=str(wa)
#print(stri)
print(stri[3],stri[7])
之前提过这道题,然后,这个代码……通过的概率……是不确定的……
绝对不是我的问题……